
Giant language fashions (LLMs) and picture turbines face a crucial problem referred to as mannequin collapse. This phenomenon happens when the efficiency of those AI programs deteriorates as a result of growing presence of AI-generated information of their coaching datasets. As generative AI evolves, proof means that retraining fashions on their outputs can result in numerous anomalies in subsequent generations. In LLMs, this course of introduces irreparable defects, ensuing within the manufacturing of nonsensical or gibberish output. Whereas current research have demonstrated facets of mannequin collapse empirically in numerous settings, a complete theoretical understanding of this phenomenon stays elusive. Researchers are actually grappling with the pressing want to handle this difficulty to make sure the continued development and reliability of generative AI applied sciences.
Researchers have made a number of makes an attempt to handle the challenges of mannequin collapse in massive language fashions and picture turbines. Present LLMs and diffusion fashions are skilled on predominantly human-generated textual content and web-scale picture datasets, probably exhausting all accessible clear information on the web. As artificial information generated by these fashions turns into more and more prevalent, current works have empirically demonstrated numerous facets of mannequin collapse in several settings.
Theoretical approaches to research the impact of iterative coaching on self-generated or combined information have emerged. These embody research on bias amplification in data-feedback loops, evaluation of finite sampling bias and performance approximation errors in Gaussian circumstances, and exploration of “self-consuming loops” in imaginative and prescient fashions. Some researchers have investigated eventualities involving clear and synthesized information, revealing {that a} sufficiently excessive proportion of fresh information may help preserve the generator’s means to precisely replicate the true information distribution.
It’s essential to notice that the mannequin collapse phenomenon differs from self-distillation, which may enhance mannequin efficiency via managed information era processes. In distinction, mannequin collapse happens when there isn’t a management over the info era course of, because it entails synthesized information from numerous sources on the internet.
Researchers from Meta FAIR, Heart for Information Science, New York College, and Courant Institute, New York College, introduce a theoretical framework to research mannequin collapse within the context of high-dimensional supervised studying with kernel regression. Kernel strategies, regardless of their simplicity, provide a robust strategy for capturing non-linear options whereas remaining inside the area of convex optimization. These strategies have not too long ago gained renewed consideration as proxies for neural networks in numerous regimes, together with the infinite-width restrict and the lazy coaching regime.
The proposed theoretical framework builds upon current analysis on power-law generalization errors in regularized least-squares kernel algorithms. It considers the power-decay spectrum of the kernel (capability) and the coefficients of the goal operate (supply), which have been proven to provide rise to power-law scaling of take a look at errors by way of dataset measurement and mannequin capability. This strategy aligns with empirically noticed scaling legal guidelines in massive language fashions and different AI programs.
By using insights from Gaussian design research and random function fashions, this theoretical examine goals to supply a complete understanding of mannequin collapse. The framework incorporates parts from nonparametric literature, spectral evaluation, and deep neural community error scaling to create a strong basis for investigating the mechanisms underlying mannequin collapse in kernel regression settings.
This theoretical examine on mannequin collapse in kernel regression settings provides a number of key contributions:
1. A precise characterization of take a look at error below iterative retraining on synthesized information is offered. The researchers derive an analytic components that decomposes the take a look at error into three parts: the error from clear information coaching, a rise in bias as a consequence of artificial information era, and a scaling issue that grows with every iteration of information era.
2. The examine reveals that because the variety of generations of artificial information will increase, studying turns into unattainable as a result of compounding results of re-synthesizing information.
3. For power-law spectra of the covariance matrix, the researchers set up new scaling legal guidelines that quantitatively show the detrimental impression of coaching on synthetically generated information.
4. The examine proposes an optimum ridge regularization parameter that corrects the worth recommended in classical principle for clear information. This correction adapts to the presence of synthesized information within the coaching set.
5. A uniquel crossover phenomenon is recognized the place the suitable tuning of the regularization parameter can mitigate the results of coaching on faux information, transitioning from a quick error price within the noiseless regime to a slower price depending on the quantity of true information used within the preliminary faux information era.
These findings present a complete theoretical framework for understanding and probably mitigating the results of mannequin collapse in kernel regression settings, providing insights that might be useful for enhancing the robustness of huge language fashions and different AI programs.
This framework for analyzing mannequin collapse in kernel regression settings is constructed upon a rigorously constructed setup that balances analytical tractability with the flexibility to exhibit a variety of phenomena. The core of this framework is a knowledge distribution mannequin PΣ,w0,σ2 , the place inputs x are drawn from a multivariate Gaussian distribution N(0, Σ), and labels y are generated by a linear floor reality operate with added noise.
The examine introduces a faux information era course of that iteratively creates new fashions. Ranging from the unique distribution PΣ,w0,σ2
0, every subsequent era PΣ,wbn,σ2
n is created by becoming a mannequin on information sampled from the earlier era. This course of simulates the impact of coaching on more and more artificial information.
The downstream mannequin, which is the main target of the evaluation, is a ridge regression predictor wb
pred n. This predictor is skilled on information from the nth era of the faux information distribution however evaluated on the true information distribution. The researchers look at the dynamics of the take a look at error Etest(wb
pred n) because the variety of generations n will increase.
Whereas the framework is offered by way of linear regression for readability, the authors observe that it may be prolonged to kernel strategies. This extension entails changing the enter x with a function map induced by a kernel Okay, permitting the framework to seize non-linear relationships within the information.
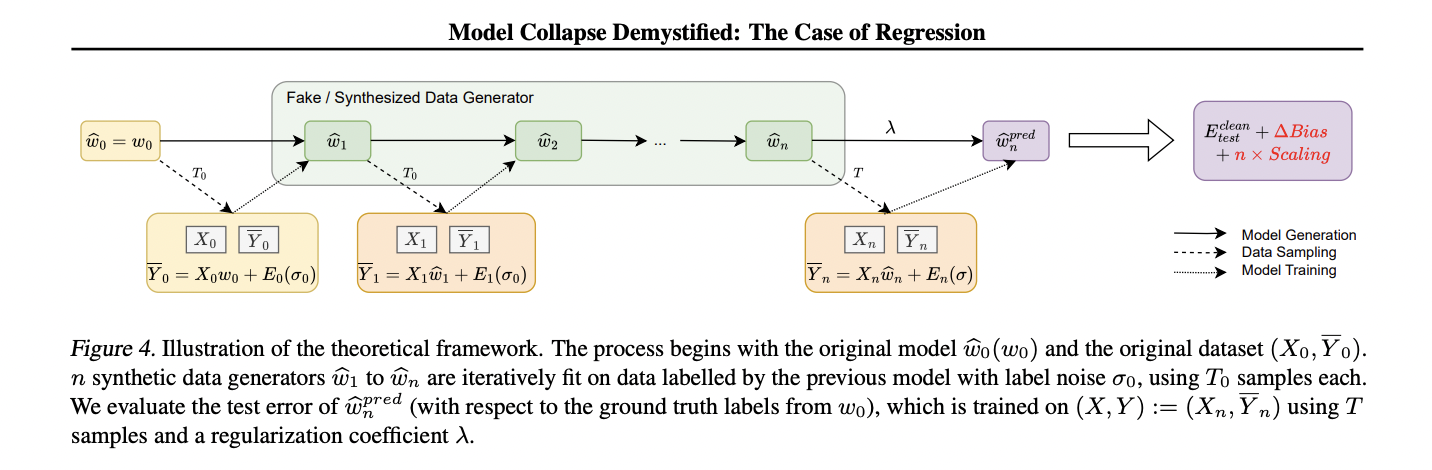


This theoretical framework developed on this examine yields a number of essential outcomes that make clear the dynamics of mannequin collapse in kernel regression settings:
1. For unregularized regression, the take a look at error of the downstream mannequin grows linearly with the variety of generations of artificial information, indicating a transparent degradation in efficiency.
2. Within the regularized case, the take a look at error is decomposed into three parts: bias, variance, and a further time period that grows with the variety of generations. This decomposition supplies a transparent image of how mannequin collapse manifests within the take a look at error.
3. The examine reveals that the power of the faux information generator, represented by the pattern measurement T0, performs an important function in figuring out the impression on the downstream mannequin’s efficiency. When T0 is sufficiently massive (under-parametrized regime), solely the variance time period is affected. Nonetheless, when T0 is small (over-parametrized regime), each bias and variance phrases are negatively impacted.
4. Within the absence of label noise, the examine demonstrates that mannequin collapse can nonetheless happen as a consequence of inadequate information within the artificial information era course of. That is significantly pronounced when the faux information turbines are impartial throughout generations, resulting in an exponential development within the bias time period.
5. The analysis supplies specific formulae for the take a look at error in numerous eventualities, together with isotropic and anisotropic function covariance constructions. These formulae enable for an in depth evaluation of how totally different parameters affect the severity of mannequin collapse.
These outcomes collectively present a complete theoretical understanding of mannequin collapse, providing insights into its mechanisms and potential mitigation methods via applicable regularization and information era processes.
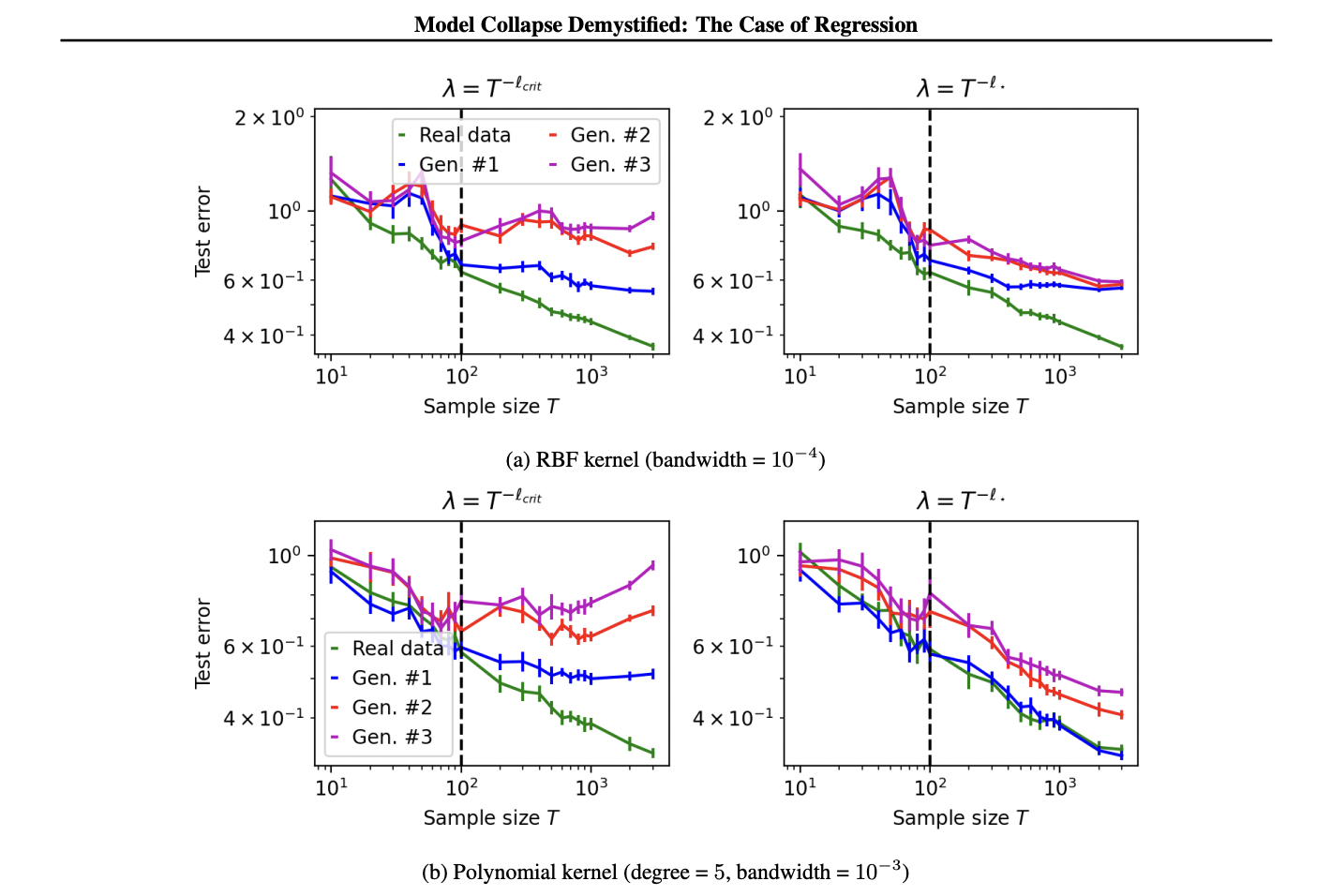
The outcomes reveal that mannequin collapse represents a modification of typical scaling legal guidelines when induced by faux information. For clearer presentation, the findings assume a situation the place the preliminary pattern measurement is larger than or equal to the dimensionality plus two. The examine examines fake-data era with a number of iterations, specializing in a ridge predictor based mostly on a faux information pattern. This predictor makes use of an adaptively tuned regularization parameter. The take a look at error for this predictor follows a particular scaling legislation below sure mathematical limits. These outcomes provide essential insights into how fashions skilled on faux information behave and carry out, significantly by way of their error charges and the way these charges scale with totally different parameters.
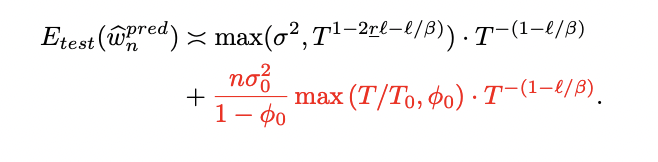
The examine conducts experiments utilizing each simulated and actual information to empirically validate the theoretical outcomes. For simulated information, strange linear ridge regression is carried out in a 300-dimensional house, exploring totally different constructions for the enter covariance matrix. The faux information generator is constructed in line with a particular course of, and downstream ridge fashions are fitted for numerous pattern sizes. Take a look at units consist of fresh information pairs from the true distribution, with experiments repeated to generate error bars.
Actual information experiments concentrate on kernel ridge regression utilizing the MNIST dataset, a well-liked benchmark in machine studying. The classification drawback is transformed to regression by modifying labels with added noise. Pretend coaching information is generated utilizing kernel ridge regression with RBF and polynomial kernels. The researchers look at totally different pattern sizes and match downstream kernel ridge fashions. These experiments are additionally repeated a number of instances to account for variations in label noise.
Outcomes are offered via a number of figures, illustrating the mannequin’s efficiency below totally different circumstances, together with isotropic and power-law settings, in addition to over-parameterized eventualities. The findings from each simulated and actual information experiments present empirical help for the theoretical predictions made earlier within the examine.
This examine marks a major shift in understanding take a look at error charges because the world enters the “artificial information age.” It supplies analytical insights into the mannequin collapse phenomenon, revealing it as a modification of typical scaling legal guidelines induced by artificial coaching information. The findings counsel that the proliferation of AI-generated content material might probably hinder future studying processes, probably growing the worth of non-AI-generated information. Virtually, the analysis signifies that AI-generated information alters optimum regularization for downstream fashions, suggesting that fashions skilled on combined information could initially enhance however later decline in efficiency. This necessitates a reevaluation of present coaching approaches within the period of artificial information.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our 52k+ ML SubReddit.
We’re inviting startups, firms, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report shall be launched in late October/early November 2024. Click on right here to arrange a name!
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


