
The fast progress of text-to-image (T2I) diffusion fashions has made it potential to generate extremely detailed and correct photographs from textual content inputs. Nonetheless, because the size of the enter textual content will increase, present encoding strategies, corresponding to CLIP (Contrastive Language-Picture Pretraining), encounter varied limitations. These strategies wrestle to seize the complete complexity of lengthy textual content descriptions, making it tough to take care of alignment between the textual content and the generated photographs which creates challenges in appropriately representing the detailed issues of longer texts, which is essential for producing photographs that replicate the specified content material. Moreover, there’s a rising want for extra superior encoding methods able to dealing with textual content inputs and concurrently preserving the precision and coherence of the generated photographs. Whereas various strategies like massive language mannequin (LLM)-based encoders can deal with longer sequences, they fail to supply the identical stage of alignment as contrastive pre-training encoders do.
The rising recognition of diffusion fashions has been pushed by developments in quick sampling methods and text-conditioned era. Diffusion fashions remodel a Gaussian distribution right into a goal knowledge distribution through a multiple-step denoising course of. The loss perform helps predict noise added to wash knowledge, with DDIM and DDPM cleansing this course of. Steady Diffusion integrates a VAE, CLIP, and diffusion mannequin to generate photographs from textual content prompts.
Desire fashions are refined with human suggestions to higher align generated photographs with textual content prompts. Nonetheless, reward fine-tuning, which makes use of these fashions as indicators, faces challenges like overfitting and inefficient backpropagation. Strategies like DRTune assist by truncating gradients to enhance sampling steps, although overfitting stays. Cascaded and latent house fashions permit for high-resolution picture era, enhancing style-consistent content material creation and enhancing. Conventional analysis metrics, like Inception Rating (IS) and Fréchet Inception Distance (FID), have limitations, resulting in newer approaches like perceptual similarity metrics (LPIPS), detection fashions, and human desire fashions. Strategies like DPOK and DiffusionCLIP optimize outcomes utilizing human preferences, whereas DRTune will increase coaching velocity by controlling enter gradients, enhancing effectivity. To deal with these points, a gaggle of researchers from The College of Hong Kong, Sea AI Lab, Singapore, Renmin College of China, Zhejiang College have proposed LongAlign, which features a segment-level encoding technique for processing lengthy texts and a decomposed desire optimization technique for efficient alignment coaching.
The researchers have proposed a segment-level encoding technique to permit fashions with restricted enter capability to course of long-text inputs successfully. A desire decomposition strategy is launched, enabling desire fashions to generate T2I alignment scores alongside common desire scores, which boosts textual content alignment throughout the fine-tuning of generative fashions. After roughly 20 hours of fine-tuning, the proposed longSD mannequin outperforms stronger basis fashions in long-text alignment, demonstrating important potential for enchancment past the mannequin’s structure. LongAlign’s segment-level encoding overcomes enter size limits by processing textual content segments individually. The decomposed desire optimization technique makes use of CLIP-based desire fashions, decomposing desire scores into text-relevant and text-irrelevant components. A reweighting technique is utilized to cut back overfitting and improve alignment. Wonderful-tuning Steady Diffusion (SD) v1.5 with LongAlign for 20 hours resulted in superior T2I alignment in comparison with fashions like PixArt-α and Kandinsky v2.2
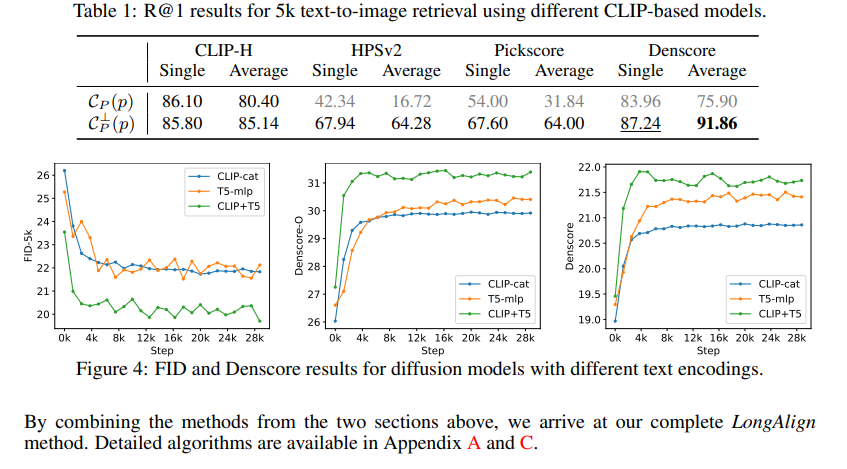
LongAlign divides the textual content into segments, encodes them individually, and merges the outcomes. For diffusion fashions, it makes use of embedding concatenation, and for desire fashions, a segment-level loss for detailed desire scores. CLIP’s token restrict is addressed by segment-level encoding. Direct embedding concatenation led to poor picture high quality, however retaining start-of-text embeddings, eradicating end-of-text embeddings, and introducing a brand new padding embedding improved merging. Each CLIP and T5 can be utilized for long-text encoding. Diffusion fashions are fine-tuned with large-scale, lengthy texts paired with their corresponding photographs to make sure an correct illustration of textual content segments. In desire optimization, CLIP-based fashions are aligned by splitting long-text situations into segments and defining a brand new segment-level desire coaching loss. This allows weakly supervised studying and generates detailed segment-level scores. Utilizing desire fashions as reward indicators for fine-tuning T2I diffusion fashions presents challenges in backpropagating gradients and managing overfitting. A reweighted gradient strategy is launched to deal with these points. LongAlign combines these strategies to enhance long-text alignment; some experiments carried out confirmed that the LongAlign mannequin achieved higher era outcomes in comparison with the baseline fashions whereas successfully dealing with long-text inputs and displaying its benefits.
In conclusion, the LongAlign mannequin considerably improves the alignment of generated photographs with lengthy textual content enter. It outperforms the present fashions by introducing segment-level encoding and a decomposed desire optimization technique, showcasing its effectivity in dealing with advanced and prolonged textual content descriptions. This development technique is past CLIP-based fashions with the limitation that the strategy nonetheless doesn’t totally seize the era of the precise variety of entities specified by prompts, partly as a result of constraints of CLIP.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Wonderful-Tuned Fashions: Predibase Inference Engine (Promoted)
Nazmi Syed is a consulting intern at MarktechPost and is pursuing a Bachelor of Science diploma on the Indian Institute of Know-how (IIT) Kharagpur. She has a deep ardour for Knowledge Science and actively explores the wide-ranging functions of synthetic intelligence throughout varied industries. Fascinated by technological developments, Nazmi is dedicated to understanding and implementing cutting-edge improvements in real-world contexts.


