
LLMs, pretrained on intensive textual information, exhibit spectacular capabilities in generative and discriminative duties. Latest curiosity focuses on using LLMs for multimodal duties, integrating them with visible encoders for duties like captioning, query answering, classification, and segmentation. Nonetheless, prior multimodal fashions face limitations in dealing with video inputs because of the context size restriction of LLMs and GPU reminiscence constraints. For example, whereas fashions like LLaMA have a context restrict of 2048, others like LLaVA and BLIP-2 course of solely 256 and 32 tokens per picture, respectively. This restricts their practicality for longer video durations equivalent to motion pictures or TV reveals.
A easy answer like common pooling alongside the temporal axis, as utilized in VideoChatGPT, results in inferior efficiency because of the absence of express temporal modeling. One other strategy, as seen in Video-LLaMA, entails including a video modeling part, equivalent to an additional video querying transformer (Q-Former), to seize temporal dynamics and procure video-level illustration. Nonetheless, this methodology will increase mannequin complexity, provides coaching parameters, and is unsuitable for on-line video evaluation.
Researchers from the College of Maryland, Meta, and Central Florida suggest a Reminiscence-Augmented Massive Multimodal Mannequin (MA-LMM) for environment friendly long-term video modeling. It follows the construction of present multimodal fashions, that includes a visible encoder, a querying transformer, and a big language mannequin. In contrast to earlier strategies, MA-LMM adopts a web-based processing strategy, sequentially processing video frames and storing options in a long-term reminiscence financial institution. This technique considerably reduces GPU reminiscence utilization for lengthy video sequences and successfully addresses context size limitations in LLMs. MA-LMM affords benefits over prior approaches, which devour substantial GPU reminiscence and enter textual content tokens.
The MA-LLM mannequin structure contains three predominant elements: (1) visible function extraction utilizing a frozen visible encoder, (2) long-term temporal modeling using a trainable querying transformer (Q-Former) to align visible and textual content embeddings, and (3) textual content decoding with a frozen massive language mannequin. Frames are processed sequentially, associating new inputs with historic information in a long-term reminiscence financial institution to retain discriminative data effectively. The querying transformer integrates visible and textual data, whereas a compression approach reduces reminiscence financial institution dimension with out shedding discriminative options. Lastly, the mannequin decodes textual content utilizing the Q-Former output, addressing context size limitations and decreasing GPU reminiscence necessities throughout coaching.
MA-LMM demonstrates superior efficiency throughout numerous duties in comparison with earlier state-of-the-art strategies. It outperforms present fashions in long-term video understanding, video query answering, video captioning, and on-line motion prediction duties. MA-LMM’s revolutionary design, using a long-term reminiscence financial institution and sequential processing, allows environment friendly dealing with of lengthy video sequences and achieves exceptional outcomes even in difficult situations. These findings show the effectiveness and flexibility of MA-LMM in multimodal video understanding functions.
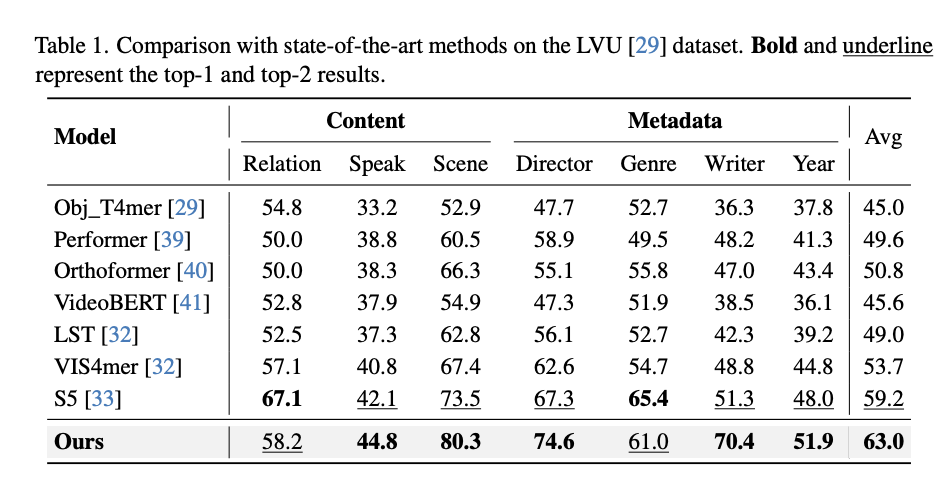
To conclude, this analysis introduces a long-term reminiscence financial institution to reinforce present massive multimodal fashions, MA-LLM, for successfully modeling lengthy video sequences. This strategy addresses context size limitations and GPU reminiscence constraints inherent in LLMs by processing video frames sequentially and storing historic information. As demonstrated in experiments, the long-term reminiscence financial institution is definitely built-in into present fashions and reveals superior benefits throughout numerous duties.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to affix our 40k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


