
Approximate nearest neighbor search (ANNS) is a essential expertise that powers numerous AI-driven purposes comparable to knowledge mining, engines like google, and advice techniques. The first goal of ANNS is to determine the closest vectors to a given question in high-dimensional areas. This course of is important in contexts the place discovering related objects shortly is essential, comparable to picture recognition, pure language processing, and large-scale advice engines. Nonetheless, as knowledge sizes enhance to billions of vectors, ANNS techniques face appreciable challenges by way of efficiency and scalability. Effectively managing these datasets requires important computational and reminiscence assets, making it a extremely complicated and expensive endeavor.
The primary difficulty this analysis addresses is that current ANNS options typically need assistance to deal with the immense scale of recent datasets whereas sustaining effectivity and accuracy. Conventional approaches are insufficient for billion-scale knowledge as a result of they demand excessive reminiscence utilization and computational energy. Strategies like inverted file (IVF) and graph-based indexing strategies have been developed to deal with these limitations. Nonetheless, they typically require terabyte-scale reminiscence, which makes them costly and resource-intensive. Moreover, the computational complexity of conducting huge distance calculations between high-dimensional vectors in such giant datasets is a bottleneck for present ANNS techniques.
Within the present state of ANNS expertise, memory-intensive strategies comparable to IVF and graph-based indices are ceaselessly employed to construction the search area. Whereas these strategies can enhance question efficiency, in addition they considerably enhance reminiscence consumption, notably for big datasets containing billions of vectors. Hierarchical indexing (HI) methods and Product Quantization (PQ) have optimized reminiscence utilization by storing indices on SSDs and utilizing compressed representations of vectors. Nonetheless, these options may cause extreme efficiency degradation because of the overhead launched by knowledge compression and decompression operations, which can result in accuracy losses. Present techniques like SPANN and RUMMY have demonstrated various levels of success however stay restricted by their incapacity to stability reminiscence consumption and computational effectivity.
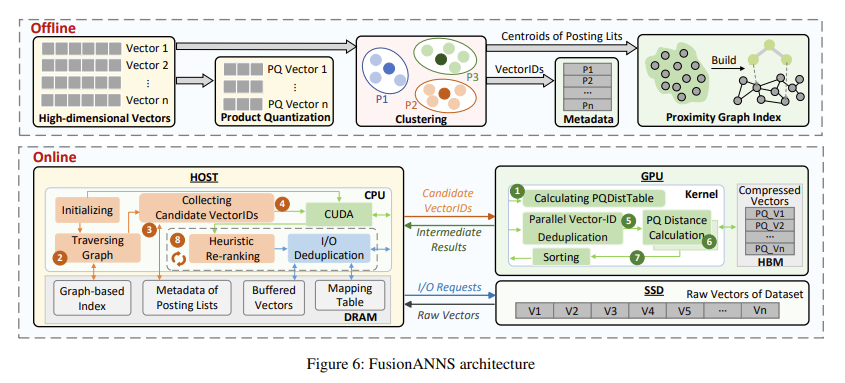
Researchers from Huazhong College of Science and Know-how and Huawei Applied sciences Co., Ltd launched FusionANNS, a brand new CPU/GPU collaborative processing structure designed particularly for billion-scale datasets to deal with these challenges. FusionANNS makes use of an progressive multi-tiered index construction that leverages the strengths of each CPUs and GPUs. This structure permits for top throughput and low-latency approximate nearest neighbor searches utilizing solely a single, entry-level GPU, making it a cheap resolution. The researchers’ method facilities round three core improvements: multi-tiered indexing, heuristic re-ranking, and redundancy-aware I/O deduplication, which decrease knowledge transmission throughout CPUs, GPUs, and SSDs to remove efficiency bottlenecks.
FusionANNS’s multi-tiered indexing construction permits CPU/GPU collaborative filtering by storing uncooked vectors on SSDs, compressed vectors within the GPU’s high-bandwidth reminiscence (HBM), and vector identifiers within the host reminiscence. This construction prevents extreme knowledge swapping between CPUs and GPUs, considerably lowering I/O operations. Heuristic re-ranking additional improves question accuracy by breaking the re-ranking course of into a number of mini-batches and using a suggestions management mechanism to terminate pointless computations early. The ultimate part, redundancy-aware I/O deduplication, teams vectors with excessive similarity into optimized storage layouts, lowering the variety of I/O requests throughout re-ranking by 30% and eliminating redundant I/O operations via efficient caching methods.
Experimental outcomes point out that FusionANNS outperforms state-of-the-art techniques like SPANN and RUMMY throughout numerous metrics. The system achieves as much as 13.1× larger queries per second (QPS) and eight.8× larger price effectivity in comparison with SPANN, and 2-4.9× larger QPS and 6.8× higher price effectivity in comparison with RUMMY. For a dataset containing one billion vectors, FusionANNS can deal with the question course of with a QPS of over 12,000 whereas preserving latency as little as 15 milliseconds. These outcomes show that FusionANNS is extremely efficient for managing billion-scale datasets with out in depth reminiscence assets.
Key takeaways from this analysis embrace:
- Efficiency Enchancment: FusionANNS achieves as much as 13.1× larger QPS and eight.8× higher price effectivity than the state-of-the-art SSD-based system SPANN.
- Effectivity Achieve: It gives 5.7-8.8× larger effectivity in dealing with SSD-based knowledge entry and processing.
- Scalability: FusionANNS can handle billion-scale datasets utilizing just one entry-level GPU and minimal reminiscence assets.
- Value-effectiveness: The system reveals a 2-4.9× enchancment in price effectivity in comparison with current in-memory options like RUMMY.
- Latency Discount: FusionANNS maintains a question latency of 15 milliseconds, considerably decrease than different SSD-based and GPU-accelerated options.
- Innovation in Design: Utilizing multi-tiered indexing, heuristic re-ranking, and redundancy-aware I/O deduplication are groundbreaking contributions that set FusionANNS other than current strategies.

In conclusion, FusionANNS represents a breakthrough in ANNS expertise by delivering excessive throughput, low latency, and superior price effectivity. The researchers’ novel method to CPU/GPU collaboration and multi-tiered indexing affords a sensible resolution for scaling ANNS to help giant datasets. FusionANNS units a brand new customary for dealing with high-dimensional knowledge in real-world purposes by lowering the reminiscence footprint and eliminating pointless computations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 50k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report shall be launched in late October/early November 2024. Click on right here to arrange a name!
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.


