
A significant problem within the discipline of Speech-Language Fashions (SLMs) is the shortage of complete analysis metrics that transcend fundamental textual content material modeling. Whereas SLMs have proven vital progress in producing coherent and grammatically appropriate speech, their capacity to mannequin acoustic options similar to emotion, background noise, and speaker identification stays underexplored. Evaluating these dimensions is essential, as human communication is closely influenced by such acoustic cues. For instance, the identical phrase spoken with completely different intonations or in several acoustic environments can carry totally completely different meanings. The absence of strong benchmarks to evaluate these options limits the sensible applicability of SLMs in real-world duties similar to sentiment detection in digital assistants or multi-speaker environments in stay broadcasting methods. Overcoming these challenges is important for advancing the sphere and enabling extra correct and context-aware speech processing.
Present analysis methods for SLMs primarily give attention to semantic and syntactic accuracy via text-based metrics similar to phrase prediction and sentence coherence. These strategies embody benchmarks like ProsAudit, which evaluates prosodic components like pure pauses, and SD-eval, which assesses fashions’ capacity to generate textual content responses that match a given audio context. Nonetheless, these strategies have vital limitations. They both give attention to a single facet of acoustics (similar to prosody) or depend on generation-based metrics which might be computationally intensive, making them unsuitable for real-time functions. Moreover, text-based evaluations fail to account for the richness of non-linguistic info current in speech, similar to speaker identification or room acoustics, which might drastically alter the notion of spoken content material. Consequently, present approaches are inadequate for evaluating the holistic efficiency of SLMs in environments the place each semantic and acoustic consistency are important.
Researchers from the Hebrew College of Jerusalem introduce SALMON, a complete analysis suite particularly designed to evaluate the acoustic consistency and acoustic-semantic alignment capabilities of SLMs. SALMON introduces two major analysis duties: (i) acoustic consistency and (ii) acoustic-semantic alignment, which take a look at how effectively a mannequin can preserve acoustic properties and align them with the spoken textual content. As an example, SALMON evaluates whether or not a mannequin can detect unnatural shifts in speaker identification, background noise, or sentiment inside an audio clip. It makes use of a modeling-based method that assigns larger likelihoods to acoustically constant samples in comparison with these with altered or misaligned options. This system permits for quick and scalable analysis of even giant fashions, making it well-suited for real-world functions. By specializing in a variety of acoustic components similar to sentiment, speaker identification, background noise, and room acoustics, SALMON represents a big innovation in the way in which SLMs are assessed, pushing the boundaries of speech mannequin analysis.
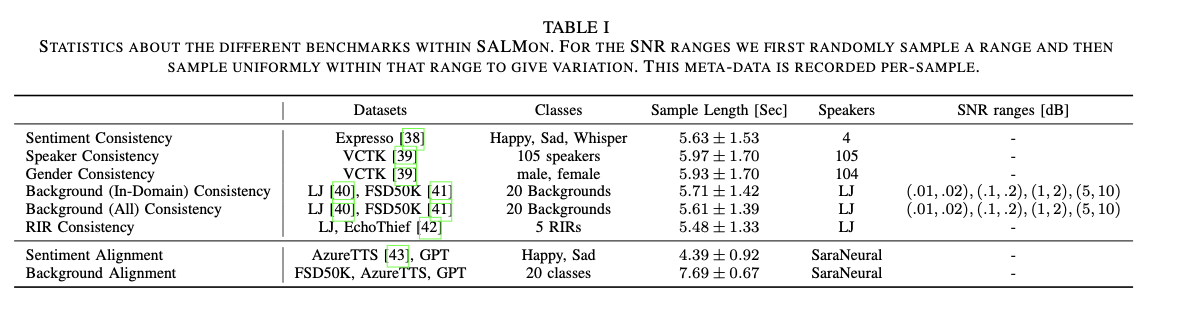
SALMON employs a number of acoustic benchmarks to judge numerous features of speech consistency. These benchmarks use datasets particularly curated to check fashions on dimensions similar to speaker consistency (utilizing the VCTK dataset), sentiment consistency (utilizing the Expresso dataset), and background noise consistency (utilizing LJ Speech and FSD50K). The acoustic consistency process evaluates whether or not the mannequin can preserve options like speaker identification all through a recording or detect adjustments in room acoustics. For instance, within the room impulse response (RIR) consistency process, a speech pattern is recorded with completely different room acoustics in every half of the clip, and the mannequin should appropriately determine this variation.
Within the acoustic-semantic alignment process, the suite challenges fashions to match the background atmosphere or sentiment of the speech with the suitable acoustic cues. For instance, if the speech refers to a “calm seaside,” the mannequin ought to assign the next chance to a recording with ocean sounds than one with building noise. This alignment is examined utilizing knowledge synthesized from Azure Textual content-to-Speech methods and curated via guide filtering to make sure clear and unambiguous examples. The benchmarks are computationally environment friendly, as they don’t require human intervention or further fashions throughout runtime, making SALMON a scalable answer for evaluating SLMs throughout a variety of acoustic environments.
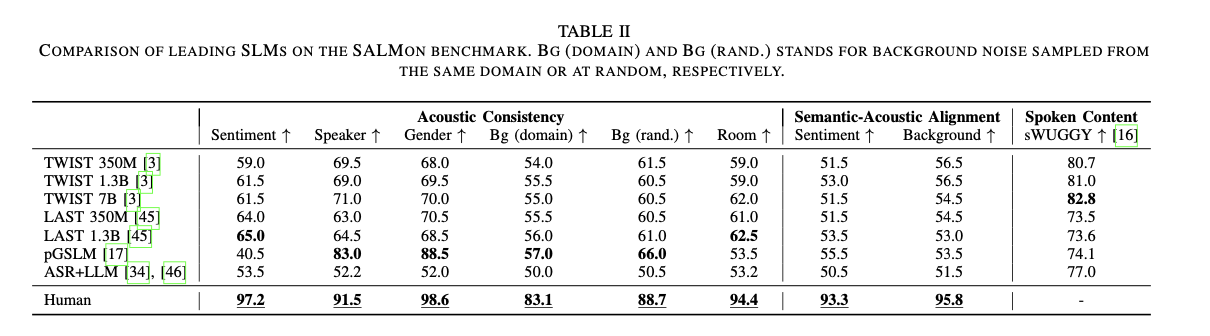
The analysis of a number of Speech Language Fashions (SLMs) utilizing SALMON revealed that whereas present fashions can deal with fundamental acoustic duties, they considerably underperform in comparison with people in additional advanced acoustic-semantic duties. Human evaluators persistently scored above 90% on duties similar to sentiment alignment and background noise detection, whereas fashions like TWIST 7B and pGSLM achieved far decrease accuracy ranges, typically performing solely marginally higher than random probability. For less complicated duties, similar to gender consistency, fashions like pGSLM carried out higher, reaching 88.5% accuracy. Nonetheless, on more difficult duties that require nuanced acoustic understanding, similar to detecting room impulse responses or sustaining acoustic consistency throughout various environments, even the most effective fashions lagged far behind human capabilities. These outcomes point out a transparent want for enchancment within the capacity of SLMs to collectively mannequin semantic and acoustic options, emphasizing the significance of advancing acoustic-aware fashions for future functions.
In conclusion, SALMON supplies a complete suite for evaluating acoustic modeling in Speech Language Fashions, addressing the hole left by conventional analysis strategies that focus totally on textual consistency. By introducing benchmarks that assess acoustic consistency and semantic-acoustic alignment, SALMON permits researchers to determine the strengths and weaknesses of fashions in numerous acoustic dimensions. The outcomes show that whereas present fashions can deal with some duties, they fall considerably wanting human efficiency in additional advanced eventualities. Consequently, SALMON is predicted to information future analysis and mannequin growth in direction of extra acoustic-aware and contextually enriched fashions, pushing the boundaries of what SLMs can obtain in real-world functions.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 50k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about knowledge science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


