
Find out how to OCR pay slips? This weblog is a complete overview of various strategies of extracting structured textual content utilizing OCR from wage pay slips to automate handbook information entry.
What’s a Payslip?
A payslip, paycheck stub, or wage slip is a type or an english doc given by the employer to the worker. It offers a complete account of an worker’s wage and allowances paid to her or him for a given payroll interval. Payslips are crucial to each the employer and the worker because it acts as a pay receipt and in addition in recording the staff’ monetary transactions.
Should you’re a working worker or have been up to now, little doubt you’ve got encountered one. Normally, these payslips comprise particulars equivalent to an worker’s earnings for a selected time, together with different fields like their tax deductions, insurance coverage quantities, social safety numbers and so on. These will be both paper or digital and generally despatched by way of e mail or submit.
At present, lenders get scanned or digital PDFs of those payslips and manually enter particulars from them into their programs to difficulty a mortgage. This course of is time-consuming, particularly throughout peak seasons, resulting in a very long time from mortgage utility to funds being launched. What for those who might scrape PDF variations of those payslips and scale back this time to a couple seconds for sooner mortgage processing to thrill your buyer?
On this weblog, we’ll be reviewing other ways one can automate info extraction of payslips (Payslip OCR or Payslip PDF extract) and save them as structured information utilizing Optical Character Recognition (OCR). Additional, we’ll talk about the frequent challenges we encounter in constructing an correct OCR built-in with Machine studying and deep studying fashions. Beneath is the desk of contents.
What’s Payslip OCR?
Payslip OCR is a method of studying textual content from bodily payslip or scanned payslip and changing it into machine readable type. Given the usage of OCR expertise, the data contained in payslips is extracted mechanically and due to this fact is simpler from the storage, looking out and evaluation standpoints with out requiring re-keying of knowledge.
On this part, we’ll be discussing how we will make use of OCR primarily based algorithms to extract info from payslips. Should you’re not conscious of OCR, consider it as a pc algorithm that may learn pictures of typed or handwritten textual content into textual content format. On the market, there are totally different – free and open-source instruments on GitHub like Tesseract, Ocropus, Kraken, however have sure limitations. For instance, Tesseract may be very correct in extracting organised textual content, nevertheless it doesn’t carry out properly on unstructured information. Equally, the opposite OCR instruments have a number of limitations primarily based on the fonts, language, alignment, templates and so on. Now, coming again to our downside of extracting info from Payslips, a great OCR ought to be capable of pull all of the important fields, regardless of the above-discussed drawbacks. Now, earlier than establishing an OCR, let’s have a look at the usual fields that we have to extract from a Payslip doc.
A fundamental payslip consists of a variety of personalized line gadgets that supply specifics of an worker’s remuneration. Frequent fields embrace:
- Web Pay: Declared receipts after different obligatory subtractions have been made.
- Deductions: As an illustration, taxes, insurance coverage, obligatory pension scheme, and different dues which might be paid to the federal government or different related our bodies.
- Bonuses and Additional time: Financial incentives aside from pay which might be supplied on prime of established charges.
- Employer Contributions: Employer’s price for advantages equivalent to pension plan or medical bills.
- Checking account
- Employer identify
- Employer tackle
- Worker Data: Full authorized identify and alias, worker quantity, organizational subdivision/division, and place.
- Worker identify
- Worker quantity
- Worker tackle
- Wage Interval: The time when the worker was being paid or the beginning and finish dates of the pay interval.
- Date of delivery
- Days labored
- Hours labored
- In / out service date
- Hourly charge
- Tax charge
- Date of difficulty
- Depart Balances: Balanced particulars of the go away that has been amassed and used.
Earlier than we arrange an OCR and look into outputs, we should realise that OCR would not know what sort of paperwork we’re giving them to extract, they blindly determine the textual content and return them regardless of fields or identifiers talked about above. Now, we’ll use Tesseract, which is a free and open-source OCR engine by Google. To study extra about configuring this in your system, and creating python scripts for scanned pictures, take a look at our information on Tesseract right here.
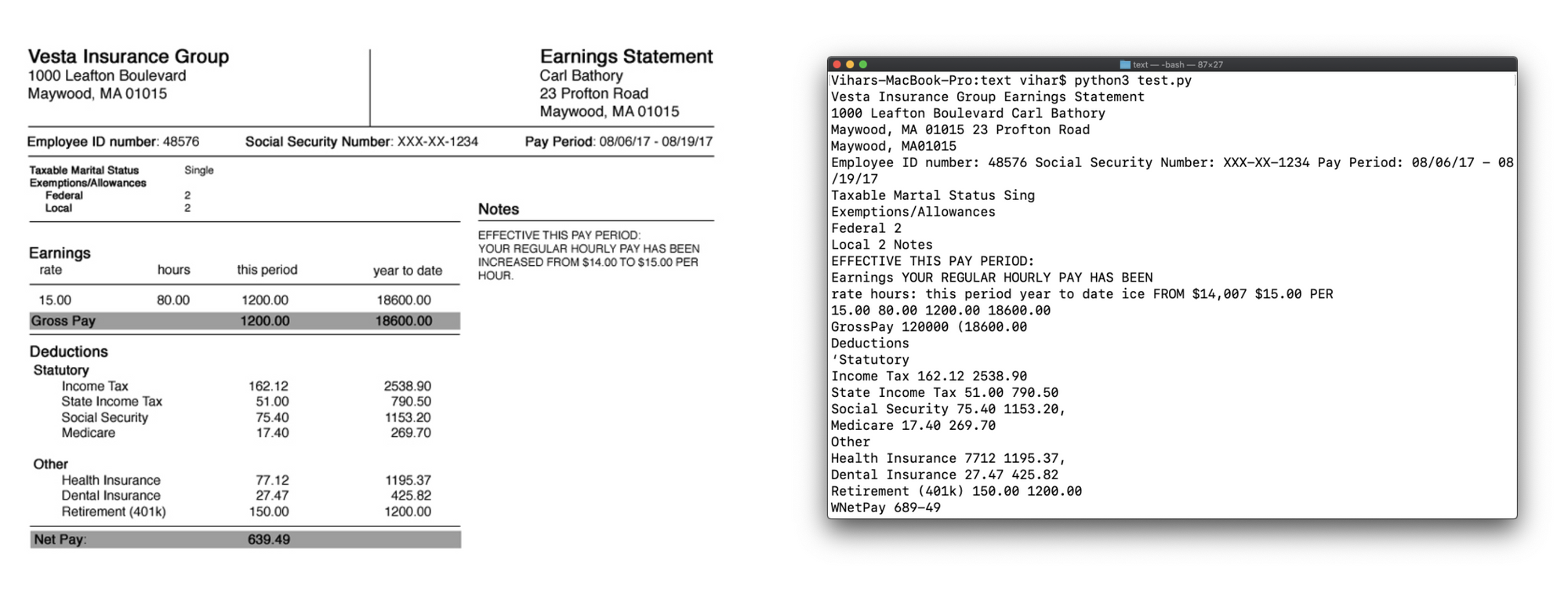
As we will clearly see, Tesseract recognized all of the textual content within the given picture, regardless of tables, positions and alignment of textual content and printed it out precisely. But it surely takes a whole lot of postprocessing to choose all of the necessary fields and put them in a structured manner. For instance, say you solely must extract the tax deducted for an worker, Tesseract alone can not do it. That is the place machine studying and deep studying fashions come into the image to intelligently determine the placement of the fields and extract obligatory values. We name this as key-value pair extraction, let’s talk about how we will obtain this within the subsequent sections.

Advantages of Payslip OCR
Payslip OCR provides a number of benefits for each companies and staff:
Effectivity: It eliminates the effort and time wanted to do copy and paste entries on totally different functions.
Accuracy: Reduces errors usually incurred when keying within the information, and therefore, improves the standard of knowledge.
Comfort: Facilitates placing payslip particulars into storage, discovering it, and getting it out when wanted.
Price Financial savings: Eliminates the prices incurred in dealing with and preserving bodily payslips therefore making the method simpler and environment friendly.
Integration: Allows the payslip particular information to be interfaced with different digital contexts like payroll utility or the monetary software program.
Scalability: Can course of numerous Payslips which implies it may be utilized in organizations of various varieties and sizes.
Now, it has change into potential to use OCR expertise for the aim of simplification of the group’s payroll processes, growing the accuracy degree of knowledge, in addition to growing general productiveness of the corporate.
Drawbacks and Challenges
Whereas scanning pay slips, we encounter totally different points like capturing in flawed angles or dim lighting situations. Additionally, after they’re captured, it is equally necessary to examine if they’re authentic or faked. On this part, we’ll talk about these essential challenges and the way they are often addressed.
Improper Scanning
It is the most typical downside whereas performing OCR. For prime-quality scanned and aligned pictures, the OCR has a excessive accuracy of manufacturing completely searchable editable textual content. Nonetheless, when a scan is distorted or when the textual content is blurred, OCR instruments may need problem studying it, sometimes making inaccurate outcomes. To beat this, we have to be aware of strategies like picture transforms and de-skewing, which assist us align the picture in a correct place.
Fraud & Blurry Picture Checks
It’s necessary for corporations and staff to examine if pay slips are genuine or not. These are among the traits which will help us examine if the picture is pretend or not.
- Establish backgrounds for bent or distorted elements.
- Watch out for low-quality pictures.
- Verify for blurred or edited texts.
One algorithm that is acquainted to beat this job is the “Variance of Laplacian.” It helps us discover and study the distribution of high and low frequencies within the given picture.
As mentioned above, key-value extraction will seek for user-defined keys which might be static textual content on types after which determine the related values to them. To attain this system first, one have to be aware of Deep Studying. We’ll additionally must be sure that these deep studying algorithms are relevant for various templates, as in the identical algorithm must be applicable for paperwork of different codecs. After the algorithm finds the place of required keys and values, we then use OCR to extract the textual content from it.
Right here is an instance of how tesseract extracts textual content,
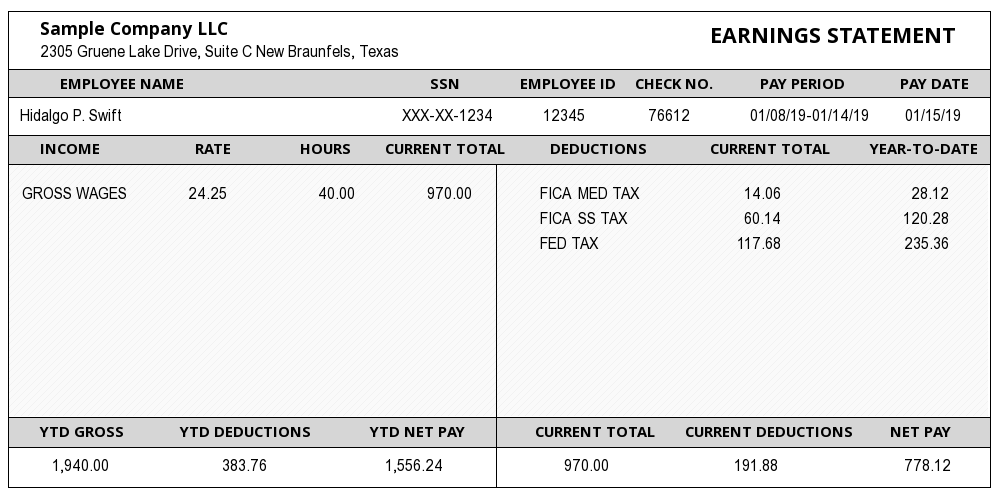
Pattern Firm LLC EARNINGS STATEMENT
2305 Gruene Lake Drive, Suite C New Braunfels, Texas
Hidalgo P. Swift XXX-XX-1234 12345 76612 01/08/19-01/14/19 0115/19
GROSS WAGES 24.25 40.00 970.00 FICA MED TAX 14.06 28.12
FICA SS TAX 60.14 120.28
FED TAX 117.68 235.36
1,940.00 383.76 1,556.24 970.00 191.88 778.12
Whereas for key worth pair extraction we’ll have a a JSON output of the required keys and values of the given pay slip. The output JSON information will be saved as structured information into excel sheets, databases and CRM programs through the use of easy automation scripts. Within the subsequent part, we’ll talk about a couple of deep studying strategies for key-value pair extraction on paperwork like Pay slips.
Deep Studying Fashions for Pay slip IE
There are two methods for info extraction utilizing deep studying, one constructing algorithms that may study from pictures, and the opposite from the textual content.
Alright, now let’s dive into some deep studying and perceive how these algorithms determine key-value pairs from pictures or textual content. Additionally particularly for pay slips, it is important to extract the info within the tables, as many of the earnings and deductions in a pay slip are talked about in tabular format. Now, let’s assessment a couple of fashionable deep studying architectures for scanned paperwork.
Within the analysis, CUTIE (Studying to Perceive Paperwork with Convolutional Common Textual content Data Extractor), Xiaohui Zhao proposed extracting key info from paperwork, equivalent to receipts or invoices, and preserving the attention-grabbing texts to structured information. The guts of this analysis is the convolutional neural networks, that are utilized to texts. Right here, the texts are embedded as options with semantic connotations. This mannequin is skilled on 4, 484 labelled receipts and has achieved 90.8%, 77.7% common precision on taxi receipts and leisure receipts, respectively.
BERTgrid is a well-liked deep learning-based language mannequin for understanding generic paperwork and performing key-value pair extraction duties. This mannequin additionally makes use of convolutional neural networks primarily based on semantic occasion segmentation for working the inference. Total the imply accuracy on chosen doc header and line gadgets was 65.48%.
In DeepDeSRT, Schreiber et al. offered the tip to finish system for desk understanding in doc pictures. The system incorporates two subsequent fashions for desk detection and structured information extraction within the acknowledged tables. It outperformed state-of-the-art strategies for desk detection and construction recognition by attaining F1-measures of 96.77% and 91.44% for desk detection and construction recognition, respectively. Fashions like these can be utilized to extract values from tables of pay slips completely.
Wish to discover out extra about how Nanonets can remodel your payroll processes?


