
In latest instances, massive language fashions (LLMs) constructed on the Transformer structure have proven exceptional skills throughout a variety of duties. Nevertheless, these spectacular capabilities normally include a big enhance in mannequin dimension, leading to substantial GPU reminiscence prices throughout inference. The KV cache is a well-liked technique utilized in LLM inference. It saves the beforehand calculated keys and values within the consideration course of, which might then be reused to hurry up future steps, making the inference course of quicker total. Most present KV cache compression strategies concentrate on intra-layer compression inside a single Transformer layer, however few works take into account layer-wise compression. The reminiscence utilized by the KV (key-value) cache is generally occupied by storing the important thing and worth elements of the eye map, which make up over 80% of the overall reminiscence utilization. This makes system assets inefficient and creates a requirement for extra computational energy.
Researchers have developed many strategies to compress KV caches to cut back reminiscence consumption. Nevertheless, most of those researches are primarily targeting compressing the KV cache inside every LLM Transformer layer. However, layer-wise KV cache compression methods stay largely unexplored, which calculate the KV cache for under a subset of layers to reduce reminiscence utilization. The restricted present work on layer-wise KV cache compression usually requires extra coaching to take care of passable efficiency. Many of the present KV cache compression work, akin to H2O, SnapKV, and PyramidInfer, are carried out inside a single transformer layer, specifically the intra-layer compression, however they don’t handle layer-wise KV cache compression. A number of works like CLA, LCKV, Ayer, and many others. have centered on layer-wise compression methods for the KV cache. Nevertheless, all of them require additional coaching of the mannequin slightly than being plug-and-play on well-trained LLMs.
A gaggle of researchers from Shanghai Jiao Tong College, Central South College, Harbin Institute of Expertise, and ByteDance proposed KVSharer, a plug-and-play technique for compressing the KV cache of well-trained LLMs. The researchers found the strategy, the place KV caches differ drastically between two layers, sharing one layer’s KV cache with the opposite throughout inference doesn’t considerably cut back efficiency. Leveraging observations, KVSharer employs a search technique to establish the KV cache-sharing technique throughout completely different layers throughout inference. KVSharer considerably reduces GPU reminiscence consumption whereas sustaining a lot of the mannequin efficiency. As a layer-wise KV cache compression approach, KVSharer works effectively with present strategies that compress KV caches inside every layer, offering an extra solution to optimize reminiscence in LLMs.
The principle steps of KVSharer are divided into two elements. First, a given LLM searches for a sharing technique, a listing that specifies which layers’ KV caches ought to be changed by these of different particular layers. Then, through the subsequent prefill and technology steps for all duties, the KV caches are used.
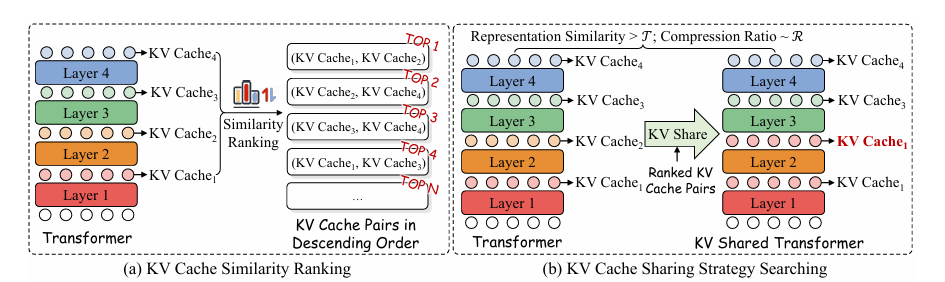
An efficient KV cache-sharing technique for LLMs begins by measuring variations between the KV caches of every layer on a take a look at dataset, specializing in sharing essentially the most completely different pairs. KV caches are shared from one layer to a different, with a precedence for layers close to the output to keep away from any degradation in efficiency. Every shared pair is barely stored if the output stays related sufficient to the unique. This course of continues till the goal variety of shared layers is reached, leading to a method that hastens future duties by reusing KV caches effectively.
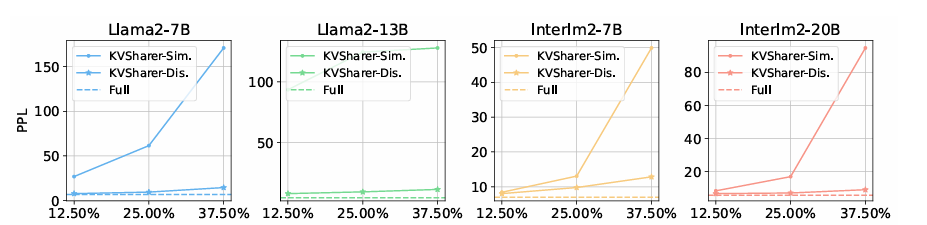
Researchers examined the KVSharer mannequin on a number of English and bilingual fashions, together with Llama2 and InternLM2, and located that it could actually compress knowledge successfully with solely small losses in efficiency. Utilizing the OpenCompass benchmark, the group of researchers evaluated the mannequin’s capability to purpose, language, information, and perceive duties with datasets like CMNLI, HellaSwag, and CommonSenseQA. At compression ranges beneath 25%, KVSharer retained about 90-95% of the unique mannequin’s efficiency and labored effectively with different compression methods like H2O and PyramidInfer, bettering reminiscence effectivity and processing pace. Exams on bigger fashions, akin to Llama2-70B, confirmed KVSharer’s functionality to compress cache successfully with minimal influence on efficiency.
In conclusion, the proposed KVSharer technique affords an environment friendly resolution for decreasing reminiscence consumption and bettering inference pace in LLMs by leveraging a counterintuitive strategy of sharing dissimilar KV caches. The experiments present that KVSharer maintains over 90% of the unique efficiency of mainstream LLMs whereas decreasing KV cache computation by 30%. It will possibly additionally present not less than 1.3 instances acceleration in technology. Moreover, KVSharer might be built-in with present intra-layer KV cache compression strategies to realize even higher reminiscence financial savings and quicker inference. Therefore, this technique works effectively with present compression methods, can be utilized for various duties without having further coaching, and can be utilized as a base for future growth within the area.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Overlook to hitch our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An In depth Assortment of Small Language Fashions (SLMs) for Intel PCs
Divyesh is a consulting intern at Marktechpost. He’s pursuing a BTech in Agricultural and Meals Engineering from the Indian Institute of Expertise, Kharagpur. He’s a Knowledge Science and Machine studying fanatic who desires to combine these main applied sciences into the agricultural area and clear up challenges.


