
Generative vision-language fashions (VLMs) have revolutionized radiology by automating the interpretation of medical pictures and producing detailed studies. These developments maintain promise for decreasing radiologists’ workloads and enhancing diagnostic accuracy. Nevertheless, VLMs are susceptible to producing hallucinated content material—nonsensical or incorrect textual content—which may result in scientific errors and elevated workloads for healthcare professionals.
The core subject is the tendency of VLMs to hallucinate references to prior exams in radiology studies. Incorrect references to previous pictures can mislead clinicians, complicate affected person care, and necessitate extra verification and correction efforts by radiologists. This drawback is especially acute in chest X-ray report era, the place such hallucinations can obscure crucial scientific data and improve the chance of affected person hurt if not corrected.
Conventional strategies for mitigating hallucinations in generative fashions embody preprocessing coaching datasets to take away problematic references. This method, whereas efficient, is resource-intensive and can’t appropriate points that come up post-training. Reinforcement studying with human suggestions (RLHF) gives an alternate by aligning mannequin outputs with human preferences, but it surely requires complicated reward fashions. Direct Choice Optimization (DPO), a less complicated and extra environment friendly methodology derived from RLHF, is proposed on this paper to suppress undesirable behaviors in pretrained fashions while not having specific reward fashions.
Researchers from Harvard College, Jawaharlal Institute of Postgraduate Medical Schooling & Analysis, and Johns Hopkins College have proposed a DPO-based methodology particularly tailor-made for suppressing hallucinated references to prior exams in chest X-ray studies. By fine-tuning the mannequin utilizing DPO, the group considerably decreased these undesirable references whereas sustaining scientific accuracy. The strategy entails utilizing a subset of the MIMIC-CXR dataset, edited to take away references to prior exams, for coaching and analysis. This subset was fastidiously curated to make sure it may successfully practice the mannequin to acknowledge and keep away from producing hallucinatory content material.
The proposed methodology employs a vision-language mannequin pretrained on MIMIC-CXR information. The VLM structure features a imaginative and prescient encoder, a vision-language adapter, and a language mannequin. The imaginative and prescient encoder converts enter pictures into visible tokens, which the adapter maps to the language area. These tokens are processed by the language mannequin, which generates the chest X-ray report. Particularly, the mannequin makes use of a Swin Transformer because the imaginative and prescient encoder and Llama2-Chat-7b because the language mannequin, with parameter-efficient tuning utilizing LoRA.
The fine-tuning course of entails creating desire datasets the place most well-liked responses keep away from references to prior exams, and dispreferred responses embody such references. These datasets practice the mannequin with weighted DPO losses, emphasizing the suppression of hallucinated content material. The coaching set included 19,806 research, whereas the validation set comprised 915. The take a look at set consisted of 1,383 research. The DPO coaching dataset was constructed by figuring out dispreferred studies referencing prior exams and creating most well-liked variations by eradicating these references utilizing GPT-4.
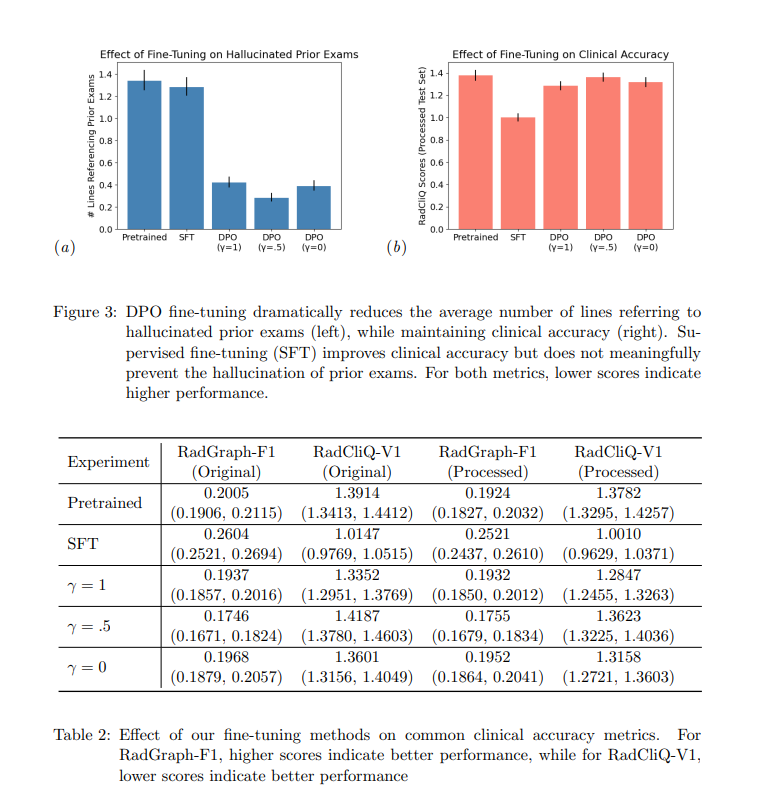
The efficiency of the fine-tuned fashions was evaluated utilizing a number of metrics. The outcomes confirmed a major discount in hallucinated references, with fashions educated utilizing DPO exhibiting a 3.2 to 4.8-fold lower in such errors. Particularly, the best-performing DPO mannequin decreased the common variety of strains referring to prior exams per report from 1.34 to 0.28 and halved the proportion of studies mentioning prior exams from 50% to about 20%. The scientific accuracy of the fashions, assessed utilizing metrics like RadCliq-V1 and RadGraph-F1, remained excessive. For example, the RadCliq-V1 rating for the perfect DPO mannequin was 1.3352 in comparison with 1.3914 for the unique pretrained mannequin, indicating improved alignment with radiologist preferences with out compromising accuracy.
In conclusion, the analysis demonstrates that DPO can successfully suppress hallucinated content material in radiology report era whereas preserving scientific accuracy. This method gives a sensible and environment friendly resolution to enhance the reliability of AI-generated medical studies, in the end enhancing affected person care and decreasing the burden on radiologists. The findings counsel that integrating DPO into VLMs can considerably enhance their utility in scientific settings, making AI-generated studies extra reliable and worthwhile.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 44k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


