
Massive Language Fashions (LLMs) have revolutionized pure language processing, enabling AI programs to carry out a variety of duties with outstanding proficiency. Nonetheless, researchers face vital challenges in optimizing LLM efficiency, notably in human-LLM interactions. A essential remark reveals that the standard of LLM responses tends to enhance with repeated prompting and consumer suggestions. Present methodologies typically depend on naïve prompting, resulting in calibration errors and suboptimal outcomes. This presents an important downside: creating extra refined prompting methods that may considerably improve the accuracy and reliability of LLM outputs, thereby maximizing their potential in varied functions.
Researchers have tried to beat the challenges in optimizing LLM efficiency by varied prompting methods. The Enter-Output (IO) technique represents essentially the most primary method, utilizing a direct input-output mechanism with out intermediate reasoning. This technique, nonetheless, typically falls brief in complicated duties requiring nuanced understanding. Chain-of-thought (CoT) prompting emerged as an development, introducing a single, linear reasoning path. This method encourages LLMs to articulate intermediate reasoning steps, resulting in improved efficiency on complicated duties. Constructing upon this, Tree-of-Thought (ToT) strategies expanded the idea by exploring a number of reasoning paths in parallel, forming a branching construction to optimize outputs. This method has proven specific efficacy in explorative duties like puzzle-solving. Additionally, another frameworks, corresponding to Self-Refine and Self-Verification, allow LLMs to critique and refine their outputs iteratively. Nonetheless, these strategies nonetheless depend on static or semi-static prompts, limiting their adaptability to evolving contexts. Regardless of these developments, present approaches wrestle to completely make the most of the LLM’s inner information base and adapt dynamically to every distinctive question and response context.
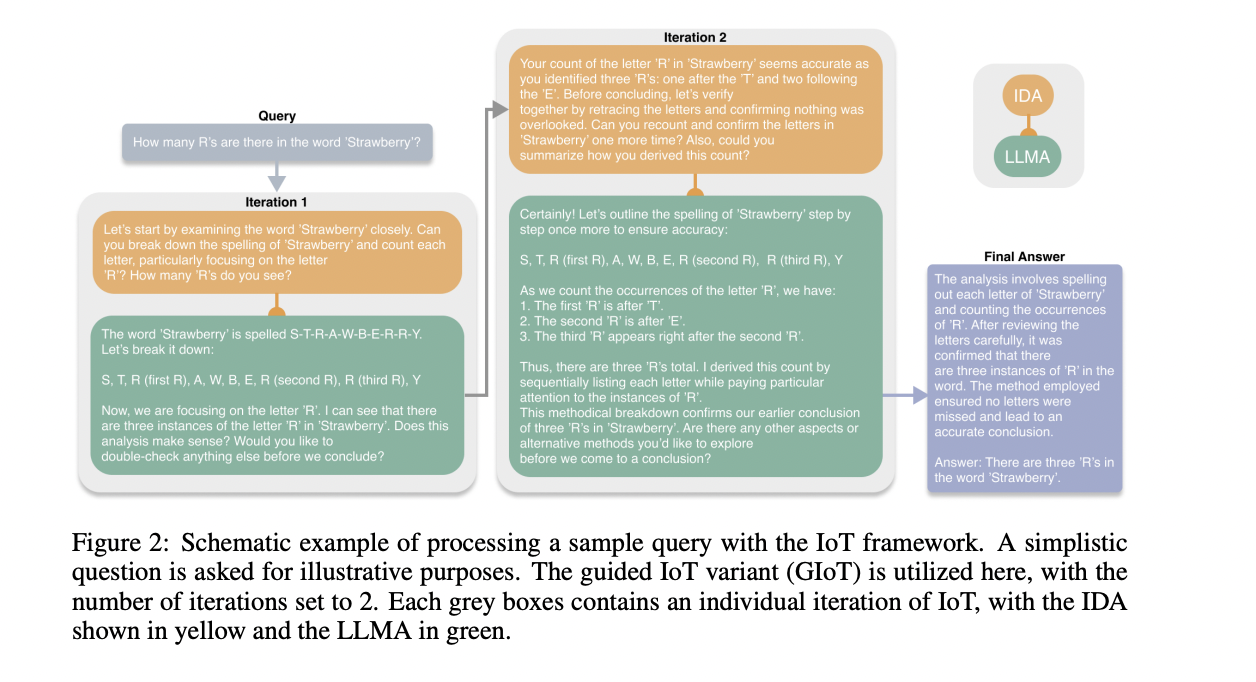
Researchers from Agnostiq Inc. and the College of Toronto introduce the Iteration of Thought (IoT) framework, an autonomous, iterative, and adaptive method to LLM reasoning with out human suggestions. Not like static and semi-static frameworks, IoT makes use of an Internal Dialogue Agent (IDA) to regulate and refine its reasoning path throughout every iteration. This permits adaptive exploration throughout completely different reasoning timber, fostering a extra versatile and context-aware response technology course of. Additionally, the core IoT framework consists of three important elements: the IDA, the LLM Agent, and the Iterative Prompting Loop. The IDA capabilities as a information, dynamically producing context-sensitive prompts primarily based on the unique consumer question and the LLM’s earlier response. The LLMA embodies the core reasoning capabilities of an LLM, processing the IDA’s dynamically generated prompts. The Iterative Prompting Loop facilitates a back-and-forth interplay between the IDA and LLMA, constantly enhancing the standard of solutions with out exterior inputs.
The IoT framework is carried out by two variants: Autonomous Iteration of Thought (AIoT) and Guided Iteration of Thought (GIoT). AIoT permits the LLM Agent to autonomously determine when it has generated a passable response, doubtlessly resulting in quicker analysis however risking untimely stops on complicated queries. GIoT mandates a set variety of iterations, aiming for a complete exploration of reasoning paths at the price of extra computational sources. Each variants make the most of the core IoT elements: the Internal Dialogue Agent, LLM Agent, and Iterative Prompting Loop. Carried out as a Python library with Pydantic for output schemas, IoT allows adaptive exploration throughout completely different reasoning timber. The selection between AIoT and GIoT permits for balancing exploration depth and computational effectivity primarily based on process necessities.
The IoT framework demonstrates vital enhancements throughout varied reasoning duties. On the GPQA Diamond dataset, AIoT achieved a 14.11% accuracy enchancment over the baseline Enter-Output technique, outperforming CoT and GIoT. For exploratory problem-solving duties like Recreation of 24 and Mini Crosswords, GIoT confirmed superior efficiency, with enhancements of 266.4% and 90.6% respectively over CoT. In multi-context reasoning duties utilizing the HotpotQA-Onerous dataset, AIoT outperformed CoT and even surpassed the AgentLite framework, reaching the next F1 of 0.699 and an Precise Match of 0.53 scores. These outcomes spotlight IoT’s effectiveness in adapting to completely different reasoning contexts, from deep information duties to multi-hop query answering, showcasing its potential as a flexible and highly effective reasoning framework for giant language fashions.
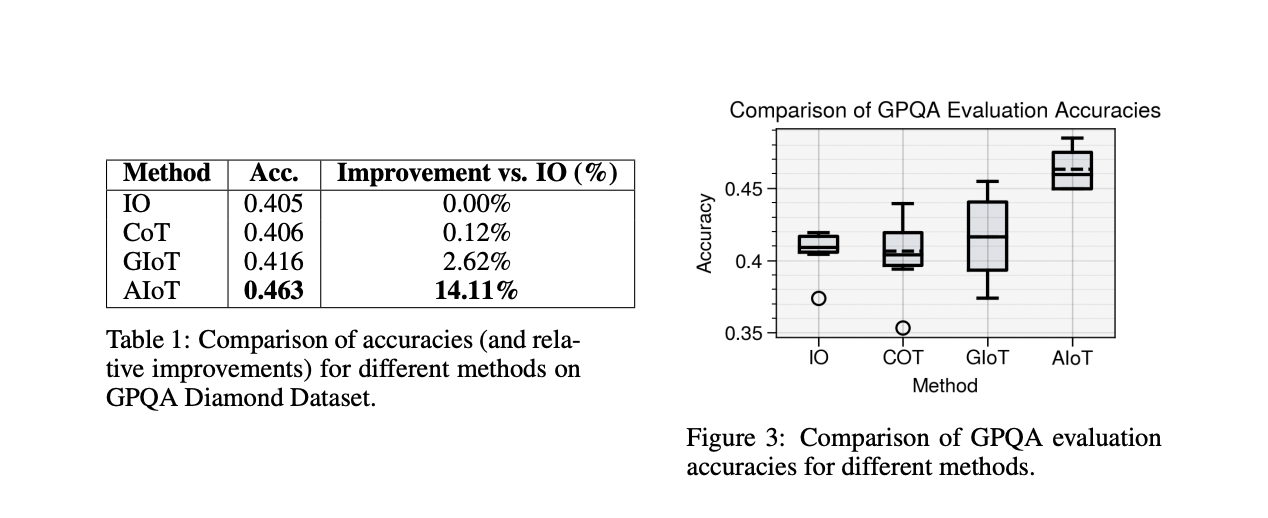
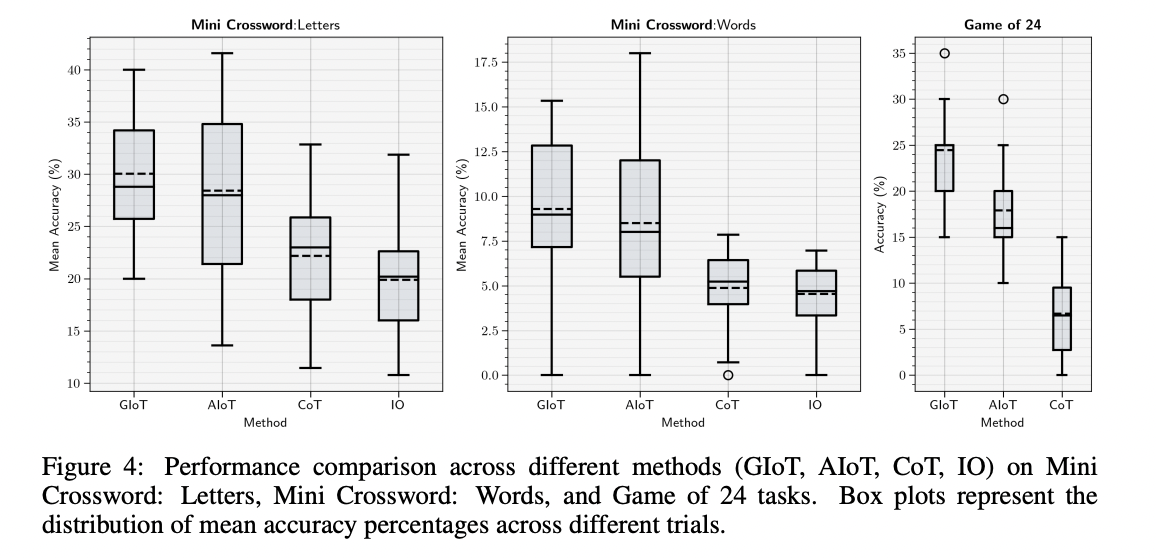
The IoT framework introduces a novel method to complicated reasoning duties utilizing massive language fashions. IoT demonstrates vital enhancements throughout varied difficult duties by using an IIDA that iteratively converses with an LLM Agent. Two variants of the framework, AIoT, and GIoT, had been examined on numerous issues together with puzzles (Recreation of 24, Mini Crosswords) and complicated questionnaires (GPQA, HotpotQA). GIoT, which performs a set variety of iterations, excelled within the Recreation of 24, whereas AIoT, with its self-determined termination, confirmed superior efficiency on GPQA. Each variants outperformed the CoT framework in all in contrast duties. Notably, on the multi-context HotpotQA process, IoT surpassed the hierarchical AgentLite framework, reaching roughly 35% enchancment within the F1 rating and 44% within the Precise Match rating. These outcomes underscore IoT’s potential to introduce productive dynamism into low-complexity agentic frameworks, marking a big development in LLM reasoning capabilities.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


