
Integrating APIs into Massive Language Fashions (LLMs) represents a big leap ahead within the quest for extremely purposeful AI techniques able to performing complicated duties akin to resort bookings or job requisitions by way of conversational interfaces. This development, nonetheless, hinges on the LLMs’ potential to precisely detect APIs, fill required parameters, and sequence API calls primarily based on consumer utterances. The bottleneck in attaining these capabilities has been the shortage of numerous, real-world coaching and benchmarking knowledge, which is essential for fashions to generalize nicely outdoors their coaching domains.
To sort out this, this paper introduces a novel dataset named API-BLEND (Determine 2), marking a big departure from the reliance on synthetically generated knowledge, which frequently suffers from points like bias and lack of variety. API-BLEND is a hybrid dataset enriched by human-annotated knowledge and LLM-assisted era, masking over 178,000 situations throughout coaching, improvement, and testing phases. This dataset is exclusive in its scale and focuses on sequencing duties—a essential facet typically neglected in current datasets. API-BLEND provides an unprecedented number of API-related duties by incorporating knowledge from numerous domains akin to semantic parsing, dialog, and digital help.
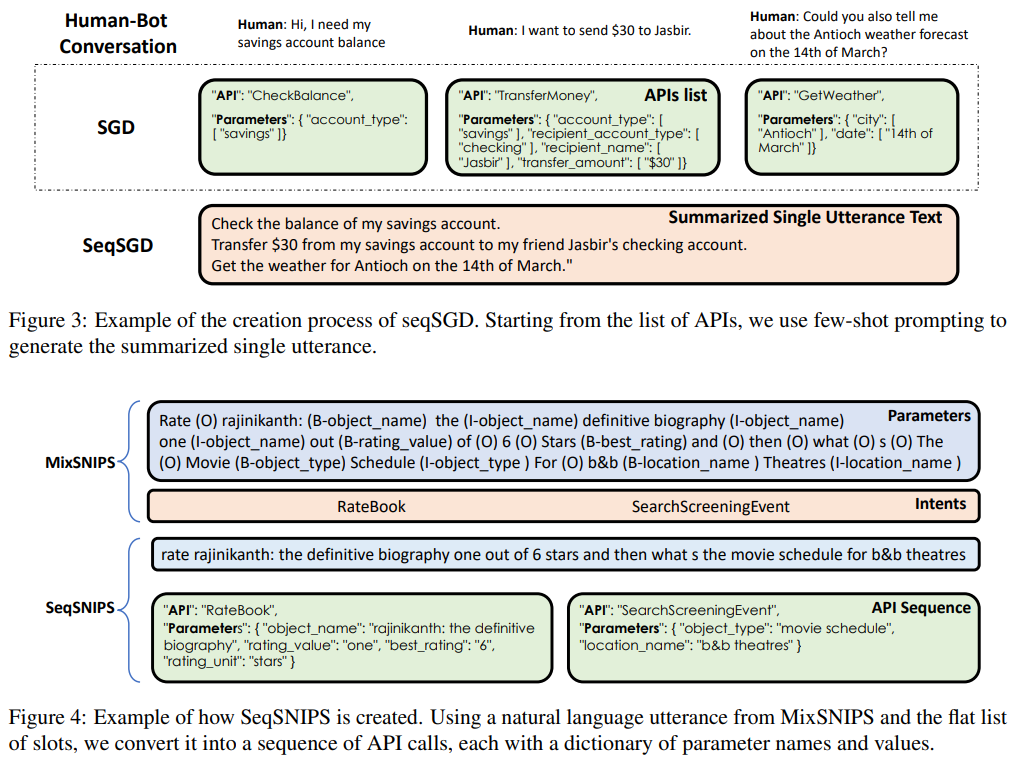
The core of API-BLEND’s innovation lies in its complete method to knowledge curation, spanning language model-assisted era, grammar-based era, and direct inclusion of off-the-shelf datasets. This multifaceted technique ensures a wealthy mix of API sequences, parameters, and contexts, aiming to handle the complexity of real-world API utilization in LLMs. The dataset consists of sequences derived from current dialogues, transformed into API calls by way of superior fashions like FLAN-T5-XXL, and additional enriched by grammar rule-based transformations and pre-existing datasets tailored for API sequence analysis.
Empirical evaluations have positioned API-BLEND as a superior coaching and benchmarking instrument in comparison with different datasets, with fashions educated on API-BLEND demonstrating considerably higher out-of-domain (OOD) generalization. That is evidenced by the efficiency of fashions fine-tuned with API-BLEND knowledge throughout numerous OOD assessments, the place they outperform different API-augmented LLMs, showcasing their enhanced potential to navigate the complexities of API integration.
Moreover, API-BLEND has been rigorously benchmarked in opposition to 9 open-sourced fashions throughout a variety of settings, together with few-shot testing, instruction fine-tuning on course datasets, and mixed dataset fine-tuning. The outcomes underscore the robustness of API-BLEND in coaching fashions that excel in API detection, parameter filling, and sequencing—essential for executing complicated duties by way of conversational AI. Notably, fashions educated on the mixed API-BLEND datasets achieved commendable efficiency throughout particular person datasets, highlighting the dataset’s position in fostering a flexible and adaptable understanding of API interactions in LLMs.
In abstract, API-BLEND emerges as a significant useful resource for growing and benchmarking tool-augmented LLMs, bridging the hole between artificial knowledge limitations and the necessity for real-world applicability. By providing a various, complete corpus, API-BLEND advances state-of-the-art API-integrated language fashions and units a brand new dataset variety and utility commonplace. As the sphere strikes ahead, the exploration of setting interactions and multilingual API instructions represents thrilling avenues for additional enhancing the practicality and attain of API-augmented AI techniques.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and Google Information. Be a part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Neglect to affix our Telegram Channel
You might also like our FREE AI Programs….
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s obsessed with analysis and the newest developments in Deep Studying, Pc Imaginative and prescient, and associated fields.


