
A groundbreaking examine carried out by researchers from Huawei Noah’s Ark Lab, in collaboration with Peking College and Huawei Shopper Enterprise Group, presents a transformative method to creating tiny language fashions (TLMs) appropriate for cellular gadgets. Regardless of their diminished dimension, these compact fashions intention to ship efficiency on par with their bigger counterparts, addressing the essential want for environment friendly AI purposes in resource-constrained environments.
The analysis staff tackled the urgent problem of optimizing language fashions for cellular deployment. Conventional massive language fashions, whereas highly effective, may very well be extra sensible for cellular use resulting from their substantial computational and reminiscence necessities. This examine introduces an modern tiny language mannequin, PanGu-π Professional, which leverages a meticulously designed structure and superior coaching methodologies to realize exceptional effectivity and effectiveness.
On the core of their methodology is a strategic optimization of the mannequin’s elements. The staff launched into a collection of empirical research to dissect the impression of assorted parts on the mannequin’s efficiency. A notable innovation is the compression of the tokenizer, considerably decreasing the mannequin’s dimension with out compromising its capacity to know and generate language. Moreover, architectural changes have been made to streamline the mannequin, together with parameter inheritance from bigger fashions and a multi-round coaching technique that enhances studying effectivity.
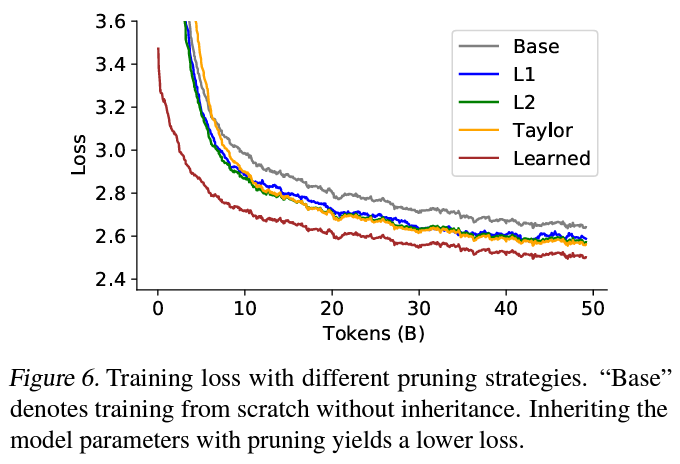
The introduction of PanGu-π Professional in 1B and 1.5B parameter variations marks a major leap ahead. Following the newly established optimization protocols, the fashions have been skilled on a 1.6T multilingual corpus. The outcomes have been astounding; PanGu-π-1B Professional demonstrated a median enchancment of 8.87 on benchmark analysis units. Extra impressively, PanGu-π-1.5B Professional surpassed a number of state-of-the-art fashions with bigger sizes, establishing new benchmarks for efficiency in compact language fashions.
The implications of this analysis prolong far past the realm of cellular gadgets. By reaching such a fragile stability between dimension and efficiency, the Huawei staff has opened new avenues for deploying AI applied sciences in numerous situations the place computational sources are restricted. Their work not solely paves the best way for extra accessible AI purposes but in addition units a precedent for future analysis in optimizing language fashions.
This examine’s findings are a testomony to the chances inherent in AI, showcasing how modern approaches can overcome the restrictions of present applied sciences. The Huawei staff’s contributions are poised to revolutionize how we take into consideration and work together with AI, making it extra ubiquitous and built-in into our every day lives. As we progress, the rules and methodologies developed on this analysis will undoubtedly affect the evolution of AI applied sciences, making them extra adaptable, environment friendly, and accessible to all.
Take a look at the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to observe us on Twitter and Google Information. Be a part of our 36k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our Telegram Channel
Muhammad Athar Ganaie, a consulting intern at MarktechPost, is a proponet of Environment friendly Deep Studying, with a concentrate on Sparse Coaching. Pursuing an M.Sc. in Electrical Engineering, specializing in Software program Engineering, he blends superior technical information with sensible purposes. His present endeavor is his thesis on “Enhancing Effectivity in Deep Reinforcement Studying,” showcasing his dedication to enhancing AI’s capabilities. Athar’s work stands on the intersection “Sparse Coaching in DNN’s” and “Deep Reinforcemnt Studying”.


