
One of many important challenges in AI analysis is the computational inefficiency in processing visible tokens in Imaginative and prescient Transformer (ViT) and Video Imaginative and prescient Transformer (ViViT) fashions. These fashions course of all tokens with equal emphasis, overlooking the inherent redundancy in visible knowledge, which leads to excessive computational prices. Addressing this problem is essential for the deployment of AI fashions in real-world functions the place computational assets are restricted and real-time processing is crucial.
Present strategies like ViTs and Combination of Specialists (MoEs) fashions have been efficient in processing large-scale visible knowledge however include important limitations. ViTs deal with all tokens equally, resulting in pointless computations. MoEs enhance scalability by conditionally activating components of the community, thus sustaining inference-time prices. Nevertheless, they introduce a bigger parameter footprint and don’t cut back computational prices with out skipping tokens completely. Moreover, these fashions usually use specialists with uniform computational capacities, limiting their means to dynamically allocate assets based mostly on token significance.
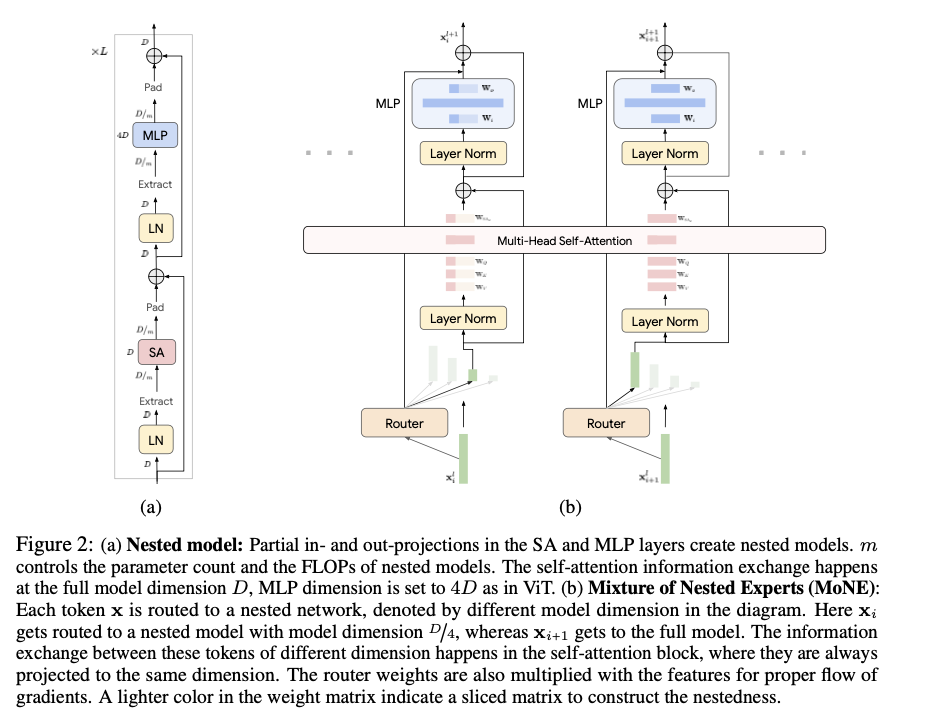
A group of researchers from Google DeepMind and the College of Washington suggest the Combination of Nested Specialists (MoNE) framework, which leverages a nested construction for specialists to handle the inefficiencies of present strategies. MoNE dynamically allocates computational assets by routing tokens to completely different nested specialists based mostly on their significance. This method permits redundant tokens to be processed by means of smaller, cheaper fashions whereas extra essential tokens are routed to bigger, extra detailed fashions. The novelty lies in utilizing a nested structure that maintains the identical parameter rely because the baseline fashions however achieves a two-fold discount in inference time compute. This adaptive processing not solely enhances effectivity but additionally retains efficiency throughout completely different computational budgets.
MoNE integrates a nested structure inside Imaginative and prescient Transformers, the place specialists with various computational capacities are organized hierarchically. Every token is dynamically routed to an acceptable professional utilizing the Professional Most well-liked Routing (EPR) algorithm. The mannequin processes tokens by means of partial in- and out-projections within the Self-Consideration (SA) and MLP layers, facilitating environment friendly computation. The framework is validated on datasets resembling ImageNet-21K, Kinetics400, and One thing-One thing-v2. The routing selections are made based mostly on the significance of tokens, which is set by the router community’s likelihood distribution. MoNE’s effectiveness is demonstrated by means of rigorous experiments displaying sturdy efficiency throughout completely different inference-time compute budgets.
The proposed technique achieves important enhancements in computational effectivity and efficiency throughout varied datasets. On the ImageNet-21K dataset, MoNE achieves an accuracy of 87.5%, which is a considerable enchancment over the baseline fashions. In video classification duties, resembling these involving the Kinetics400 and One thing-One thing-v2 datasets, MoNE demonstrates a two- to three-fold discount in computational prices whereas sustaining or exceeding the accuracy of conventional strategies. The adaptive processing capabilities of MoNE allow it to take care of sturdy efficiency even underneath constrained computational budgets, showcasing its effectiveness in each picture and video knowledge processing.
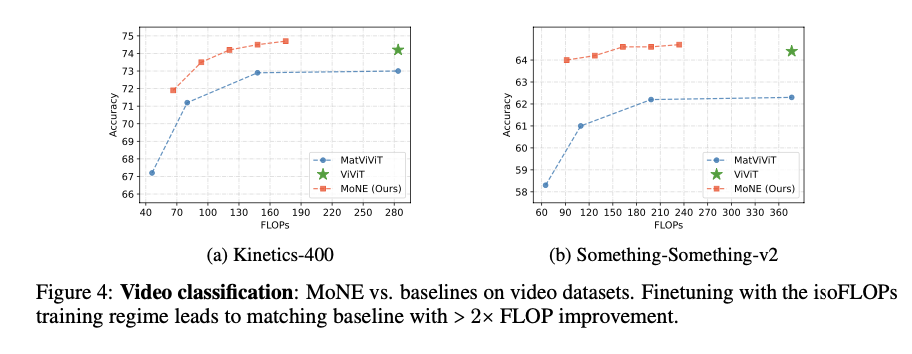
In conclusion, The Combination of Nested Specialists (MoNE) framework presents a major development in processing visible tokens effectively. By dynamically allocating computational assets based mostly on token significance, MoNE overcomes the constraints of present ViT and MoE fashions, attaining substantial reductions in computational prices with out sacrificing efficiency. This innovation holds nice potential for enhancing real-world functions of AI, making high-performance fashions extra accessible and sensible. The contributions are validated by means of rigorous experiments, demonstrating MoNE’s adaptability and robustness throughout completely different datasets and computational budgets.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication..
Don’t Overlook to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s obsessed with knowledge science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.



