
Analysis on Multimodal giant language fashions (MLLMs) focuses on integrating visible and textual information to reinforce synthetic intelligence’s reasoning capabilities. By combining these modalities, MLLMs can interpret advanced data from numerous sources similar to pictures and textual content, enabling them to carry out duties like visible query answering and mathematical problem-solving with better accuracy and perception. This interdisciplinary method leverages the strengths of each visible and linguistic information, aiming to create extra sturdy AI techniques able to understanding and interacting with the world like people.
A big problem in creating efficient MLLMs is their lack of ability to unravel advanced mathematical issues involving visible content material. Regardless of their proficiency in textual mathematical problem-solving, these fashions typically want to enhance when deciphering and reasoning via visible data. This hole highlights the necessity for improved datasets and methodologies that higher combine multimodal information. Researchers attempt to create fashions that may perceive textual content and derive significant insights from pictures, diagrams, and different visible aids essential in fields like training, science, and know-how.
Current strategies to reinforce MLLMs’ mathematical reasoning embrace immediate and fine-tuning approaches. Immediate strategies leverage the fashions’ latent talents via rigorously crafted prompts, whereas fine-tuning strategies modify the mannequin parameters utilizing reasoning information from real-world or artificial sources. Nonetheless, present open-source picture instruction datasets are restricted in scope, containing few question-answer pairs per picture, which restricts the fashions’ potential to take advantage of visible data absolutely. The restrictions of those datasets impede the event of MLLMs, necessitating the creation of extra complete and numerous datasets to coach these fashions successfully.
Researchers from establishments together with the College of Digital Science and Know-how of China, Singapore College of Know-how and Design, Tongji College, and the Nationwide College of Singapore launched Math-LLaVA, a mannequin fine-tuned with a novel dataset known as MathV360K. This dataset consists of 40K high-quality pictures and 320K synthesized question-answer pairs designed to enhance the breadth and depth of multimodal mathematical reasoning capabilities. Introducing Math-LLaVA represents a major step ahead within the subject, addressing the gaps left by earlier datasets and strategies.
The MathV360K dataset was constructed by choosing 40K high-quality pictures from 24 pre-existing datasets, specializing in topics like algebra, geometry, and visible query answering. Researchers synthesized 320K new question-answer pairs primarily based on these pictures to reinforce the range and complexity of the dataset. This complete dataset was then used to fine-tune the LLaVA-1.5 mannequin, ensuing within the growth of Math-LLaVA. The choice course of for these pictures concerned rigorous standards to make sure readability and complexity, aiming to cowl a variety of mathematical ideas and query varieties. The synthesis of extra question-answer pairs concerned producing numerous questions that probe completely different facets of the pictures and require a number of reasoning steps, additional enhancing the dataset’s robustness.
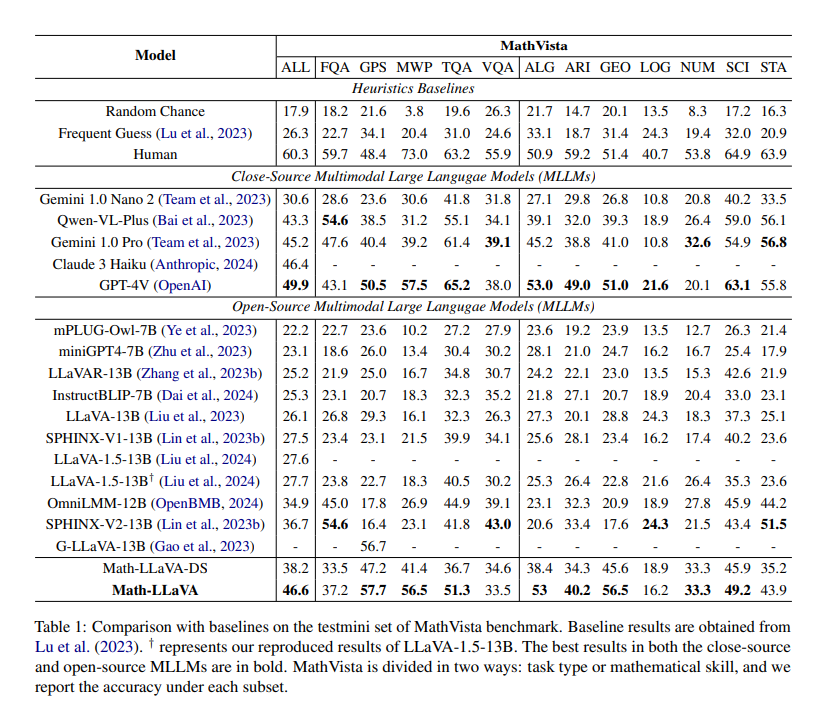
Math-LLaVA demonstrated vital enhancements, attaining a 19-point enhance on the MathVista minutest cut up in comparison with the unique LLaVA-1.5 mannequin. Moreover, it confirmed enhanced generalizability and carried out effectively on the MMMU benchmark. Particularly, Math-LLaVA achieved a 57.7% accuracy on the GPS subset, outperforming G-LLaVA-13B, educated on 170K high-quality geometric image-caption and question-answer pairs. These outcomes spotlight the effectiveness of the varied and complete MathV360K dataset in enhancing the multimodal mathematical reasoning capabilities of MLLMs. The mannequin’s efficiency on completely different benchmarks underscores its potential to generalize throughout varied mathematical reasoning duties, making it a invaluable software for a variety of purposes.
To conclude, the analysis underscores the essential want for high-quality, numerous multimodal datasets to enhance mathematical reasoning in MLLMs. By creating and fine-tuning Math-LLaVA with MathV360K, researchers have considerably enhanced the mannequin’s efficiency and generalizability, showcasing the significance of dataset variety and synthesis in advancing AI capabilities. The MathV360K dataset and the Math-LLaVA mannequin characterize a considerable development within the subject, offering a strong framework for future analysis and growth. This work not solely underscores the potential of MLLMs to remodel varied domains by integrating visible and textual information but additionally conjures up hope for the way forward for AI, paving the way in which for extra refined and succesful AI techniques.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 45k+ ML SubReddit
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


