
None of us can deny that giant language fashions (LLMs) have been pivotal within the latest developments of Synthetic Intelligence (AI). These fashions are instrumental in addressing a large spectrum of duties, from understanding pure language to fixing advanced mathematical issues and producing code. Their potential to motive—course of info logically to resolve issues, make choices, or derive insights—is paramount. Nevertheless, these fashions nonetheless endure when tackling varied difficult issues. These challenges are attributed however will not be restricted to some major causes, that are (1) the deficiency of high-quality alignment information and (2) the underutilization of choice studying methods to boost the sophisticated reasoning skills of fashions.
Current work consists of specialised fashions akin to MAmmoTH-7B-Mistral and WizardMath-7B-v1.1, targeted on mathematical reasoning, and Magicoder-S-DS-6.7B and OpenCodeInterpreter (OpenCI-DS-6.7B/CL-70B) for coding proficiency. Choice studying has additionally seen improvements with DPO and KTO strategies to boost mannequin alignment with human preferences. Nevertheless, these vital contributions usually have to be revised in making use of a unified reasoning functionality throughout numerous domains, a proficiency that proprietary fashions like GPT-3.5 Turbo and GPT-4 reveal extra successfully. This highlights a spot in attaining broad-based reasoning skills inside the open-source LLM panorama.
EURUS is the results of a collaborative effort by researchers from Tsinghua College, the College of Illinois Urbana-Champaign, Northeastern College, Renmin College of China, and ModelBest.Inc, BUPT, and Tencent. This collective experience has created a group of LLMs optimized for reasoning. EURUS’s distinctive method is underscored by its use of ULTRA INTERACT, a specifically designed dataset that enhances reasoning via choice studying and complicated interplay fashions. This technique has enabled EURUS to outperform current fashions in reasoning duties, showcasing its distinctive method to tackling advanced challenges.
EURUS methodology employs supervised fine-tuning and choice studying, using the ULTRA INTERACT dataset. This dataset integrates choice bushes with reasoning chains, multi-turn interplay trajectories, and paired actions to foster advanced reasoning coaching. The fine-tuning course of leverages foundational fashions Mistral-7B and CodeLlama-70B, with a efficiency analysis on benchmarks like LeetCode and TheoremQA to evaluate reasoning throughout mathematical and code technology duties. A brand new reward modeling goal, derived from insights gained via choice studying, enhances EURUS’s decision-making accuracy, positioning it to surpass current fashions in reasoning duties.
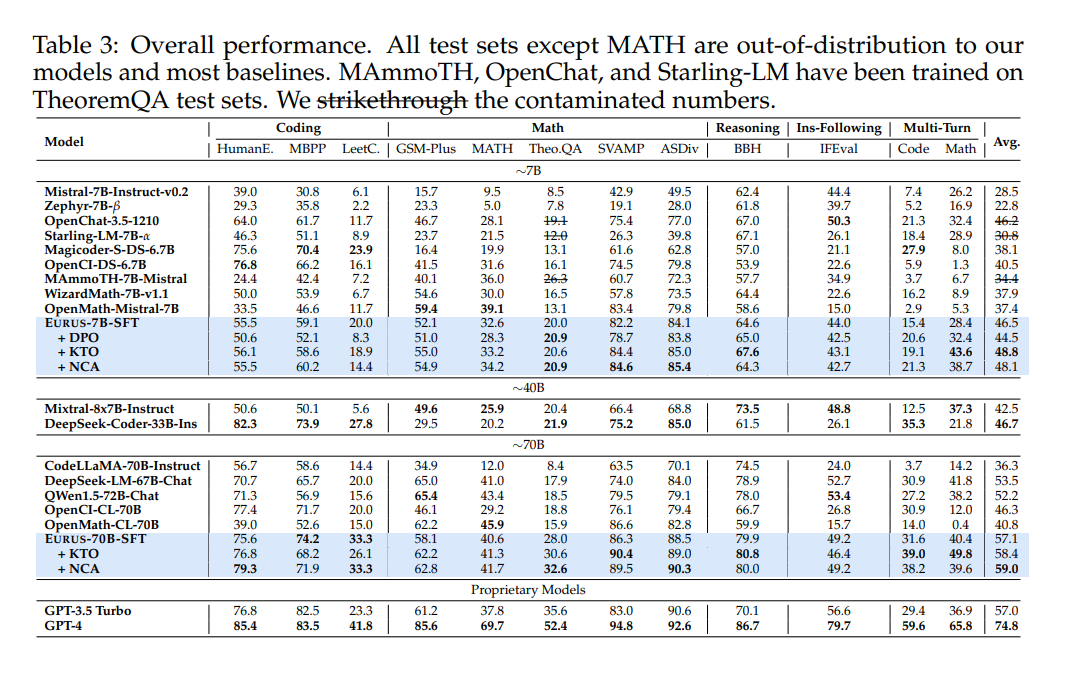
EURUS-70B has demonstrated superior reasoning capabilities by attaining a 33.3% go@1 accuracy on LeetCode and 32.6% on TheoremQA. These outcomes are considerably larger than these of current open-source fashions, surpassing them by margins exceeding 13.3%. This efficiency throughout numerous benchmarks, together with arithmetic and code technology duties, confirms EURUS’s potential to deal with advanced reasoning challenges successfully. It units a brand new benchmark within the efficiency of LLMs for each mathematical and coding problem-solving duties.
To conclude, the analysis launched EURUS, a group of LLMs fine-tuned for superior reasoning duties, using the ULTRA INTERACT dataset for enhanced coaching. By considerably enhancing go@1 accuracy on benchmarks akin to LeetCode and TheoremQA, EURUS demonstrates the potential of specialised datasets and revolutionary coaching methodologies in advancing LLMs’ reasoning capabilities. This work contributes to narrowing the hole between open-source fashions and proprietary counterparts, providing precious insights for future AI reasoning and problem-solving developments.
Take a look at the Paper, HF Web page, and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 39k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


