
Language Fashions (LMs) have considerably superior advanced NLP duties via subtle prompting strategies and multi-stage pipelines. Nonetheless, designing these LM Applications depends closely on guide “immediate engineering,” a time-consuming means of crafting prolonged prompts via trial and error. This strategy faces challenges, significantly in multi-stage LM packages the place gold labels or analysis metrics for particular person LM calls are sometimes missing. The absence of those metrics makes it troublesome to evaluate and optimize every stage independently, hindering the general effectivity and effectiveness of LM packages. In consequence, there’s a urgent want for extra systematic and automatic approaches to optimize multi-stage LM pipelines.
Numerous approaches have been launched to optimize LM packages, together with gradient-guided search, reranking brute drive search, evolutionary algorithms, and prompting different LMs. Some research explored reinforcement studying for immediate optimization, specializing in word-level or phrase-level edits. Notable makes an attempt embrace DSPy, which launched a programming mannequin for expressing and optimizing LM packages, and an strategy modeling joint immediate optimization for stacked LLM calls as variational inference. Nonetheless, these strategies usually fall brief in addressing the complexities of multi-stage LM packages, significantly when coping with arbitrary numbers of modules and various LM architectures. Present approaches are restricted by their concentrate on particular kinds of edits, reliance on log chances, or incapability to optimize free-form directions for classy multi-prompt pipelines. This leaves a spot for a extra versatile and complete optimization strategy that may deal with advanced, multi-stage LM pipelines with out restrictive assumptions.
The researchers suggest a sturdy strategy to optimize prompts for LM packages, specializing in maximizing downstream metrics with out requiring module-level labels or gradients. Their technique, known as MIPRO, factorizes the optimization downside into refining free-form directions and few-shot demonstrations for every module within the LM program. MIPRO employs a number of modern methods to overccome the challenges of immediate optimization in multi-stage pipelines. These embrace program- and data-aware strategies for producing efficient directions, a stochastic mini-batch analysis perform to study a surrogate mannequin of the target and a meta-optimization process that improves the LM’s proposal building over time. This complete strategy permits MIPRO to navigate the complexities of credit score task throughout modules and craft task-grounded directions.
The researchers current an in depth structure for optimizing multi-stage LM packages, MIPRO. This technique focuses on optimizing free-form directions and few-shot demonstrations for every module in this system. It addresses key challenges via a number of modern methods. For the proposal downside, it employs bootstrapping demonstrations, grounding strategies, and studying to suggest. These approaches assist generate task-relevant directions and demonstrations. For credit score task throughout modules, MIPRO explores grasping, surrogate, and history-based strategies. The surrogate mannequin makes use of a Bayesian strategy to foretell the standard of variable mixtures, whereas the history-based technique makes use of previous evaluations to tell future proposals. It additionally incorporates a stochastic mini-batch analysis perform and a meta-optimization process to refine proposal technology over time. This complete structure permits MIPRO to effectively navigate the advanced optimization panorama of multi-stage LM packages.
The outcomes of the MIPRO optimization strategy reveal a number of key insights. Optimizing bootstrapped demonstrations as few-shot examples proved essential for reaching the most effective efficiency in most duties. MIPRO, which optimizes each directions and few-shot examples, usually yielded the most effective general efficiency throughout duties. Instruction optimization was discovered to be significantly essential for duties with conditional guidelines that aren’t instantly apparent to the LM and aren’t simply expressed via a restricted variety of few-shot examples. Grounding strategies had been usually useful for instruction proposals, though the most effective proposal technique different by process.
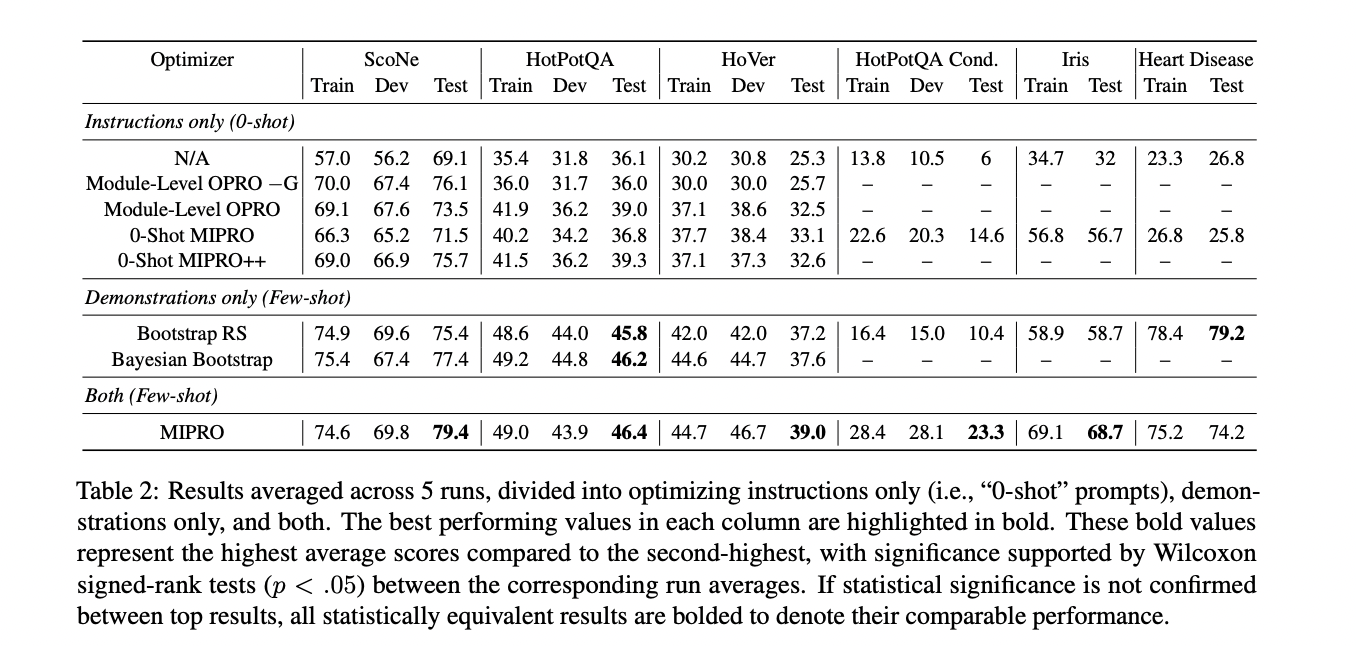
This examine formalizes LM program optimization as a immediate search downside, addressing the challenges of proposal technology and credit score task. By exploring varied methods for various duties, the analysis demonstrates that optimizing few-shot demonstrations is extremely efficient, whereas instruction optimization is essential for advanced duties. The examine in the end finds that collectively optimizing each demonstrations and directions yields the most effective outcomes, paving the way in which for extra environment friendly and highly effective multi-stage LM packages.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular knowledge with the primary compound AI system, Gretel Navigator, now usually obtainable! [Advertisement]
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


