
Regardless of their increasing capabilities, giant language fashions (LLMs) need assistance with processing in depth contexts. These limitations stem from Transformer-based architectures struggling to extrapolate past their coaching window measurement. Processing lengthy token sequences requires substantial computational sources and dangers producing noisy consideration embeddings. These constraints hinder LLMs’ means to include domain-specific, personal, or up-to-date info successfully. Researchers have tried varied approaches, together with retrieval-based strategies, however a big efficiency hole stays between short- and long-context duties, even when using current long-context architectures.
Researchers have explored varied approaches to increase LLMs’ context home windows, specializing in enhancing softmax consideration, decreasing computational prices, and enhancing positional encodings. Retrieval-based strategies, significantly group-based k-NN retrieval, have proven promise by retrieving giant token teams and functioning as hierarchical consideration.
Concurrently, analysis in neural fashions of episodic reminiscence has supplied insights into mind processes for storing experiences. These fashions spotlight the significance of surprise-based occasion segmentation and temporal dynamics in reminiscence formation and retrieval. Research reveal that transformer-based LLMs exhibit temporal contiguity and asymmetry results much like human reminiscence retrieval, suggesting potential for functioning as episodic reminiscence retrieval fashions with applicable context info.
Researchers from Huawei Noah’s Ark Lab and College Faculty London suggest a EM-LLM, a novel structure integrating episodic reminiscence into Transformer-based LLMs, enabling them to deal with considerably longer contexts. It divides the context into preliminary tokens, evicted tokens (managed by an episodic reminiscence mannequin), and native context. The structure varieties recollections by segmenting token sequences into occasions based mostly on shock ranges throughout inference, refining boundaries utilizing graph-theoretic metrics to optimize cohesion and separation. Reminiscence retrieval employs a two-stage mechanism: k-NN search retrieves related occasions, whereas a contiguity buffer maintains temporal context. This method mimics human episodic reminiscence, enhancing the mannequin’s means to course of prolonged contexts and carry out advanced temporal reasoning duties effectively.
EM-LLM extends pre-trained LLMs to deal with bigger context lengths. It divides the context into preliminary tokens, evicted tokens, and native context. The native context makes use of full softmax consideration, representing the latest and related info. Evicted tokens, managed by a reminiscence mannequin much like short-term episodic reminiscence, comprise nearly all of previous tokens. Preliminary tokens act as consideration sinks. For retrieved tokens outdoors the native context, EM-LLM assigns mounted place embeddings. This structure permits EM-LLM to course of info past its pre-trained context window whereas sustaining efficiency traits.
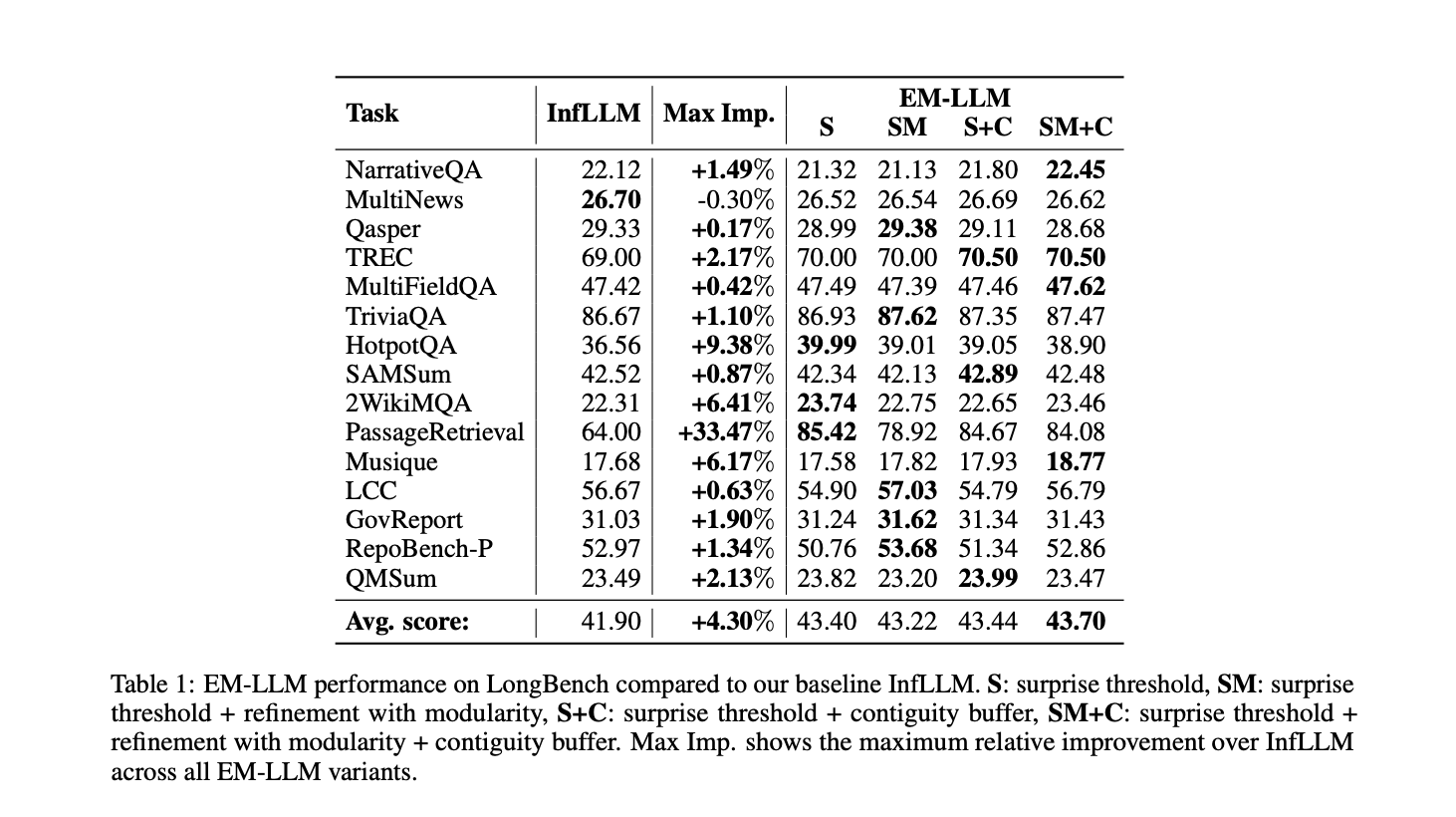
EM-LLM demonstrated improved efficiency on long-context duties in comparison with the baseline InfLLM mannequin. On the LongBench dataset, EM-LLM surpassed InfLLM in all however one job, reaching an total improve of 1.8 share factors (4.3% relative enchancment). Additionally, EM-LLM confirmed important positive aspects on the PassageRetrieval job, with as much as a 33% enchancment, and a 9.38% enchancment on the HotpotQA job. These outcomes spotlight EM-LLM’s enhanced means to recall detailed info from giant contexts and carry out advanced reasoning over a number of supporting paperwork. The research additionally discovered that surprise-based segmentation strategies carefully aligned with human occasion notion, outperforming mounted or random occasion segmentation approaches.
EM-LLM represents a big development in language fashions with prolonged context-processing capabilities. By integrating human episodic reminiscence and occasion cognition into transformer-based LLMs, it successfully processes info from vastly prolonged contexts with out pre-training. The mix of surprise-based occasion segmentation, graph-theoretic boundary refinement, and two-stage reminiscence retrieval permits superior efficiency on long-context duties. EM-LLM provides a path in the direction of just about infinite context home windows, probably revolutionizing LLM interactions with steady, customized exchanges. This versatile framework serves as an alternative choice to conventional RAG strategies and supplies a scalable computational mannequin for testing human reminiscence hypotheses. By bridging cognitive science and machine studying, EM-LLM not solely enhances LLM efficiency but in addition evokes additional analysis on the intersection of LLMs and human reminiscence mechanisms.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 46k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


