
For too lengthy, the world of pure language processing has been dominated by fashions that primarily cater to the English language. This inherent bias has left a good portion of the worldwide inhabitants feeling underrepresented and ignored. Nonetheless, a groundbreaking new improvement is ready to problem this establishment and usher in a extra inclusive period of language fashions – the Chinese language Tiny LLM (CT-LLM).
Think about a world the place language boundaries are not an impediment to accessing cutting-edge AI applied sciences. That’s exactly what the researchers behind CT-LLM have got down to obtain by prioritizing the Chinese language language, one of the extensively spoken on the planet. This 2 billion parameter mannequin departs from the traditional method of coaching language fashions totally on English datasets after which adapting them to different languages.
As an alternative, CT-LLM has been meticulously pre-trained on a staggering 1,200 billion tokens, with a strategic emphasis on Chinese language knowledge. The pretraining corpus includes a powerful 840.48 billion Chinese language tokens, complemented by 314.88 billion English tokens and 99.3 billion code tokens. This strategic composition not solely equips the mannequin with distinctive proficiency in understanding and processing Chinese language but additionally enhances its multilingual adaptability, making certain that it will possibly navigate the linguistic landscapes of numerous cultures with ease.
However that’s not all – CT-LLM incorporates cutting-edge strategies contributing to its distinctive efficiency. One such innovation is supervised fine-tuning (SFT), which bolsters the mannequin’s adeptness in Chinese language language duties whereas concurrently enhancing its versatility in comprehending and producing English textual content. Furthermore, the researchers have employed desire optimization strategies, resembling DPO (Direct Desire Optimization), to align CT-LLM with human preferences, making certain that its outputs usually are not solely correct but additionally innocent and useful.
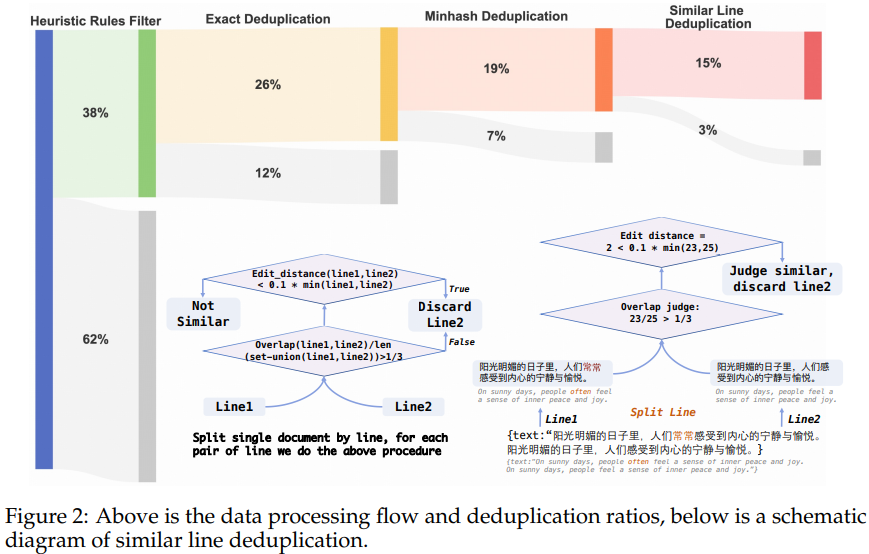
To place CT-LLM’s capabilities to the take a look at, the researchers developed the Chinese language Exhausting Case Benchmark (CHC-Bench), a multidisciplinary suite of difficult issues designed to evaluate the mannequin’s instruction understanding and following skills within the Chinese language language. Remarkably, CT-LLM demonstrated excellent efficiency on this benchmark, excelling in duties associated to social understanding and writing, showcasing its robust grasp of Chinese language cultural contexts.
The event of CT-LLM represents a major stride in direction of creating inclusive language fashions that mirror the linguistic range of our world society. By prioritizing the Chinese language language from the outset, this groundbreaking mannequin challenges the prevailing English-centric paradigm and paves the best way for future improvements in NLP that cater to a broader vary of languages and cultures. With its distinctive efficiency, progressive strategies, and open-sourced coaching course of, CT-LLM stands as a beacon of hope for a extra equitable and consultant future within the subject of pure language processing. Sooner or later, language boundaries are not an obstacle to accessing cutting-edge AI applied sciences.
Try the Paper and HF Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 40k+ ML SubReddit
Vibhanshu Patidar is a consulting intern at MarktechPost. At present pursuing B.S. at Indian Institute of Expertise (IIT) Kanpur. He’s a Robotics and Machine Studying fanatic with a knack for unraveling the complexities of algorithms that bridge idea and sensible purposes.


