
Giant Language Fashions (LLMs) have change into integral to quite a few AI techniques, showcasing exceptional capabilities in numerous functions. Nonetheless, because the demand for processing long-context inputs grows, researchers face important challenges in optimizing LLM efficiency. The flexibility to deal with intensive enter sequences is essential for enhancing AI brokers’ performance and bettering retrieval augmented technology methods. Whereas latest developments have expanded LLMs’ capability to course of inputs of as much as 1M tokens, this comes at a considerable value in computational sources and time. The first problem lies in accelerating LLM technology velocity and decreasing GPU reminiscence consumption for long-context inputs, which is crucial for minimizing response latency and rising throughput in LLM API calls. Though methods like KV cache optimization have improved the iterative technology section, the immediate computation section stays a major bottleneck, particularly as enter contexts lengthen. This prompts the important query: How can researchers speed up velocity and cut back reminiscence utilization through the immediate computation section?
Prior makes an attempt to speed up LLM technology velocity with lengthy context inputs have primarily targeted on KV cache compression and eviction methods. Strategies like selective eviction of long-range contexts, streaming LLM with consideration sinks, and dynamic sparse indexing have been developed to optimize the iterative technology section. These approaches intention to scale back reminiscence consumption and working time related to the KV cache, particularly for prolonged inputs.
Some methods, comparable to QuickLLaMA and ThinK, classify and prune the KV cache to protect solely important tokens or dimensions. Others, like H2O and SnapKV, deal with retaining tokens that contribute considerably to cumulative consideration or are important primarily based on commentary home windows. Whereas these strategies have proven promise in optimizing the iterative technology section, they don’t deal with the bottleneck within the immediate computation section.
A unique method includes compressing enter sequences by pruning redundancy within the context. Nonetheless, this technique requires retaining a considerable portion of enter tokens to keep up LLM efficiency, limiting its effectiveness for important compression. Regardless of these developments, the problem of concurrently decreasing working time and GPU reminiscence utilization throughout each the immediate computation and iterative technology phases stays largely unaddressed.
Researchers from College of Wisconsin-Madison, Salesforce AI Analysis, and The College of Hong Kong current GemFilter, a novel perception into how LLMs course of info. This method is predicated on the commentary that LLMs usually establish related tokens within the early layers, even earlier than producing a solution. GemFilter makes use of these early layers, known as “filter layers,” to compress lengthy enter sequences considerably.
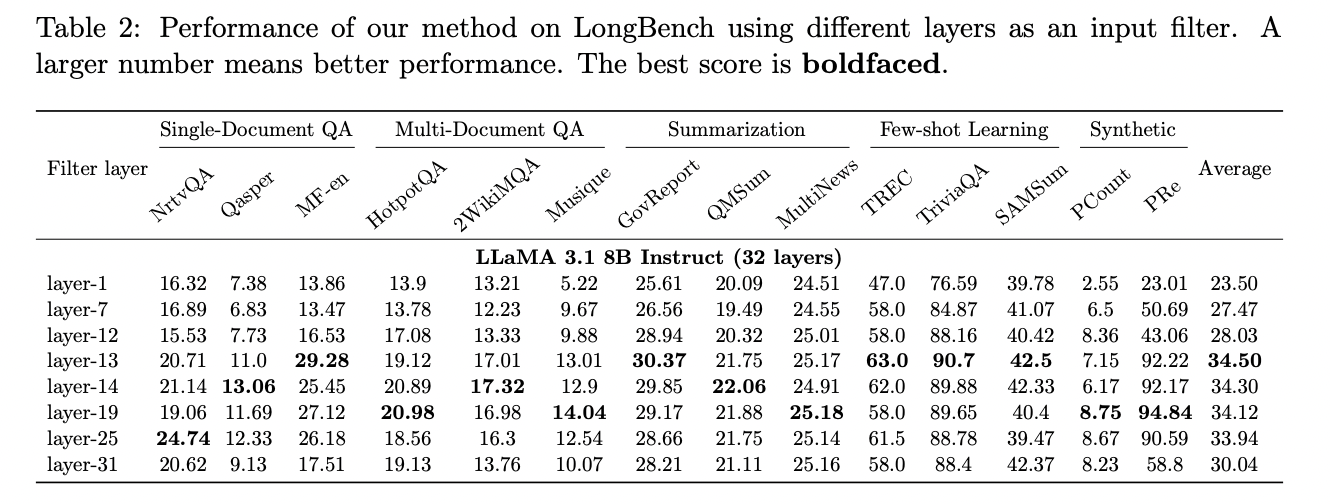
The strategy works by analyzing the eye matrix from these early layers to distil the mandatory info for answering queries. As an example, within the LLaMA 3.1 8B mannequin, the thirteenth to nineteenth layers can successfully summarize the required info. This enables GemFilter to carry out immediate computation on lengthy context inputs just for these filter layers, compressing the enter tokens from as many as 128K to simply 100.
By deciding on a subset of tokens primarily based on the eye patterns in these early layers, GemFilter achieves substantial reductions in each processing time and GPU reminiscence utilization. The chosen tokens are then fed into the total mannequin for inference, adopted by customary technology features. This method addresses the bottleneck within the immediate computation section whereas sustaining efficiency akin to current strategies within the iterative technology section.
GemFilter’s structure is designed to optimize LLM efficiency by leveraging early layer processing for environment friendly token choice. The strategy makes use of the eye matrices from early layers, particularly the “filter layers,” to establish and compress related enter tokens. This course of includes analyzing the eye patterns to pick a small subset of tokens that include the important info wanted for the duty.
The core of GemFilter’s structure is its two-step method:
1. Token Choice: GemFilter makes use of the eye matrix from an early layer (e.g., the thirteenth layer in LLaMA 3.1 8B) to compress the enter tokens. It selects the highest okay indices from the final row of the eye matrix, successfully decreasing the enter measurement from doubtlessly 128K tokens to round 100 tokens.
2. Full Mannequin Inference: The chosen tokens are then processed by means of all the LLM for full inference, adopted by customary technology features.
This structure permits GemFilter to realize important speedups and reminiscence reductions through the immediate computation section whereas sustaining efficiency within the iterative technology section. The strategy is formulated in Algorithm 1, which outlines the precise steps for token choice and processing. GemFilter’s design is notable for its simplicity, lack of coaching necessities, and broad applicability throughout numerous LLM architectures, making it a flexible resolution for bettering LLM effectivity.
GemFilter’s structure is constructed round a two-pass method to optimize LLM efficiency. The core algorithm, detailed in Algorithm 1, consists of the next key steps:
1. Preliminary Ahead Move: The algorithm runs solely the primary r layers of the m-layer transformer community on the enter sequence T. This step generates the question and key matrices (Q(r) and Okay(r)) for the r-th layer, which serves because the filter layer.
2. Token Choice: Utilizing the eye matrix from the r-th layer, GemFilter selects the okay most related tokens. That is carried out by figuring out the okay largest values from the final row of the eye matrix, representing the interplay between the final question token and all key tokens.
3. Multi-Head Consideration Dealing with: For multi-head consideration, the choice course of considers the summation of the final row throughout all consideration heads’ matrices.
4. Token Reordering: The chosen tokens are then sorted to keep up their authentic enter order, guaranteeing correct sequence construction (e.g., preserving the <bos> token firstly).
5. Ultimate Era: The algorithm runs a full ahead go and technology operate utilizing solely the chosen okay tokens, considerably decreasing the enter context size (e.g., from 128K to 1024 tokens).
This method permits GemFilter to effectively course of lengthy inputs by leveraging early layer info for token choice, thereby decreasing computation time and reminiscence utilization in each the immediate computation and iterative technology phases.

GemFilter demonstrates spectacular efficiency throughout a number of benchmarks, showcasing its effectiveness in dealing with long-context inputs for LLMs.
Within the Needle in a Haystack benchmark, which assessments LLMs’ capability to retrieve particular info from intensive paperwork, GemFilter considerably outperforms each customary consideration (All KV) and SnapKV strategies. This superior efficiency is noticed for each Mistral Nemo 12B Instruct and LLaMA 3.1 8B Instruct fashions, with enter lengths of 60K and 120K tokens respectively.
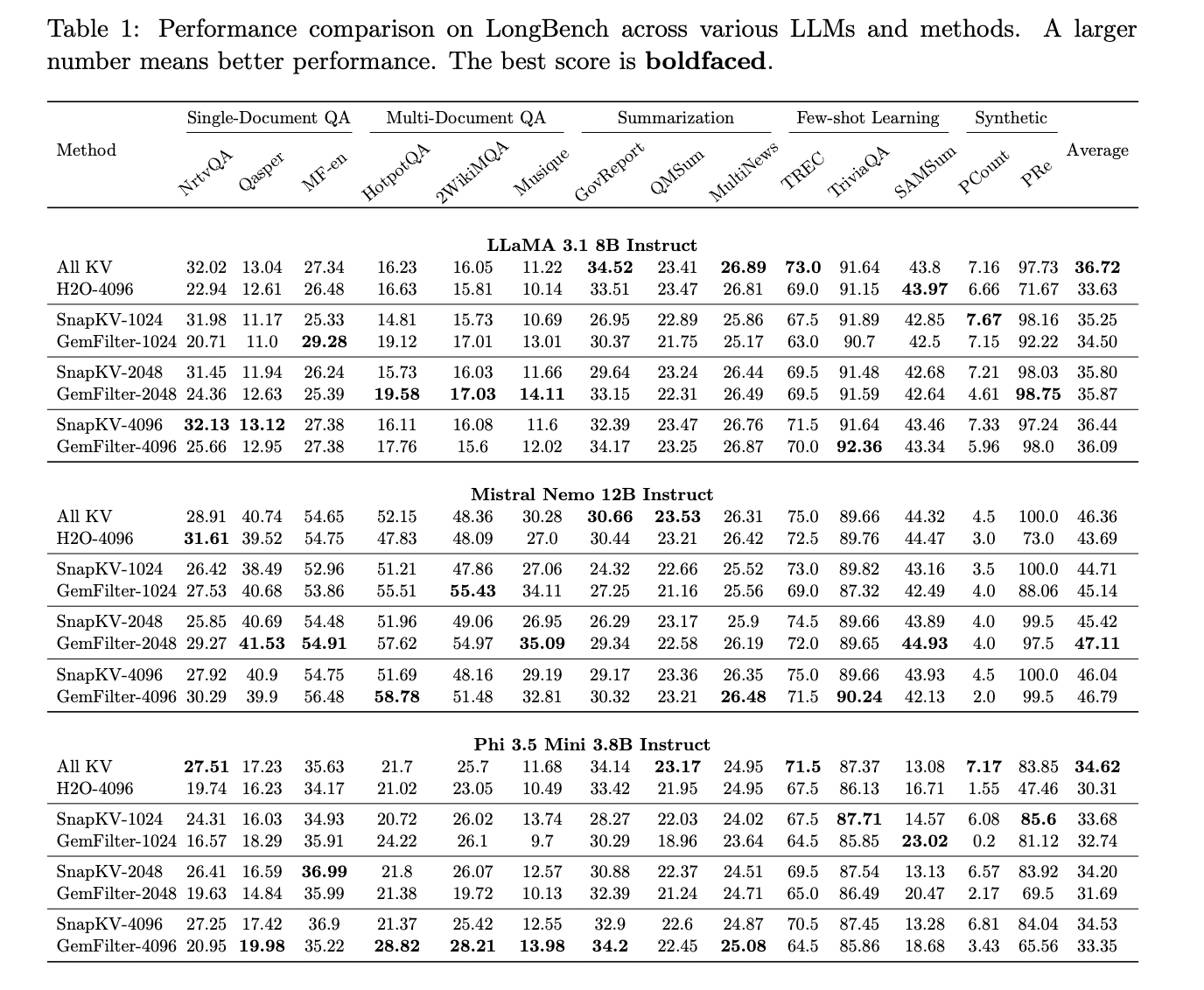
On the LongBench multi-task benchmark, which evaluates long-context understanding throughout numerous duties, GemFilter reveals comparable or higher efficiency to plain consideration, even when utilizing solely 1024 chosen tokens. As an example, GemFilter-2048 outperforms customary consideration for the Mistral Nemo 12B Instruct mannequin. GemFilter additionally demonstrates considerably higher efficiency than H2O and comparable efficiency to SnapKV.
Notably, GemFilter achieves these outcomes whereas successfully compressing enter contexts. It reduces enter tokens to a mean of 8% when utilizing 1024 tokens, and 32% when utilizing 4096 tokens, with negligible accuracy drops. This compression functionality, mixed with its capability to filter key info and supply interpretable summaries, makes GemFilter a strong device for optimizing LLM efficiency on long-context duties.
GemFilter demonstrates important enhancements in computational effectivity and useful resource utilization. In comparison with current approaches like SnapKV and customary consideration, GemFilter achieves a 2.4× speedup whereas decreasing GPU reminiscence utilization by 30% and 70%, respectively. This effectivity acquire stems from GemFilter’s distinctive three-stage processing method, the place the lengthy enter context is dealt with solely through the preliminary stage. Subsequent phases function on compressed inputs, resulting in substantial useful resource financial savings. Experiments with Mistral Nemo 12B Instruct and Phi 3.5 Mini 3.8B Instruct fashions additional affirm GemFilter’s superior efficiency by way of working time and GPU reminiscence consumption in comparison with state-of-the-art strategies.
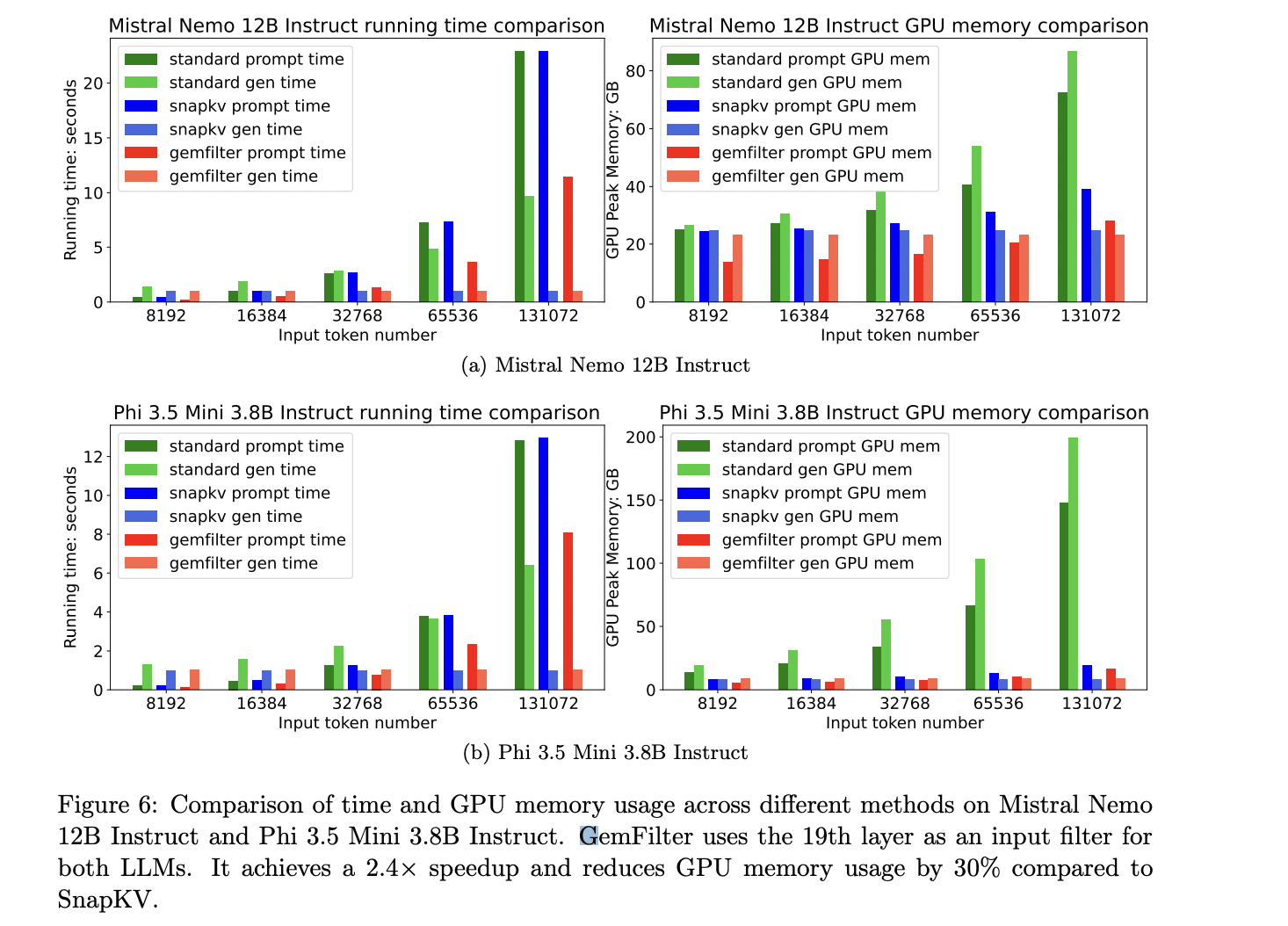
This examine presents GemFilter, a sturdy method to reinforce LLM inference for lengthy context inputs, addressing important challenges in velocity and reminiscence effectivity. By harnessing the capabilities of early LLM layers to establish related info, GemFilter achieves exceptional enhancements over current methods. The strategy’s 2.4× speedup and 30% discount in GPU reminiscence utilization, coupled with its superior efficiency on the Needle in a Haystack benchmark, underscore its effectiveness. GemFilter’s simplicity, training-free nature, and broad applicability to varied LLMs make it a flexible resolution. Furthermore, its enhanced interpretability by means of direct token inspection provides helpful insights into LLM inside mechanisms, contributing to each sensible developments in LLM deployment and deeper understanding of those advanced fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication.. Don’t Overlook to affix our 50k+ ML SubReddit
Excited about selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


