
Within the ever-evolving discipline of computational linguistics, the hunt for fashions that may seamlessly generate human-like textual content has led researchers to discover revolutionary methods past conventional frameworks. Some of the promising avenues in latest instances has been the exploration of diffusion fashions, beforehand lauded for his or her success in visible and auditory domains and their potential in pure language era (NLG). These fashions have opened up new potentialities for creating textual content that isn’t solely contextually related and coherent however displays a exceptional diploma of variability and adaptiveness to totally different kinds and tones, a hurdle many earlier strategies struggled to beat effectively.
Earlier textual content era strategies typically wanted to work on producing content material that would adapt to numerous necessities with out in depth retraining or handbook interventions. This problem was significantly pronounced in purposes requiring excessive versatility, comparable to dynamic content material creation for web sites or customized dialogue techniques, the place the context and elegance might shift quickly.
Diffusion fashions have emerged as a beacon of hope on this panorama, celebrated for his or her capacity to refine outputs in direction of high-quality options iteratively. Their software in NLG, nonetheless, has but to be easy, primarily because of the discrete nature of language. This discreteness complicates the diffusion course of, which depends on gradual transformations, making it a much less intuitive match for textual content than pictures or audio.
Researchers from Peking College and Microsoft Company launched TREC (Text Reinforced Conditioning), a novel Textual content Diffusion mannequin devised to bridge this hole. It targets the particular challenges posed by the discrete nature of textual content, aiming to leverage the iterative refinement prowess of diffusion fashions to boost textual content era. TREC introduces Bolstered Conditioning, a method designed to fight self-conditioning degradation famous throughout coaching. This degradation typically ends in fashions that fail to totally make the most of the iterative refinement potential of diffusion, relying too closely on the standard of preliminary steps and thereby limiting the mannequin’s effectiveness.
TREC employs Time-Conscious Variance Scaling, an revolutionary method to align the coaching and sampling processes extra carefully. This alignment is essential for sustaining consistency within the mannequin’s output high quality, making certain that the refinement course of throughout sampling displays the circumstances underneath which the mannequin was skilled. TREC considerably enhances the mannequin’s capacity to provide high-quality, contextually related textual content sequences by addressing these two crucial points.
The efficacy of TREC has been rigorously examined throughout a spectrum of NLG duties, together with machine translation, paraphrasing, and query era. The outcomes are nothing in need of spectacular, with TREC not solely holding its floor towards each autoregressive and non-autoregressive baselines but in addition outperforming them in a number of cases. This efficiency underscores TREC‘s capacity to harness the complete potential of diffusion processes for textual content era, providing vital enhancements within the high quality and contextual relevance of the generated textual content.
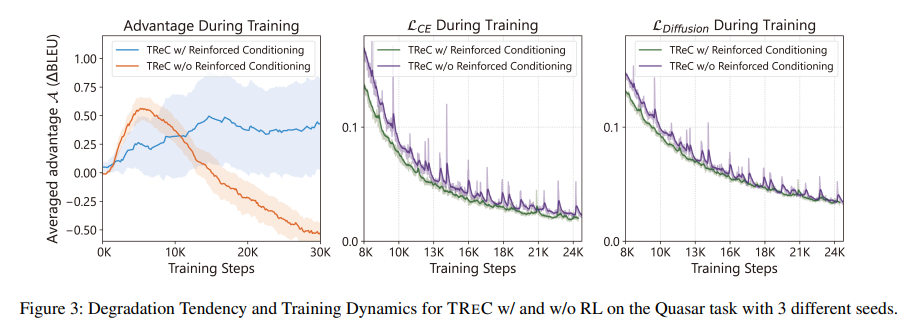
What units TREC aside is its novel methodology and the tangible outcomes it achieves. In machine translation, TREC has demonstrated its superiority by delivering extra correct and nuanced translations than these produced by established fashions. In paraphrasing and query era duties, TREC‘s outputs are various and contextually apt, showcasing a stage of adaptability and coherence that marks a big development in NLG.
In conclusion, TRECs improvement is a landmark achievement in pursuing fashions able to producing human-like textual content. By addressing the intrinsic challenges of textual content diffusion fashions, particularly, the degradation throughout coaching and misalignment throughout sampling, TREC units a brand new commonplace for textual content era and opens up new avenues for analysis and software in computational linguistics. Its success throughout numerous NLG duties illustrates the mannequin’s robustness and flexibility, heralding a future the place machines can generate textual content that’s indistinguishable from that written by people, tailor-made to an array of kinds, tones, and contexts. This breakthrough is a testomony to the ingenuity and forward-thinking of the researchers behind TREC, providing a glimpse into the way forward for synthetic intelligence in language era.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
You may additionally like our FREE AI Programs….
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


