Retrieval-Augmented Technology (RAG) strategies face vital challenges in integrating up-to-date data, decreasing hallucinations, and enhancing response high quality in giant language fashions (LLMs). Regardless of their effectiveness, RAG approaches are hindered by advanced implementations and extended response occasions. Optimizing RAG is essential for enhancing LLM efficiency, enabling real-time purposes in specialised domains reminiscent of medical prognosis, the place accuracy and timeliness are important.
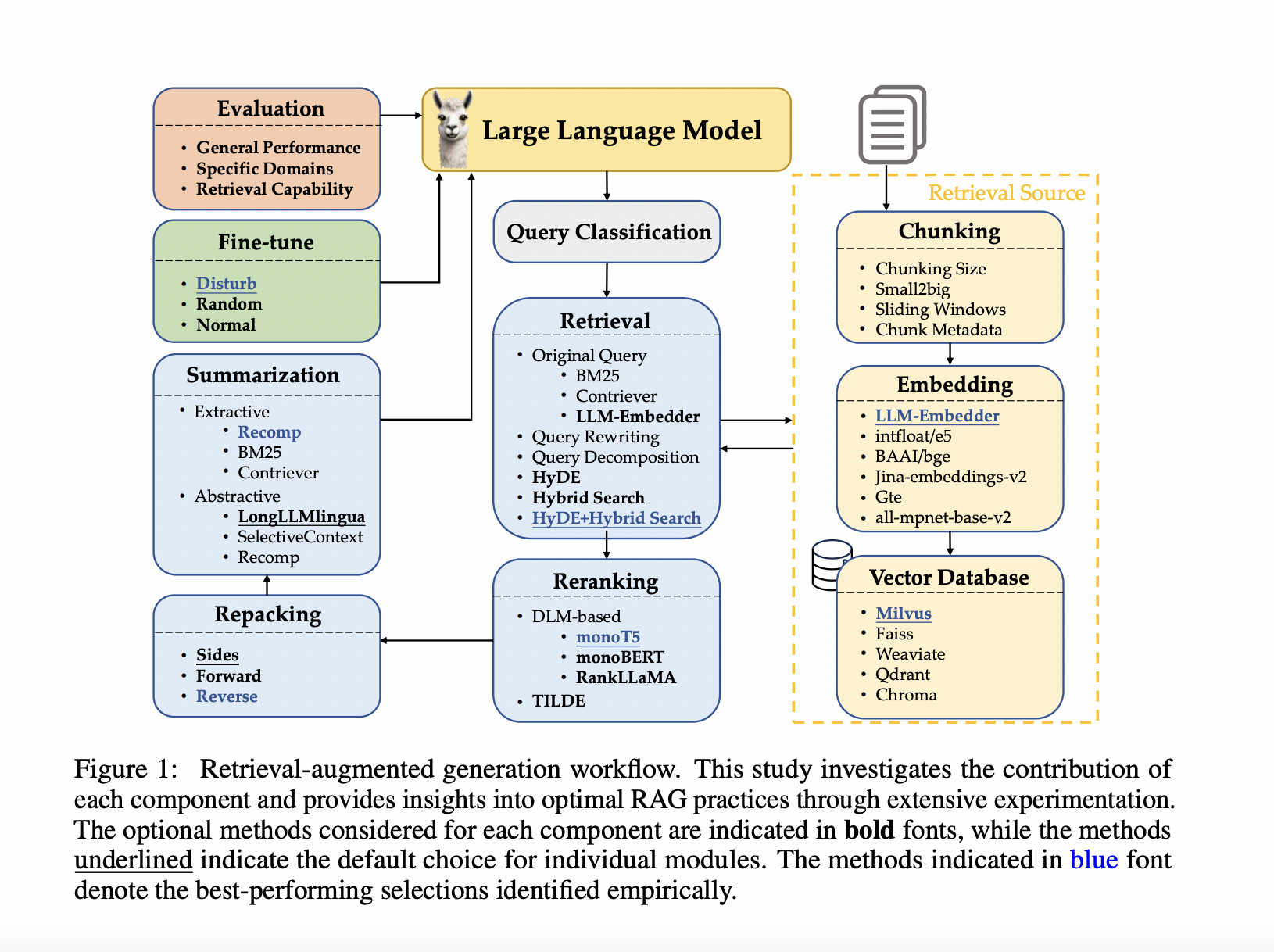
Present strategies addressing these challenges embrace workflows involving question classification, retrieval, reranking, repacking, and summarization. Question classification determines the need of retrieval, whereas retrieval strategies like BM25, Contriever, and LLM-Embedder get hold of related paperwork. Reranking refines the order of retrieved paperwork, and repacking organizes them for higher era. Summarization extracts key data for response era. Nevertheless, these strategies have particular limitations. As an illustration, question rewriting and decomposition can enhance retrieval however are computationally intensive. Reranking with deep language fashions enhances efficiency however is gradual. Current strategies additionally battle with effectively balancing efficiency and response time, making them unsuitable for real-time purposes.
The researchers from Fudan College performed a scientific investigation of present RAG approaches and their potential mixtures to determine optimum practices. A 3-step strategy was adopted: evaluating strategies for every RAG step, evaluating the affect of every technique on general RAG efficiency, and exploring promising mixtures for various situations. A number of methods to steadiness efficiency and effectivity are urged. A notable innovation is the mixing of multimodal retrieval strategies, which considerably improve question-answering capabilities about visible inputs and speed up multimodal content material era utilizing a “retrieval as era” technique. This strategy represents a big contribution to the sphere by providing extra environment friendly and correct options in comparison with present strategies.
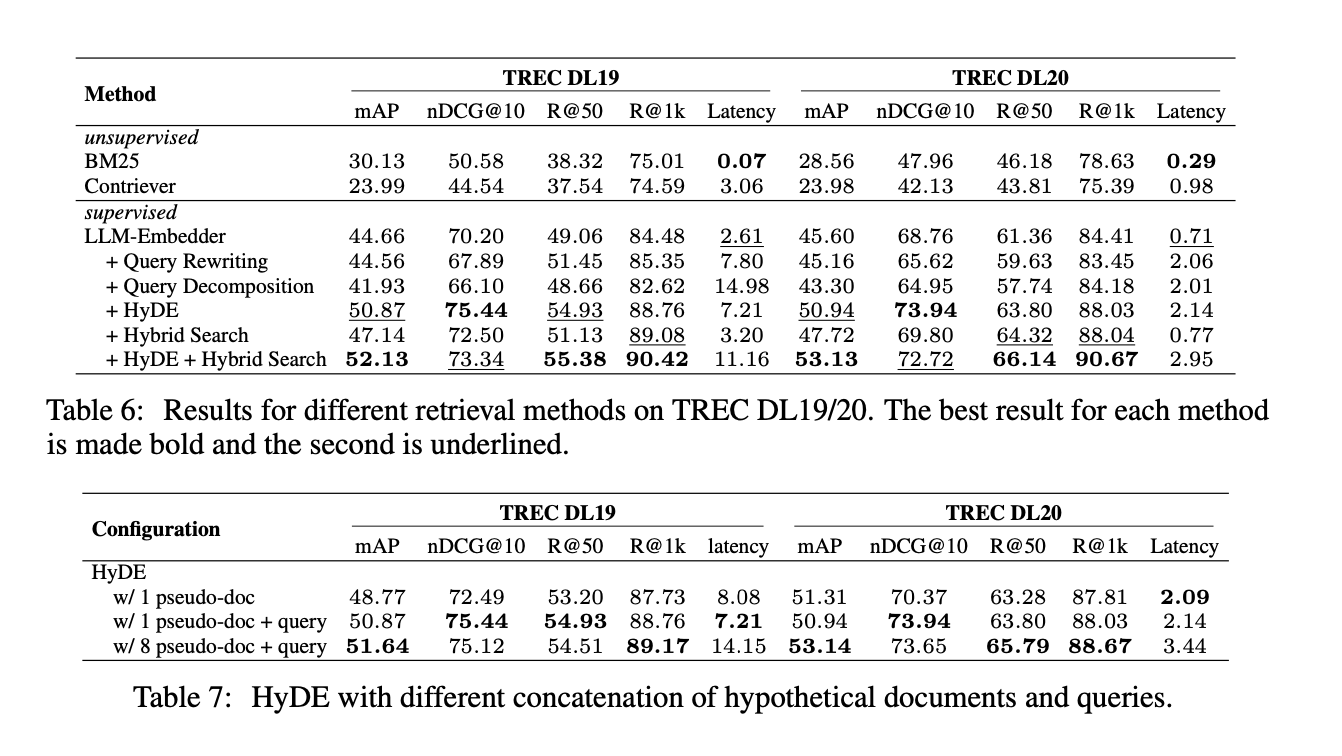
The analysis concerned detailed experimental setups to determine greatest practices for every RAG module. Datasets reminiscent of TREC DL 2019 and 2020 have been used for analysis, with numerous retrieval strategies together with BM25 for sparse retrieval and Contriever for dense retrieval. The experiments examined totally different chunking sizes and strategies like small-to-big and sliding home windows to enhance retrieval high quality. Analysis metrics included imply common precision (mAP), normalized discounted cumulative achieve (nDCG@10), and recall (R@50 and R@1k). Moreover, the affect of fine-tuning the generator with related and irrelevant contexts to boost efficiency was explored.
The examine achieves vital enhancements throughout numerous key efficiency metrics. Notably, the Hybrid with HyDE technique attained the very best scores within the TREC DL 2019 and 2020 datasets, with imply common precision (mAP) values of 52.13 and 53.13, respectively, considerably outperforming baseline strategies. The retrieval efficiency, measured by recall@50, confirmed notable enhancements, reaching values of 55.38 and 66.14. These outcomes underscore the efficacy of the beneficial methods, demonstrating substantial enhancements in retrieval effectiveness and effectivity.

In conclusion, this analysis addresses the problem of optimizing RAG strategies to boost LLM efficiency. It systematically evaluates present strategies, proposes revolutionary mixtures, and demonstrates vital enhancements in efficiency metrics. The combination of multimodal retrieval strategies represents a big development within the area of AI analysis. This examine not solely gives a sturdy framework for deploying RAG methods but in addition units a basis for future analysis to discover additional optimizations and purposes in numerous domains.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.


