
Giant Language Fashions (LLMs) have made vital strides in varied Pure Language Processing duties, but they nonetheless wrestle with arithmetic and sophisticated logical reasoning. Chain-of-Thought (CoT) prompting has emerged as a promising strategy to boost reasoning capabilities by incorporating intermediate steps. Nevertheless, LLMs usually exhibit untrue reasoning, the place conclusions don’t align with the generated reasoning chain. This problem has led researchers to discover extra refined reasoning topologies and neuro-symbolic strategies. These approaches purpose to simulate human reasoning processes and combine symbolic reasoning with LLMs. Regardless of these developments, present strategies face limitations, notably the difficulty of data loss throughout the extraction of logical expressions, which may result in incorrect intermediate reasoning processes.
Researchers have developed varied approaches to boost LLMs’ reasoning capabilities. CoT prompting and its variants, corresponding to Zero-shot CoT and CoT with Self-Consistency, have improved logical reasoning by breaking down advanced issues into intermediate steps. Different strategies like Least-To-Most prompting and Divide-and-Conquer concentrate on drawback decomposition. Tree-of-Ideas and Graph-of-Ideas introduce extra advanced reasoning topologies. Neuro-symbolic approaches mix LLMs with symbolic reasoning to handle untrue reasoning. These embody LReasoner, LogicAsker, Logic-LM, SatLM, and LINC, which combine logical formalization, symbolic solvers, and LLMs to boost reasoning capabilities and overcome info loss points.
Researchers from the College of Science and Know-how of China, Institute of Automation, Chinese language Academy of Sciences, Beihang College, and JD.com current Logic-of-Thought (LoT), a novel prompting methodology designed to handle the data loss concern in present neuro-symbolic approaches. LoT extracts propositions and logical expressions from the enter context, expands them utilizing logical reasoning legal guidelines, and interprets the expanded expressions again into pure language. This prolonged logical description is then appended to the unique enter immediate, guiding the LLM’s reasoning course of. By preserving the unique immediate and including logical info in pure language, LoT avoids full reliance on symbolic solvers and mitigates info loss. The tactic is appropriate with present prompting methods, permitting for seamless integration. Experiments throughout 5 logical reasoning datasets show LoT’s effectiveness in considerably boosting the efficiency of assorted prompting strategies, together with Chain-of-Thought, Self-Consistency, and Tree-of-Ideas.
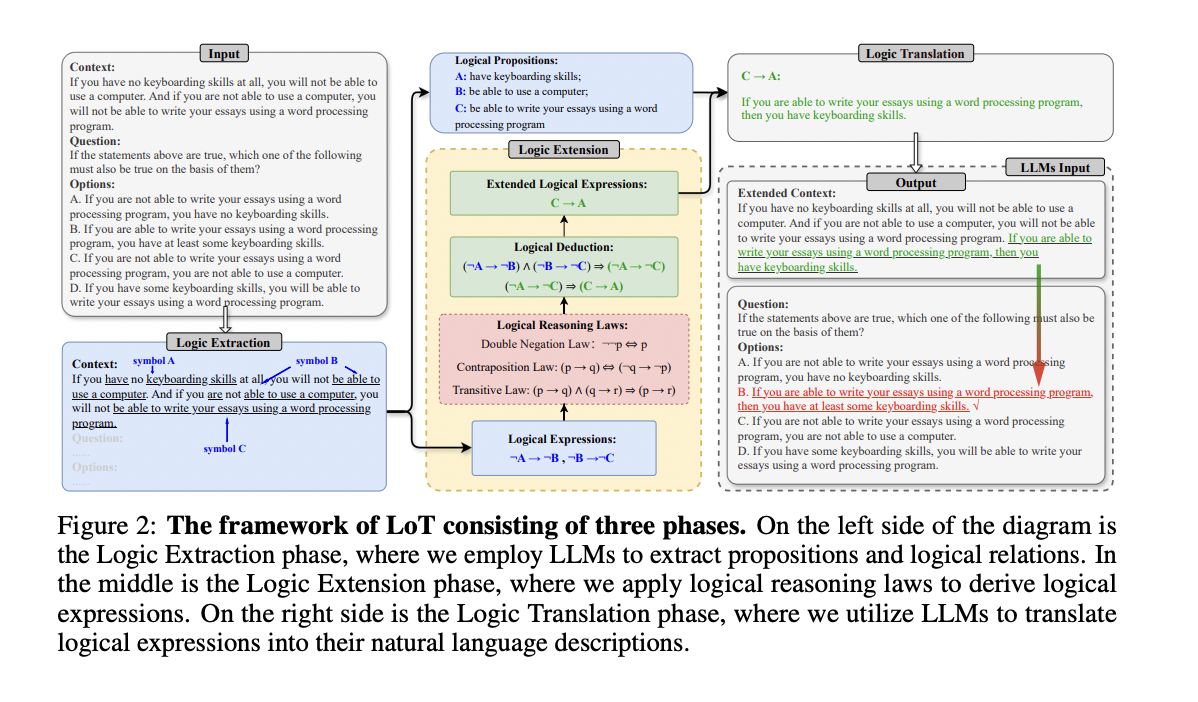
LoT framework includes three key phases: Logic Extraction, Logic Extension, and Logic Translation. Within the Logic Extraction part, LLMs determine sentences with conditional reasoning relationships and extract propositional symbols and logical expressions from the enter context. The Logic Extension part employs a Python program to broaden these logical expressions utilizing predefined reasoning legal guidelines. Lastly, the Logic Translation part makes use of LLMs to transform the expanded logical expressions again into pure language descriptions. These descriptions are then included into the unique enter immediate, making a complete new immediate for LLMs. This course of preserves the unique context whereas augmenting it with extra logical info, successfully guiding the LLM’s reasoning course of with out relying solely on symbolic solvers or risking info loss.
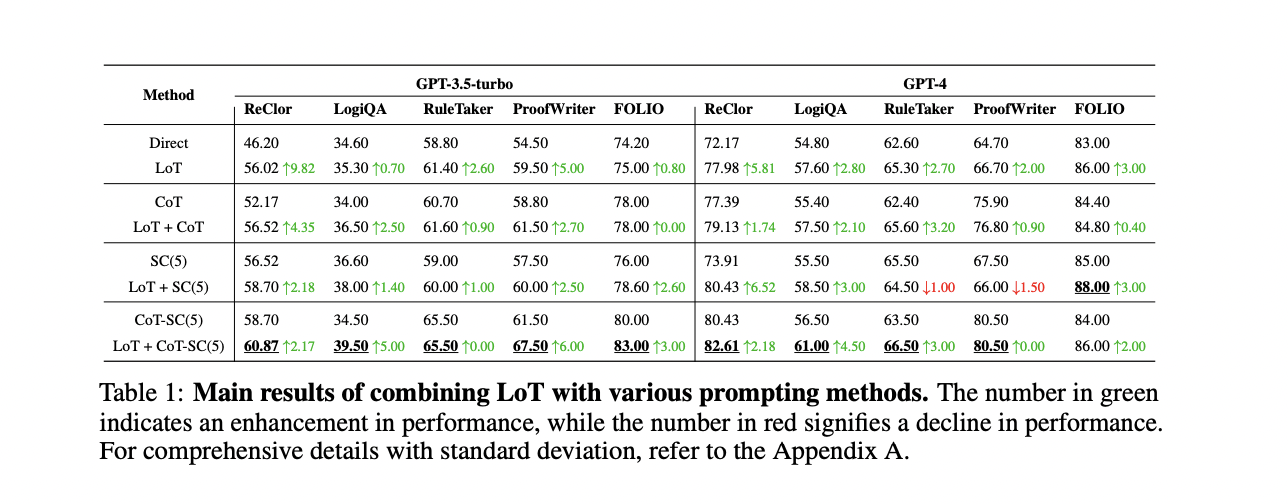
LoT prompting considerably enhances the efficiency of present strategies throughout 5 logical reasoning datasets. LoT+CoT-SC(5) persistently outperforms different strategies, with LoT+SC reaching the best accuracy on the FOLIO dataset with GPT-4. LoT improves baseline strategies in 35 out of 40 comparisons, demonstrating its seamless integration and effectiveness. Minor enhancements happen when combining LoT with CoT or CoT-SC on account of overlapping capabilities. Some limitations are noticed within the RuleTaker and ProofWriter datasets with GPT-4, attributed to info extraction points. Total, LoT standalone efficiency matches or exceeds CoT, highlighting its strong logical reasoning capabilities.

LoT is a sturdy symbolic-enhancement prompting strategy that addresses info loss in neuro-symbolic strategies. By deriving expanded logical info from enter context utilizing propositional logic, LoT augments unique prompts to boost LLMs’ logical reasoning capabilities. Its compatibility with present prompting methods like Chain-of-Thought, Self-Consistency, and Tree-of-Ideas permits for seamless integration. Experiments show that LoT considerably improves the efficiency of assorted prompting strategies throughout a number of logical reasoning datasets. Future work will concentrate on exploring extra logical relationships and reasoning legal guidelines, in addition to supporting extra prompting strategies to additional improve LoT’s logical reasoning capabilities.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


