
Mannequin merging, notably throughout the realm of enormous language fashions (LLMs), presents an intriguing problem that addresses the rising demand for versatile AI techniques. These fashions typically possess specialised capabilities resembling multilingual proficiency or domain-specific experience, making their integration essential for creating extra strong, multi-functional techniques. Nevertheless, merging LLMs successfully shouldn’t be trivial; it typically requires deep experience and vital computational sources to stability totally different coaching strategies and fine-tuning processes with out deteriorating general efficiency. To simplify this course of and cut back the complexity related to present mannequin merging strategies, researchers are striving to develop extra adaptive, much less resource-intensive merging strategies.
Researchers from Arcee AI and Liquid AI suggest a novel merging method known as Differentiable Adaptive Merging (DAM). DAM goals to sort out the complexities of merging language fashions by providing an environment friendly, adaptive methodology that reduces the computational overhead sometimes related to present mannequin merging practices. Particularly, DAM offers a substitute for compute-heavy approaches like evolutionary merging by optimizing mannequin integration by way of scaling coefficients, enabling easier but efficient merging of a number of LLMs. The researchers additionally performed a comparative evaluation of DAM towards different merging approaches, resembling DARE-TIES, TIES-Merging, and easier strategies like Mannequin Soups, to focus on its strengths and limitations.
The core of DAM is its skill to merge a number of LLMs utilizing a data-informed strategy, which entails studying optimum scaling coefficients for every mannequin’s weight matrix. The tactic is relevant to varied elements of the fashions, together with linear layers, embedding layers, and layer normalization layers. DAM works by scaling every column of the burden matrices to stability the enter options from every mannequin, thus guaranteeing that the merged mannequin retains the strengths of every contributing mannequin. The target operate of DAM combines a number of elements: minimizing Kullback-Leibler (KL) divergence between the merged mannequin and the person fashions, cosine similarity loss to encourage variety in scaling coefficients, and L1 and L2 regularization to make sure sparsity and stability throughout coaching. These components work in tandem to create a strong and well-integrated merged mannequin able to dealing with numerous duties successfully.
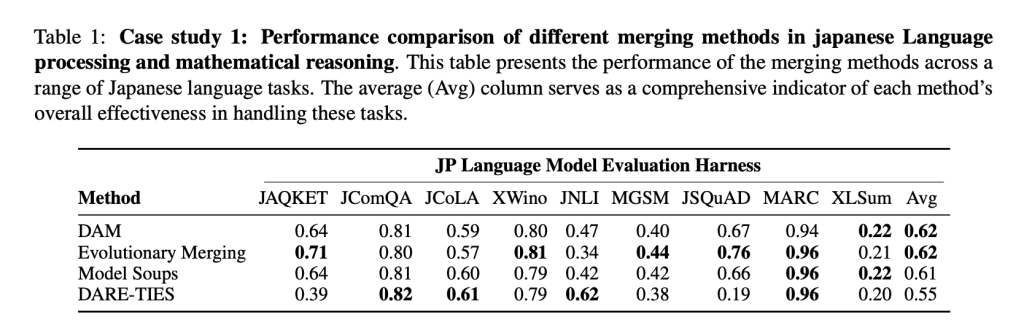
The researchers carried out intensive experiments to match DAM with different mannequin merging strategies. The analysis was performed throughout totally different mannequin households, resembling Mistral and Llama 3, and concerned merging fashions with numerous capabilities, together with multilingual processing, coding proficiency, and mathematical reasoning. The outcomes confirmed that DAM not solely matches however, in some circumstances, outperforms extra computationally demanding strategies like Evolutionary Merging. For instance, in a case research specializing in Japanese language processing and mathematical reasoning, DAM demonstrated superior adaptability, successfully balancing the specialised capabilities of various fashions with out the intensive computational necessities of different strategies. Efficiency was measured utilizing a number of metrics, with DAM typically scoring greater or on par with options throughout duties involving language comprehension, mathematical reasoning, and structured question processing.
The analysis concludes that DAM is a sensible resolution for merging LLMs with decreased computational price and handbook intervention. This research additionally emphasizes that extra advanced merging strategies, whereas highly effective, don’t at all times outperform easier options like linear averaging when fashions share comparable traits. DAM proves that specializing in effectivity and scalability with out sacrificing efficiency can present a big benefit in AI growth. Transferring ahead, researchers intend to discover DAM’s scalability throughout totally different domains and languages, probably increasing its influence on the broader AI panorama.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Nice-Tuned Fashions: Predibase Inference Engine (Promoted)
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of know-how and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.



