
One of many main challenges in AI analysis is verifying the correctness of language fashions (LMs) outputs, particularly in contexts requiring advanced reasoning. As LMs are more and more used for intricate queries that demand a number of reasoning steps, area experience, and quantitative evaluation, guaranteeing the accuracy and reliability of those fashions is essential. This job is especially essential in fields like finance, regulation, and biomedicine, the place incorrect data can result in vital hostile outcomes.
Present strategies for verifying LM outputs embrace fact-checking and pure language inference (NLI) strategies. These strategies sometimes depend on datasets designed for particular reasoning duties, similar to query answering (QA) or monetary evaluation. Nonetheless, these datasets aren’t tailor-made for declare verification, and present strategies exhibit limitations like excessive computational complexity, dependence on massive volumes of labeled knowledge, and insufficient efficiency on duties requiring long-context reasoning or multi-hop inferences. Excessive label noise and the domain-specific nature of many datasets additional hinder the generalizability and applicability of those strategies in broader contexts.
A crew of researchers from Google and Tel Aviv College proposed CoverBench, a benchmark particularly designed for evaluating advanced declare verification throughout various domains and reasoning varieties. CoverBench addresses the restrictions of present strategies by offering a unified format and a various set of 733 examples requiring advanced reasoning, together with long-context understanding, multi-step reasoning, and quantitative evaluation. The benchmark consists of true and false claims vetted for high quality, guaranteeing low ranges of label noise. This novel method permits for a complete analysis of LM verification capabilities, highlighting areas needing enchancment and setting a better customary for declare verification duties.
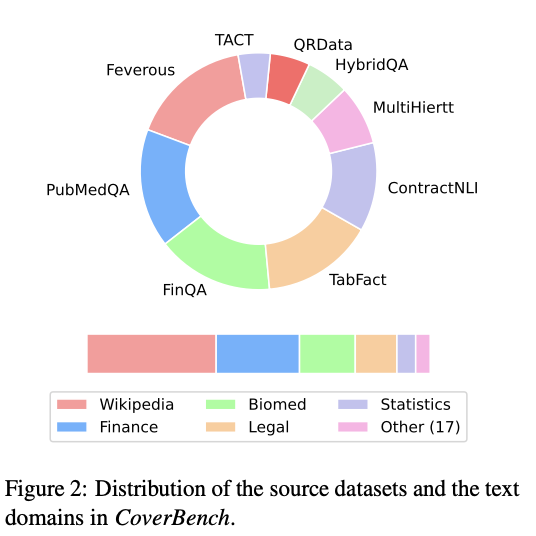
CoverBench includes datasets from 9 completely different sources, together with FinQA, QRData, TabFact, MultiHiertt, HybridQA, ContractNLI, PubMedQA, TACT, and Feverous. These datasets cowl a variety of domains similar to finance, Wikipedia, biomedical, authorized, and statistics. The benchmark includes changing numerous QA duties into declarative claims, standardizing desk representations, and producing damaging examples utilizing seed fashions like GPT-4. The ultimate dataset accommodates lengthy enter contexts, averaging 3,500 tokens, which problem present fashions’ capabilities. The datasets had been manually vetted to make sure the correctness and problem of the claims.
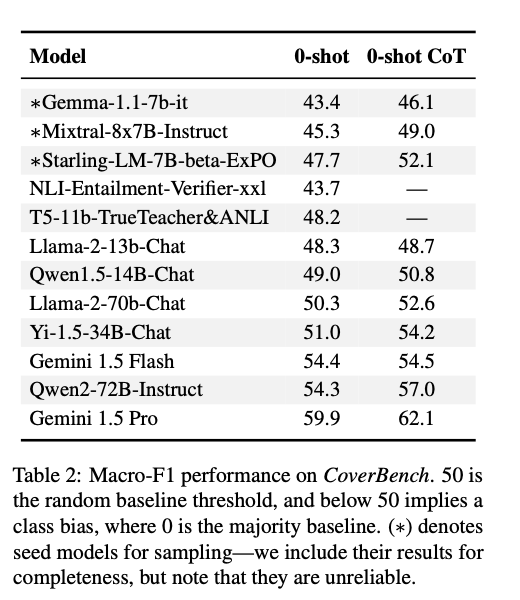
The analysis of CoverBench demonstrates that present aggressive LMs wrestle considerably with the duties offered, reaching efficiency close to the random baseline in lots of cases. The very best-performing fashions, similar to Gemini 1.5 Professional, achieved a Macro-F1 rating of 62.1, indicating substantial room for enchancment. In distinction, fashions like Gemma-1.1-7b-it carried out a lot decrease, underscoring the benchmark’s problem. These outcomes spotlight the challenges LMs face in advanced declare verification and the numerous headroom for developments on this space.
In conclusion, CoverBench considerably contributes to AI analysis by offering a difficult benchmark for advanced declare verification. It overcomes the restrictions of present datasets by providing a various set of duties that require multi-step reasoning, long-context understanding, and quantitative evaluation. The benchmark’s thorough analysis reveals that present LMs have substantial room for enchancment in these areas. CoverBench thus units a brand new customary for declare verification, pushing the boundaries of what LMs can obtain in advanced reasoning duties.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about knowledge science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.



