Massive Language Fashions (LLMs) have emerged as essential instruments for dealing with intricate information-seeking queries as a consequence of methods that enhance each retrieval and response era. Retrieval-augmented era (RAG) is a well known framework on this space that has drawn plenty of curiosity since it could produce responses which can be extra correct and pertinent to the context. In RAG programs, an LLM creates a response based mostly on the recovered content material after a retrieval step wherein pertinent data or passages are gathered. By connecting feedback to explicit passages, this association allows LLMs to quote sources, which helps decrease false data or hallucinations and makes verification less complicated and extra reliable.
One well-known RAG system is Microsoft’s Bing Search, which improves response reliability to the referred content material by incorporating retrieval and grounding methods to quote sources. Nevertheless, due to unequal entry to high-quality coaching information in non-English languages, present RAG fashions are principally targeted on English, which limits their usefulness in multilingual environments. The effectiveness of LLMs in multilingual RAG settings, the place each the questions and the solutions are in languages aside from English, akin to Hindi, continues to be unknown.
There are two main varieties of benchmarks used to evaluate RAG programs. The preliminary, heuristic-based benchmarks consider fashions in quite a lot of dimensions utilizing a mix of computational measures. Regardless of being fairly priced, these requirements nonetheless depend on human tastes as a gold reality for comparability, and it could be tough to find out a transparent rating between fashions.
The second type, referred to as arena-based benchmarks, makes use of a high-performance LLM as a trainer to judge mannequin outputs by direct mannequin comparisons in a setting akin to a contest. Nevertheless, this technique could be pricey and computationally demanding, particularly when evaluating numerous fashions in-depth, as is the case when evaluating 19 fashions utilizing OpenAI’s GPT-4o, which could be very pricey.
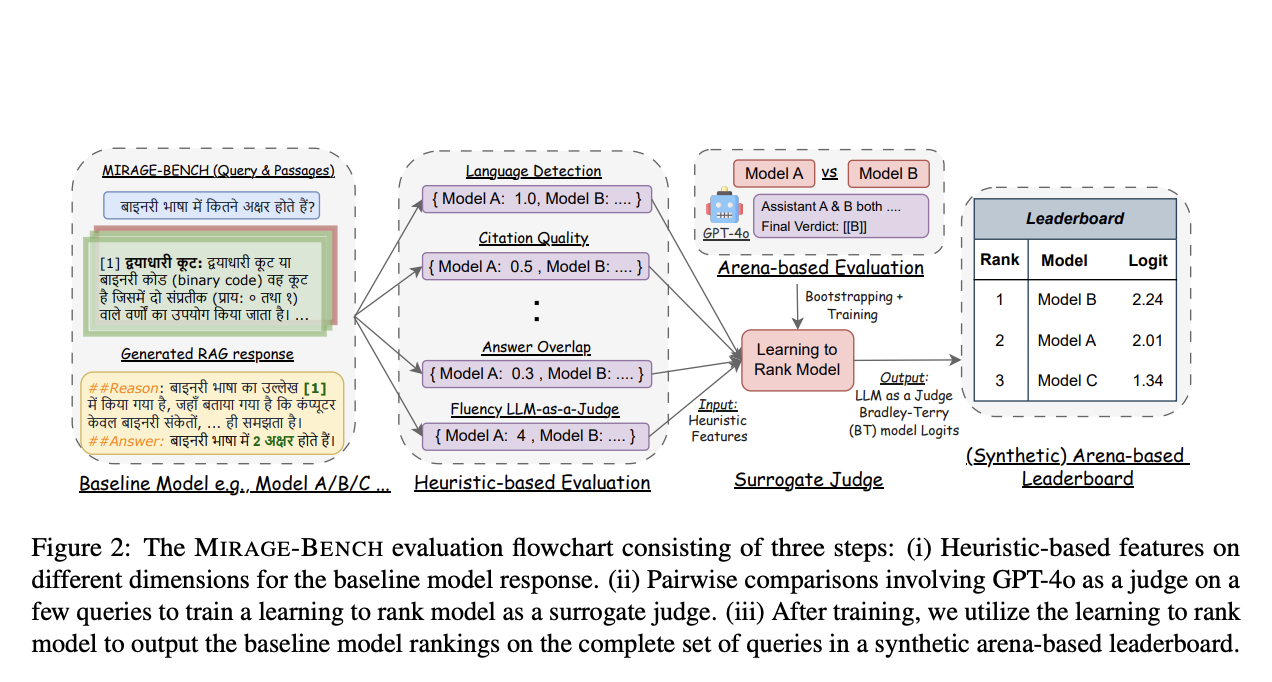
A staff of researchers from the College of Waterloo and VECTARA suggest a brand new framework referred to as MIRAGE-BENCH to resolve the constraints of each approaches. It makes use of a extra economical technique to research multilingual era throughout 18 languages. This distinctive benchmark has been created by using a retrieval dataset referred to as MIRACL, which incorporates pertinent Wikipedia sections for coaching in addition to human-curated questions. MIRAGE-BENCH makes use of seven important heuristic components, together with fluency, quotation high quality, and language detection, amongst others, to evaluate the caliber and applicability of responses produced by LLM. GPT-4o judges a smaller pattern of multilingual inquiries in conditions the place extra correct assessments are required.
In an effort to operate as a surrogate decide, MIRAGE-BENCH additionally incorporates Machine Studying methods by constructing a random forest mannequin. Heuristic traits and the Bradley-Terry mannequin, a statistical method incessantly utilized in rating, are used to coach this learning-to-rank mannequin. With out requiring a pricey LLM decide every time, the educated machine can then produce an artificial leaderboard for scoring multilingual LLMs. Along with saving cash, this process allows the leaderboard to regulate to new or altered analysis requirements. The staff has shared that in line with experimental information, MIRAGE-BENCH’s methodology often locations large-scale fashions on the high and carefully matches the dear GPT-4o-based leaderboards, acquiring a excessive correlation rating.
By utilizing information generated below the path of high-performing fashions like GPT-4o, MIRAGE-BENCH has been demonstrated to be advantageous for smaller LLMs, akin to ones with 7-8 billion parameters. The effectivity and scalability of multilingual RAG benchmarks are ultimately improved by this surrogate analysis methodology, opening the door for extra thorough and inclusive evaluations of LLMs in a wide range of languages.
The staff has shared their main contributions as follows.
- The institution of MIRAGE-BENCH, which is a benchmark created particularly to advertise multilingual RAG analysis and helps in multilingual improvement.
- A trainable learning-to-rank mannequin has been used as a surrogate decide to mix heuristic-based measures with an arena-style leaderboard, efficiently hanging a steadiness between computing effectivity and accuracy.
- The benefits and downsides of 19 multilingual LLMs have been mentioned by way of their era capacities in multilingual RAG.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to hitch our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Fantastic-Tuned Fashions: Predibase Inference Engine (Promoted)
Tanya Malhotra is a closing yr undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Laptop Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Information Science fanatic with good analytical and important considering, together with an ardent curiosity in buying new abilities, main teams, and managing work in an organized method.


