
Language fashions have develop into a cornerstone of recent NLP, enabling important developments in varied purposes, together with textual content technology, machine translation, and question-answering techniques. Current analysis has targeted on scaling these fashions by way of the quantity of coaching information and the variety of parameters. These scaling legal guidelines have demonstrated that growing information and mannequin parameters yields substantial efficiency enhancements. Nevertheless, a brand new scaling dimension is now being explored: the scale of exterior information shops accessible at inference time. In contrast to conventional parametric fashions, which rely solely on the coaching information, retrieval-based language fashions can dynamically entry a a lot bigger information base throughout inference, enhancing their capability to generate extra correct and contextually related responses. This novel strategy of integrating huge datastores opens new potentialities for effectively managing information and bettering the factual accuracy of LMs.
One main problem in NLP is retaining and using huge information with out incurring important computational prices. Conventional language fashions are sometimes skilled on massive static datasets encoded into the mannequin parameters. As soon as skilled, these fashions can not combine new info dynamically and require pricey retraining to replace their information base. That is notably problematic for knowledge-intensive duties, the place fashions must reference intensive exterior sources. The issue is exacerbated when these fashions are required to deal with numerous domains resembling common net information, scientific papers, and technical codes. The lack to adapt dynamically to new info and the computational burden related to retraining restrict the effectiveness of those fashions. Thus, a brand new paradigm is required to allow language fashions to dynamically entry and use exterior information.
Present approaches for enhancing language fashions’ capabilities embrace utilizing retrieval-based mechanisms that depend on exterior datastores. These fashions, often called retrieval-based language fashions (RIC-LMs), can entry further context throughout inference by querying an exterior datastore. This technique contrasts with parametric fashions, constrained by the information embedded inside their parameters. Notable efforts embrace using Wikipedia-sized datastores with a couple of billion tokens. Nevertheless, these datastores are sometimes domain-specific and don’t cowl the complete breadth of knowledge required for advanced downstream duties. Moreover, earlier retrieval-based fashions have computational feasibility and effectivity limitations, as large-scale datastores introduce challenges in sustaining retrieval velocity and accuracy. Though some fashions like RETRO have used proprietary datastores, their outcomes haven’t been totally replicable because of the closed nature of the datasets.
A analysis workforce from the College of Washington and the Allen Institute for AI constructed a brand new datastore known as MassiveDS, which includes 1.4 trillion tokens. This open-source datastore is the biggest and most numerous accessible for retrieval-based LMs. It consists of information from eight domains: books, scientific papers, Wikipedia articles, GitHub repositories, and mathematical texts. MassiveDS was particularly designed to facilitate large-scale retrieval throughout inference, enabling language fashions to entry and make the most of extra info than ever earlier than. The researchers applied an environment friendly pipeline that reduces the computational overhead related to datastore scaling. This pipeline permits for systematic analysis of datastore scaling developments by retrieving a subset of paperwork and making use of operations resembling indexing, filtering, and subsampling solely to those subsets, making the development and utilization of enormous datastores computationally accessible.
The analysis demonstrated that MassiveDS considerably improves the efficiency of retrieval-based language fashions. For instance, a smaller LM using this datastore outperformed a bigger parametric LM on a number of downstream duties. Particularly, MassiveDS fashions achieved decrease perplexity scores on common net and scientific information, indicating greater language modeling high quality. Moreover, in knowledge-intensive question-answering duties resembling TriviaQA and Pure Questions, the LMs utilizing MassiveDS constantly outperformed their bigger counterparts. On TriviaQA, fashions with entry to lower than 100 billion tokens from MassiveDS may surpass the efficiency of a lot bigger language fashions that didn’t make the most of exterior datastores. These findings recommend that growing the datastore dimension permits fashions to carry out higher with out bettering their inner parameters, thereby lowering the general coaching price.
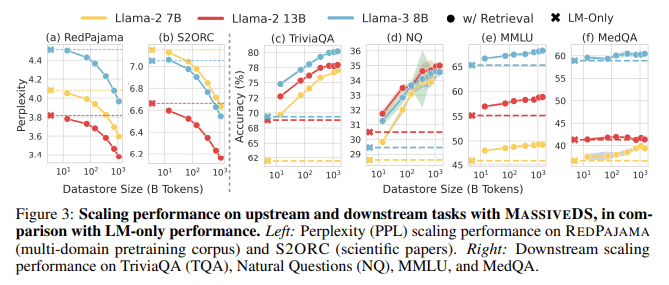
The researchers attribute these efficiency good points to MassiveDS’s capability to supply high-quality, domain-specific info throughout inference. Even for reasoning-heavy duties resembling MMLU and MedQA, retrieval-based LMs utilizing MassiveDS confirmed notable enhancements in comparison with parametric fashions. Utilizing a number of information sources ensures the datastore can present related context for varied queries, making the language fashions extra versatile and efficient throughout totally different domains. The outcomes spotlight the significance of utilizing information high quality filters and optimized retrieval strategies, additional enhancing the advantages of datastore scaling.

In conclusion, this research demonstrates that retrieval-based language fashions geared up with a big datastore like MassiveDS can carry out higher at a decrease computational price than conventional parametric fashions. By leveraging an expansive 1.4 trillion-token datastore, these fashions can dynamically entry numerous, high-quality info, considerably bettering their capability to deal with knowledge-intensive duties. This represents a promising path for future analysis, providing a scalable and environment friendly methodology to reinforce language fashions’ efficiency with out growing the mannequin dimension or coaching price.
Take a look at the Paper, Dataset, GitHub, and Challenge. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report can be launched in late October/early November 2024. Click on right here to arrange a name!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


