
The surge in deploying Massive Language Fashions (LLMs) akin to GPT-3, OPT, and BLOOM throughout numerous digital interfaces, together with chatbots and textual content summarization instruments, has introduced the crucial want for optimizing their serving infrastructure to the forefront. LLMs are infamous for his or her large sizes and the substantial computational assets they necessitate, presenting a trio of formidable challenges of their serving: effectively using {hardware} accelerators, managing the reminiscence footprint, and making certain minimal downtime throughout failures.
Researchers from MSR Undertaking Fiddle Intern, ETH Zurich, Carnegie Mellon College, and Microsoft Analysis have meticulously developed a novel DéjàVu system to navigate these obstacles elegantly. On the coronary heart of DéjàVu lies a flexible Key-Worth (KV) cache streaming library, dubbed DéjàVuLib, which is ingeniously designed to streamline the serving means of LLMs. This technique is groundbreaking for its method to dealing with the bimodal latency inherent in immediate processing and token era, a disparity that beforehand led to important GPU underutilization.
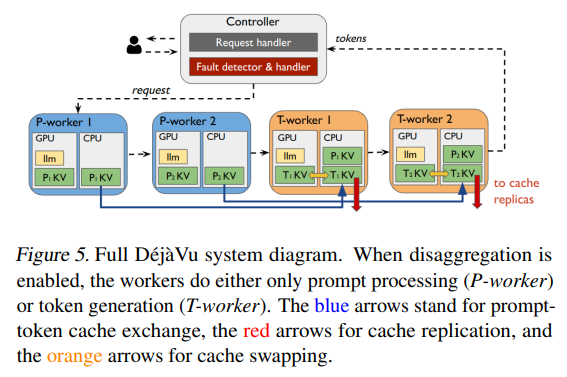
DéjàVu introduces a paradigm shift by prompt-token disaggregation, allocating distinct computational assets for every section. This separation is tactically applied to match the disparate reminiscence and compute necessities of immediate processing and token era. By aligning computational duties with essentially the most appropriate {hardware}, DéjàVu ensures that GPUs are saved energetic, effectively bridging the hole between the computationally intense immediate processing and the comparatively uniform token era section.
A pivotal part of DéjàVu’s technique is micro-batch swapping, an modern approach designed to maximise GPU reminiscence effectivity. This course of entails dynamically swapping microbatches between GPU and CPU reminiscence, thus permitting for bigger batch sizes with out the necessity for proportional will increase in GPU reminiscence. This not solely enhances throughput but in addition permits for the serving of bigger fashions underneath mounted {hardware} constraints, a major leap ahead in LLM serving expertise.
DéjàVu units a brand new normal in system resilience by its state replication characteristic, which is designed to fortify the serving course of towards interruptions. By replicating the KV cache state throughout completely different reminiscence shops, DéjàVu ensures that within the occasion of a failure, the system can rapidly resume operations from the final identified good state, minimizing the impression on general serving efficiency. This method dramatically reduces the redundancy and latency usually related to restoration processes in conventional LLM serving techniques.
The efficacy of DéjàVu demonstrated a capability to enhance throughput by as much as twice that of present techniques, a testomony to its modern methodologies. Such enhancements aren’t simply numerical triumphs however signify tangible enhancements within the person expertise by lowering wait instances and enhancing the belief in providers powered by LLMs.
In crafting DéjàVu, researchers have addressed the present inefficiencies in LLM serving and laid a blueprint for future improvements on this house. The system’s modular structure, embodied by DéjàVuLib, ensures that it may be tailored and prolonged to fulfill the evolving calls for of LLM purposes. This adaptability, mixed with the tangible enhancements in effectivity and reliability, marks a major milestone in realizing the potential of LLMs in on a regular basis purposes.
In conclusion, the analysis may be summarized within the following factors:
- DéjàVu revolutionizes LLM serving with a give attention to effectivity and fault tolerance, considerably outperforming present techniques.
- The separation of immediate processing and token era, coupled with micro-batch swapping, optimizes GPU utilization and reminiscence administration.
- State replication ensures robustness towards failures, permitting for fast restoration and minimal service interruption.
- Demonstrated throughput enhancements of as much as 2x spotlight DéjàVu’s potential to reinforce person experiences throughout LLM-powered providers.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and Google Information. Be part of our 38k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our Telegram Channel
You may additionally like our FREE AI Programs….
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Know-how, Kharagpur. I’m captivated with expertise and need to create new merchandise that make a distinction.


