
Deep reinforcement studying (RL) focuses on brokers studying to realize a aim. These brokers are educated utilizing algorithms that stability exploration of the surroundings with the exploitation of recognized methods to maximise cumulative rewards. A important problem inside deep reinforcement studying is the efficient scaling of mannequin parameters. Often, growing the dimensions of a neural community results in higher efficiency in supervised studying duties. Nevertheless, this development should be extra easy to translate to RL, the place bigger networks can degrade efficiency as a substitute of bettering it.
Present approaches in deep RL typically contain subtle strategies like auxiliary losses, distillation, and pre-training to stabilize studying and enhance mannequin efficiency. Regardless of these efforts, deep RL fashions underutilize their parameters, resulting in suboptimal efficiency scaling with elevated mannequin dimension. This means a niche in our understanding and utilization of neural community capacities inside RL.
Researchers from DeepMind, Mila – Québec AI Institute, Université de Montréal, together with the College of Oxford and McGill College have launched using Combination-of-Specialists (MoE) modules, particularly Mushy MoEs, as a novel method to deal with the parameter scaling problem in deep RL. These modules are built-in into value-based networks, exhibiting promising outcomes by considerably enhancing the fashions’ parameter effectivity and efficiency throughout numerous sizes and coaching situations.
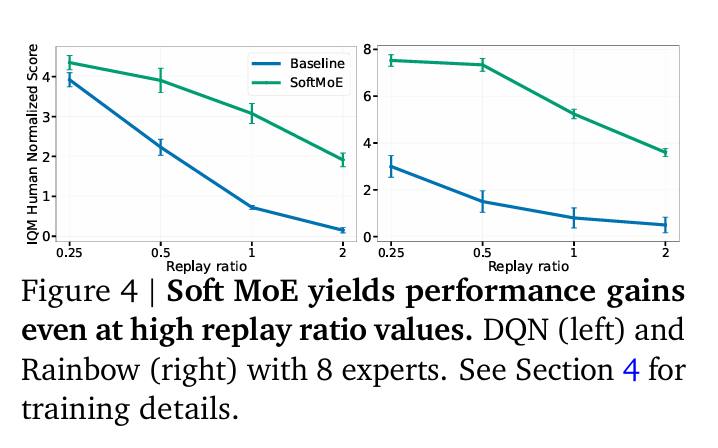
The researchers reveal that utilizing MoEs in RL networks results in extra parameter-scalable fashions, leading to vital efficiency enhancements throughout numerous coaching regimes and mannequin sizes. Researchers additionally consider the efficiency of Deep Q-Community (DQN) and Rainbow algorithms with Mushy MoE and Top1-MoE on the usual Arcade Studying Surroundings (ALE) benchmark. The outcomes point out that incorporating MoEs in deep RL networks can enhance efficiency in several coaching regimes, together with low-data coaching and offline RL duties. The experiments utilized NVIDIA Tesla P100 GPUs, and every experiment took a median of 4 days to finish. The analysis additionally explores the influence of architectural design selections on the efficiency of RL brokers, highlighting the potential benefits of utilizing MoEs. The implementation of the examine is constructed on the Dopamine library. It follows suggestions for statistically sturdy efficiency evaluations, together with interquartile imply (IQM) and stratified bootstrap confidence intervals.
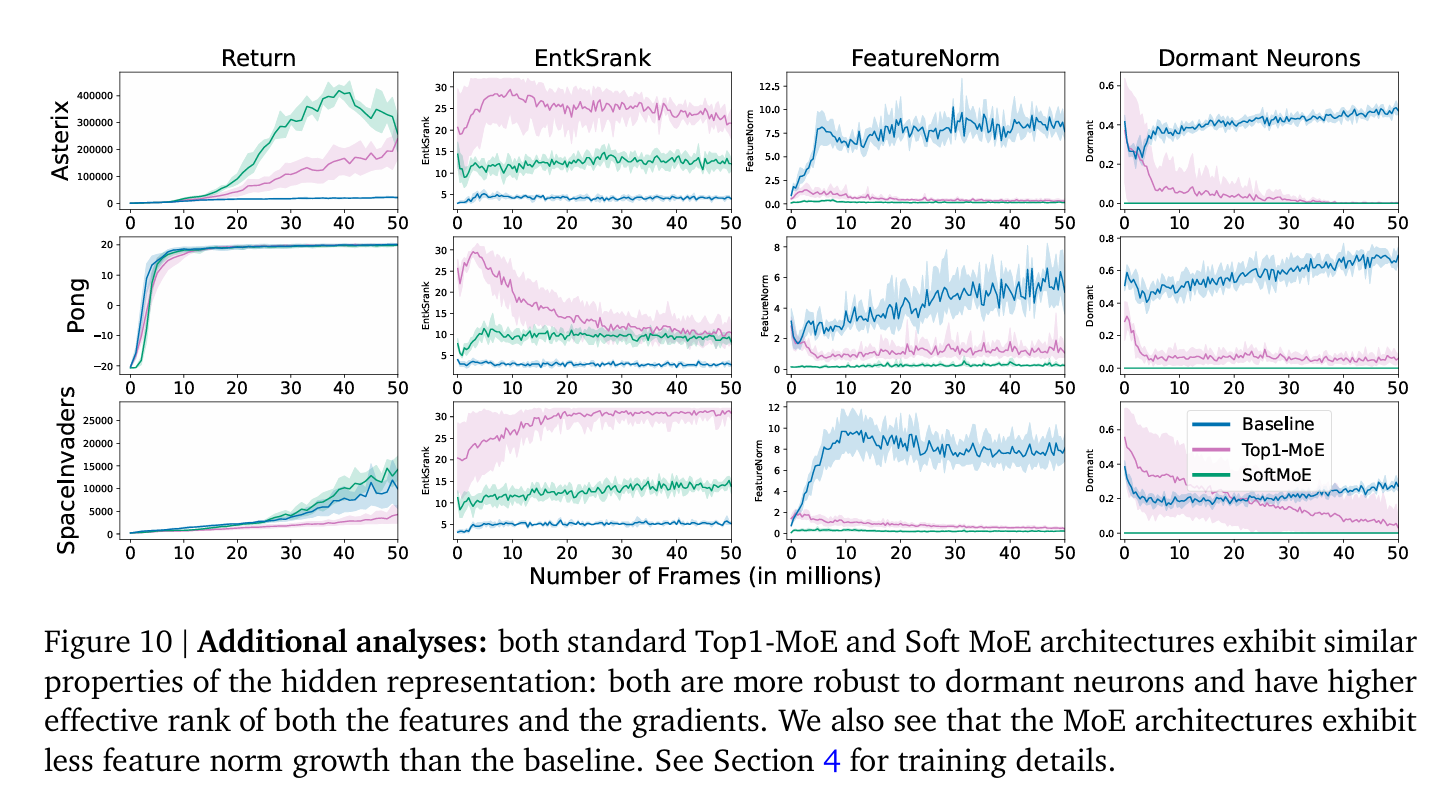
The outcomes illustrate vital efficiency enhancements. A noteworthy discovering is the 20% efficiency uplift within the Rainbow algorithm with the scaling of consultants from 1 to eight, underscoring the scalability and effectivity of Mushy MoEs. Evaluations on the ALE benchmark additional confirmed the optimistic influence of MoEs on DQN and Rainbow algorithms. Furthermore, Mushy MoE emerged as a superior technique. It achieved an optimum stability between accuracy and computational value, exhibiting promise in numerous coaching settings, together with low-data and offline RL duties. These findings, rooted in sturdy statistical analysis strategies, underscore the transformative potential of MoEs in enhancing RL agent efficiency.
The analysis conclusively exhibits that MoE modules, particularly Mushy MoEs, considerably improve parameter scalability and efficiency in RL networks. These findings pave the way in which for creating scaling legal guidelines in RL and underscore MoEs’ very important function in advancing RL agent capabilities. Wanting forward, investigating MoEs’ results throughout numerous RL algorithms and mixing them with different architectural improvements presents a promising avenue for analysis. Additional exploration into the mechanisms behind MoEs’ success in RL may result in extra subtle and environment friendly RL fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our publication..
Don’t Overlook to hitch our Telegram Channel
You might also like our FREE AI Programs….
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


