
Textual content embedding, a central focus inside pure language processing (NLP), transforms textual content into numerical vectors capturing the important which means of phrases or phrases. These embeddings allow machines to course of language duties like classification, clustering, retrieval, and summarization. By structuring information in vector kind, embeddings present a scalable and efficient manner for machines to interpret and act on human language, enhancing machine understanding in functions starting from sentiment evaluation to advice methods.
A major problem in textual content embedding is producing the huge portions of high-quality coaching information wanted to develop sturdy fashions. Manually labeling giant datasets is dear and time-intensive, and whereas artificial information technology provides a possible resolution, many approaches rely closely on proprietary language fashions akin to GPT-4. These strategies, although efficient, pose a considerable price barrier because of the intensive assets wanted to function large-scale fashions, making superior embedding applied sciences inaccessible to a broader analysis group and limiting alternatives to refine and adapt embedding strategies.
Most present strategies for creating coaching information for embedding fashions depend on proprietary giant language fashions (LLMs) to generate artificial textual content. For instance, GPT-4 generates triplets—a question paired with optimistic and arduous damaging paperwork—to supply numerous, contextually wealthy examples. This strategy, whereas highly effective, comes with excessive computational prices and infrequently includes black-box fashions, which restricts researchers’ potential to optimize and adapt the method to their particular wants. Such reliance on proprietary fashions can restrict scalability and effectivity, highlighting the necessity for progressive, resource-conscious alternate options that preserve information high quality with out extreme prices.
Researchers from the Gaoling Faculty of Synthetic Intelligence and Microsoft Company have launched a novel framework known as SPEED. This strategy leverages small, open-source fashions to generate high-quality embedding information whereas considerably decreasing useful resource calls for. By changing costly proprietary fashions with an environment friendly, open-source different, SPEED goals to democratize entry to scalable artificial information technology. This framework is designed to supply information for coaching high-performing textual content embeddings whereas utilizing lower than a tenth of the API calls required by typical proprietary LLMs.
SPEED operates by a structured alignment pipeline comprising three main parts: a junior generator, a senior generator, and a knowledge revisor. The method begins with activity brainstorming and seed information technology, the place GPT-4 is employed to develop numerous activity descriptions. These descriptions kind a foundational set of directions, offering the junior generator mannequin with supervised fine-tuning to supply preliminary, low-cost artificial information. The information generated by the junior mannequin is then processed by the senior generator, which makes use of choice optimization to reinforce high quality primarily based on analysis alerts supplied by GPT-4. Within the last stage, the info revisor mannequin refines these outputs, addressing any inconsistencies or high quality points and additional bettering the alignment and high quality of the generated information. This course of permits SPEED to synthesize information effectively and aligns small, open-source fashions with the duty necessities historically dealt with by bigger, proprietary fashions.
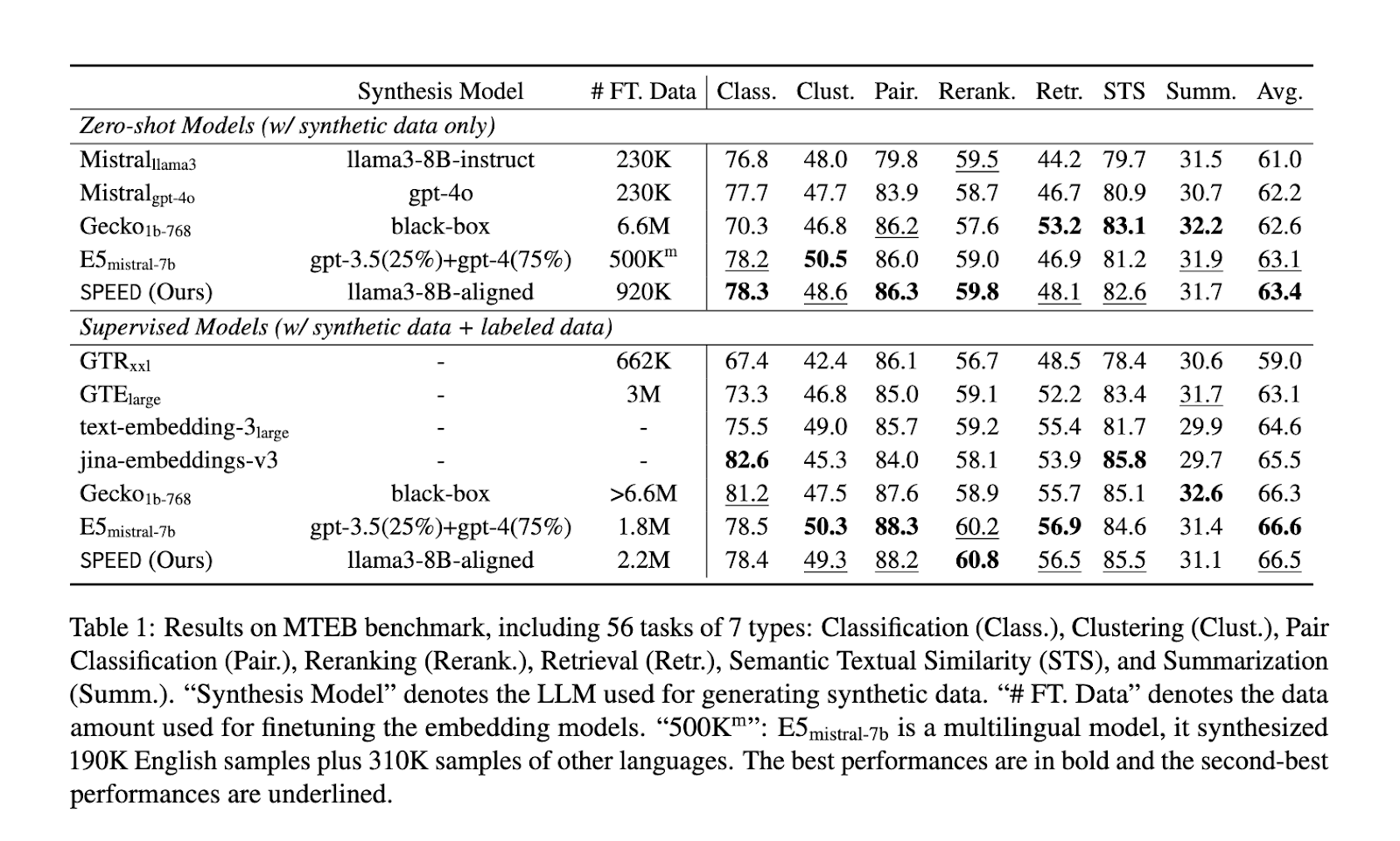
The outcomes from SPEED display important developments in embedding high quality, cost-efficiency, and scalability. SPEED outperformed the main embedding mannequin, E5mistral, with considerably fewer assets. SPEED achieved this through the use of simply 45,000 API calls, in comparison with E5mistral’s 500,000, representing a value discount of greater than 90%. On the Huge Textual content Embedding Benchmark (MTEB), SPEED confirmed a median efficiency of 63.4 throughout duties, together with classification, clustering, retrieval, and pair classification, underscoring the mannequin’s excessive versatility and high quality. SPEED achieved superior outcomes throughout numerous benchmarks and activity sorts in zero-shot settings, carefully matching the efficiency of proprietary, high-resource fashions regardless of its low-cost construction. For instance, SPEED’s efficiency reached 78.4 in classification duties, 49.3 in clustering, 88.2 in pair classification, 60.8 in reranking, 56.5 in retrieval, 85.5 in semantic textual similarity, and 31.1 in summarization, putting it competitively throughout all classes.
The SPEED framework provides a sensible, cost-effective different for the NLP group. By reaching high-quality information synthesis at a fraction of the fee, researchers could be supplied with an environment friendly, scalable, and accessible technique for coaching embedding fashions with out counting on high-cost, proprietary applied sciences. SPEED’s alignment and choice optimization strategies illustrate the feasibility of coaching small, open-source fashions to satisfy the advanced calls for of artificial information technology, making this strategy a useful useful resource for advancing embedding know-how and facilitating broader entry to classy NLP instruments.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Positive-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


