
Giant Language Fashions (LLMs) signify a revolutionary leap in quite a few utility domains, facilitating spectacular accomplishments in various duties. But, their immense measurement incurs substantial computational bills. With billions of parameters, these fashions demand in depth computational sources for operation. Adapting them to particular downstream duties turns into significantly difficult on account of their huge scale and computational necessities, particularly on {hardware} platforms restricted by computational capabilities.
Earlier research have proposed that LLMs exhibit appreciable generalization talents, permitting them to use discovered information to new duties not encountered throughout coaching, a phenomenon often called zero-shot studying. Nevertheless, fine-tuning stays essential to optimize LLM efficiency on strong consumer datasets and duties. One broadly adopted fine-tuning technique entails adjusting a subset of LLM parameters whereas leaving the remaining unchanged, termed Parameter-Environment friendly Wonderful-Tuning (PEFT). This system selectively modifies a small fraction of parameters whereas retaining the bulk untouched. PEFT’s applicability extends past Pure Language Processing (NLP) to pc imaginative and prescient (CV), garnering curiosity in fine-tuning large-parameter imaginative and prescient fashions like Imaginative and prescient Transformers (ViT) and diffusion fashions, in addition to interdisciplinary vision-language fashions.
Researchers from Northeastern College, the College of California, Arizona State College, and New York College current this survey totally inspecting various PEFT algorithms and evaluating their efficiency and computational necessities. It additionally offers an summary of functions developed utilizing numerous PEFT strategies and discusses widespread methods employed to scale back computational bills related to PEFT. Past algorithmic issues, the survey delves into real-world system designs to discover the implementation prices of various PEFT algorithms. As a useful useful resource, this survey equips researchers with insights into PEFT algorithms and their system implementations, providing detailed analyses of latest progressions and sensible makes use of.
The researchers categorized PEFT algorithms into additive, selective, reparameterized, and hybrid fine-tuning primarily based on their operations. Main additive fine-tuning algorithms embody adapters, tender prompts, and others, which differ within the extra tunable modules or parameters they make the most of. Selective fine-tuning, in distinction, entails choosing a small subset of parameters from the spine mannequin, making solely these parameters tunable whereas leaving the bulk untouched throughout downstream job fine-tuning. Selective fine-tuning is categorized primarily based on the grouping of chosen parameters: Unstructural Masking and Structural Masking. Reparametrization entails remodeling mannequin parameters between two equal types, introducing extra low-rank trainable parameters throughout coaching, that are then built-in with the unique mannequin for inference. This strategy encompasses two primary methods: Low-rank Decomposition and LoRA Derivatives. Hybrid fine-tuning explores totally different PEFT strategies’ design areas and combines their benefits.
They established a sequence of parameters to look at computation prices and reminiscence overhead in LLMs as a basis for subsequent evaluation. In LLMs, tokens (phrases) are generated iteratively primarily based on the previous immediate (enter) and beforehand generated sequence. This course of continues till the mannequin outputs a termination token. A standard technique to expedite inference in LLMs entails storing earlier Keys and Values in a KeyValue cache (KV-cache), eliminating the necessity to recalculate them for every new token.
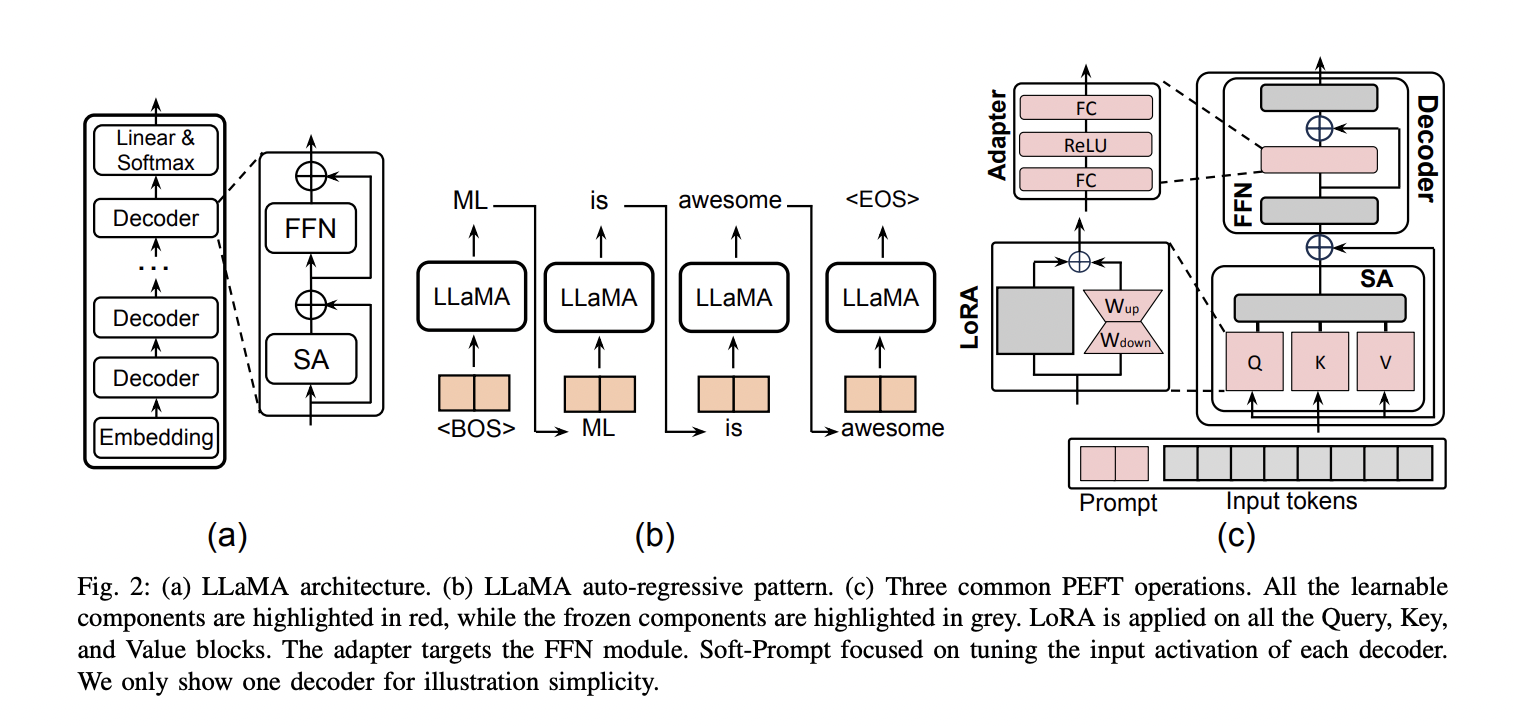
To conclude, this survey comprehensively explores various PEFT algorithms, offering insights into their efficiency, functions, and implementation prices. By categorizing PEFT strategies and inspecting computation and reminiscence issues, this examine presents invaluable steering for researchers traversing the complexities of fine-tuning giant fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 40k+ ML SubReddit
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


