Video Era by LLMs is an rising subject with a promising development trajectory. Whereas Autoregressive Giant Language Fashions (LLMs) have excelled in producing coherent and prolonged sequences of tokens in pure language processing, their software in video era has been restricted to brief movies of some seconds. To handle this, researchers have launched Loong, an auto-regressive LLM-based video generator able to producing movies that span minutes.
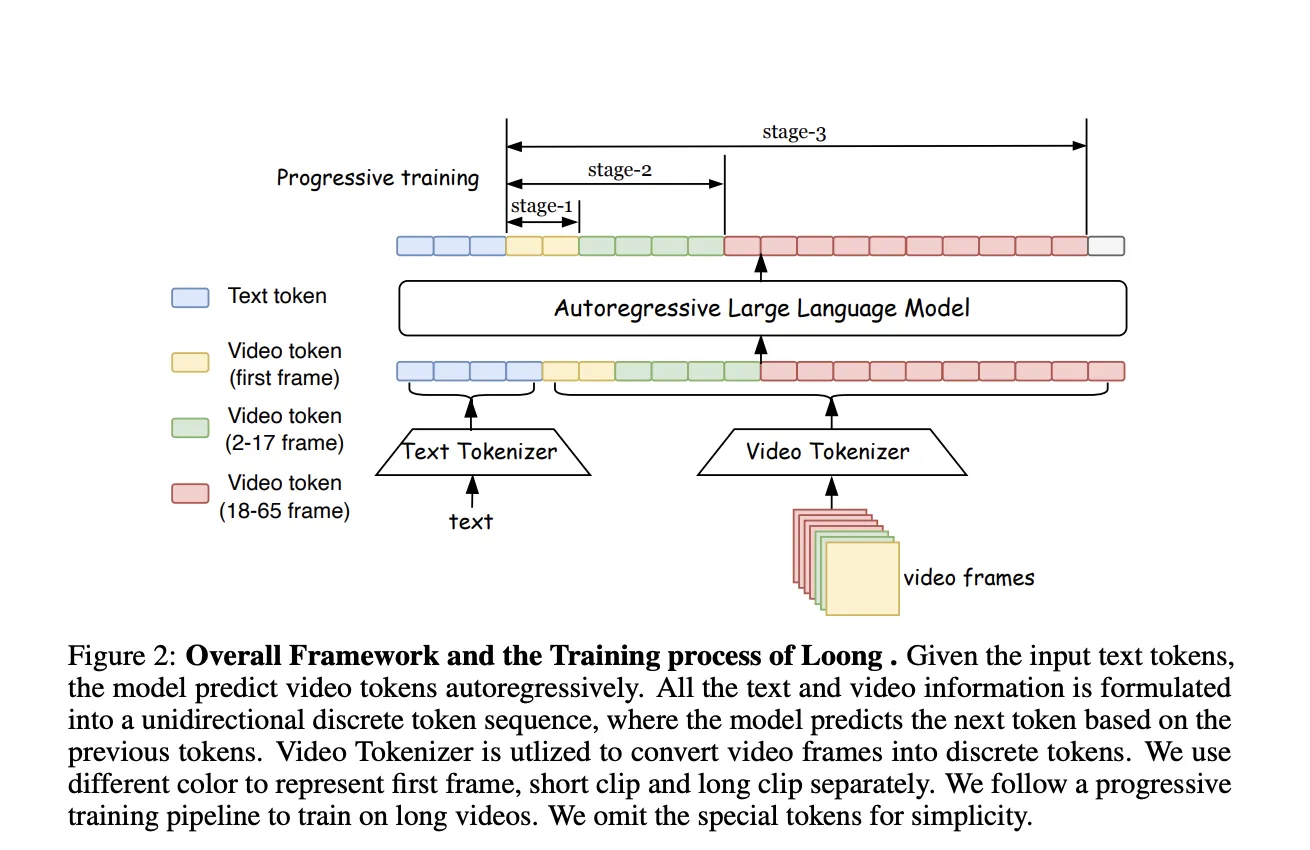
Coaching a video era mannequin like Loong includes a novel course of. The mannequin is skilled from scratch, with textual content tokens and video tokens handled as a unified sequence. The researchers have proposed a progressive short-to-long coaching method and a loss reweighing scheme to mitigate the loss imbalance drawback for lengthy video coaching. This permits Loong to be skilled on a 10-second video after which prolonged to generate minute-level lengthy movies conditioned on textual content prompts.
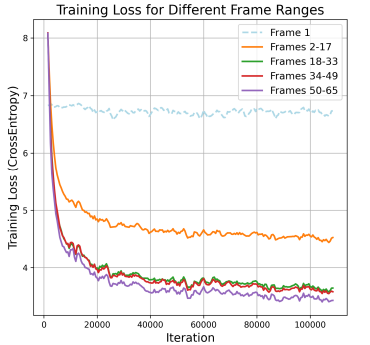
Nevertheless, the era of huge movies is kind of trickier and has many challenges forward. Firstly, there’s a drawback of imbalanced loss throughout coaching. When skilled with the target of next-token prediction, predicting early-frame tokens from textual content prompts is more durable than predicting late-frame tokens based mostly on earlier frames, resulting in uneven loss throughout coaching. As video size will increase, the accrued loss from simple tokens overshadows the loss from tough tokens, dominating the gradient course. Secondly, The mannequin predicts the subsequent token based mostly on ground-truth tokens, but it surely depends by itself predictions throughout inference. This discrepancy causes error accumulation, particularly on account of robust inter-frame dependencies and plenty of video tokens, resulting in visible high quality degradation in lengthy video inference.
To mitigate the problem of imbalanced video token difficulties, researchers have proposed a progressive short-to-long coaching technique with loss reweighting, demonstrated within the following:
Progressive Brief-to-long coaching
Coaching is factored into three phases, which will increase the coaching size:
Stage 1: Mannequin pre-trained with text-to-image era on a big dataset of static pictures, serving to the mannequin to determine a robust basis for modeling per-frame look
Stage 2: Mannequin skilled on pictures and brief video clips, the place mannequin learns to seize short-term temporal dependencies
Stage 3: The variety of video frames elevated, and joint coaching is sustained
Loong is designed with a two-component system, a video tokenizer that compresses movies to tokens and a decoder and a transformer that predicts the subsequent video tokens based mostly on textual content tokens.
Loong makes use of 3D CNN structure for the tokenizer, impressed by MAGViT2. The mannequin works with low-resolution movies and leaves super-resolution for post-processing. Tokenizer can compress 10-second video (65 frames, 128*128 decision) right into a sequence of 17*16*16 discrete tokens. Autoregressive LLM-based video era converts video frames into discrete tokens, permitting textual content and video tokens to type a unified sequence. Textual content-to-video era is modeled as autoregressive predicting video tokens based mostly on textual content tokens utilizing decoder-only Transformers.
Giant language fashions can generalize to longer movies, however extending past skilled durations dangers error accumulation and high quality degradation. There are ample strategies to appropriate it:
- Video token re-encoding
- Sampling technique
- Tremendous-resolution and refinement
The mannequin makes use of the LLaMA structure, with sizes starting from 700M TO 7B parameters. Fashions are skilled from scratch with out text-pretrained weights. The vocabulary accommodates 32,000 tokens for textual content, 8,192 tokens for video, and 10 particular tokens ( a complete of 40,202). The video tokenizer replicates MAGViT2, utilizing a causal 3D CNN construction for the primary video body. Spatial dimensions are compressed by 8x and temporal by 4x. Clustering Vector Quantization(CVQ) is used for quantization, enhancing codebook utilization over normal VQ. The video tokenizer has 246M parameters.

The Loong mannequin generates lengthy movies with a constant look, giant movement dynamics, and pure scene transitions. Loong is modeled with textual content tokens and video tokens in a unified sequence and overcomes the challenges of lengthy video coaching with the progressive short-to-long coaching scheme and loss reweighting. The mannequin could be deployed to help visible artists, movie producers, and leisure functions. However, on the identical time, it may be wrongly used to create faux content material and ship deceptive info.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Neglect to affix our 50k+ ML SubReddit
Concerned with selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science diploma on the Indian Institute of Know-how (IIT) Kharagpur. She has a deep ardour for Information Science and actively explores the wide-ranging purposes of synthetic intelligence throughout numerous industries. Fascinated by technological developments, Nazmi is dedicated to understanding and implementing cutting-edge improvements in real-world contexts.


