
Generative AI has made outstanding progress in revolutionizing fields like picture and video era, pushed by modern algorithms, architectures, and information. Nevertheless, the fast proliferation of generative fashions has highlighted a important hole: the absence of reliable analysis metrics. Present computerized assessments similar to FID, CLIP, and FVD typically fail to seize the nuanced high quality and person satisfaction related to generative outputs. Whereas picture era and manipulation applied sciences have superior quickly, enabling functions throughout domains like artwork, visible enhancement, and medical imaging, navigating the multitude of obtainable fashions and assessing their efficiency stays difficult. Conventional metrics like PSNR, SSIM, LPIPS, and FID present useful however particular insights into exact features of visible content material era, typically falling brief in comprehensively evaluating general mannequin efficiency, particularly concerning subjective qualities like aesthetics and person satisfaction.
Quite a few strategies have been proposed to guage the efficiency of multimodal generative fashions throughout varied features. For picture era, strategies like CLIPScore measure text-alignment, whereas IS, FID, PSNR, SSIM, and LPIPS assess picture constancy and perceptual similarity. Latest works use multimodal massive language fashions (MLLMs) as judges, similar to T2I-CompBench utilizing miniGPT4, TIFA adapting visible query answering, and VIEScore reporting MLLMs’ potential to switch human judges. For video era, metrics like FVD measure body coherence and high quality, whereas CLIPSIM makes use of image-text similarity fashions. Nevertheless, these computerized metrics nonetheless lag behind human preferences, with low correlation elevating doubts about their reliability. Generative AI analysis platforms goal to systematically rank fashions, with benchmark suites like T2ICompBench, HEIM, ImagenHub for photos, and VBench, EvalCrafter for movies. Regardless of performance, these benchmarks depend on model-based metrics much less dependable than human analysis. Mannequin arenas have emerged to gather direct human preferences for rating, however no current area focuses particularly on generative AI fashions.
The researchers from the College of Waterloo have launched GenAI-Enviornment, a strong platform designed to allow truthful analysis of generative AI fashions. Impressed by profitable implementations in different domains, GenAI-Enviornment presents a dynamic and interactive platform the place customers can generate photos, examine them side-by-side, and vote for his or her most well-liked fashions. This platform simplifies the method of evaluating completely different fashions and gives a rating system that displays human preferences, providing a extra holistic analysis of mannequin capabilities. GenAI-Enviornment is the primary analysis platform with complete analysis capabilities throughout a number of properties, supporting a variety of duties together with text-to-image era, text-guided picture modifying, and text-to-video era, together with a public voting course of to make sure labeling transparency. The votes are utilized to evaluate the analysis skill of MLLM evaluators. The platform excels in its versatility and transparency. It has collected over 6000 votes for 3 multimodal generative duties and it has constructed leaderboards for every activity, figuring out the state-of-the-art fashions.
GenAI-Enviornment helps text-to-image era, picture modifying, and text-to-video era duties with options like nameless side-by-side voting, battle playground, direct era tab, and leaderboards. The platform standardizes mannequin inference with mounted hyper-parameters and prompts for truthful comparability. It enforces unbiased voting via anonymity, the place customers vote their preferences between anonymously generated outputs, calculating Elo rankings. This structure permits for a democratic, correct evaluation of mannequin efficiency throughout a number of duties.
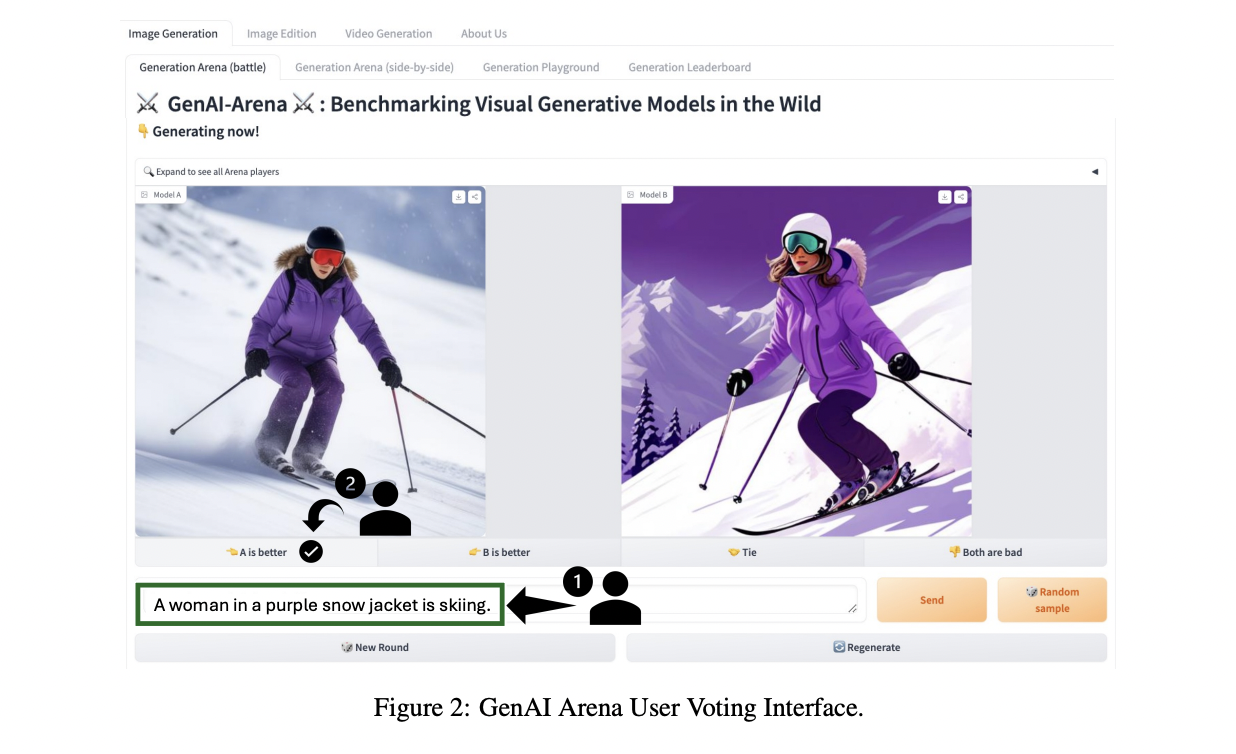
The researchers report their leaderboard rating on the time of writing. For picture era with 4443 votes collected, Playground V2.5 and Playground V2 fashions from Playground.ai high the ranks, following the identical SDXL structure however skilled on a personal dataset, considerably outperforming the Seventh-ranked SDXL which highlights the significance of coaching information. StableCascade using an environment friendly cascade structure ranks subsequent, beating SDXL regardless of solely 10% of SD-2.1’s coaching value, underscoring the significance of diffusion structure. For picture modifying with 1083 votes, MagicBrush, InFEdit, CosXLEdit, and InstructPix2Pix enabling localized modifying rank greater, whereas older strategies like Immediate-to-Immediate producing fully completely different photos rank decrease regardless of high-quality outputs. In text-to-video with 1568 votes, T2VTurbo leads with the best Elo rating as the best mannequin, adopted carefully by StableVideoDiffusion, VideoCrafter2, AnimateDiff, and others like LaVie, OpenSora, ModelScope with lowering efficiency.
On this examine, GenAI-Enviornment, an open platform pushed by group voting is launched to rank generative fashions throughout text-to-image, picture modifying, and text-to-video duties primarily based on person preferences for transparency. Over 6000 votes collected from February to June 2024 have been used to compile Elo leaderboards, figuring out state-of-the-art fashions whereas evaluation revealed potential biases. The high-quality human choice information was launched as GenAI-Bench, exposing the poor correlation of current multimodal language fashions with human judgments on generated content material high quality and different features.
Take a look at the Paper and HF Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 44k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


