
Giant language fashions (LLMs) have made vital success in varied language duties, however steering their outputs to satisfy particular properties stays a problem. Researchers try to unravel the issue of controlling LLM generations to fulfill desired traits throughout a variety of purposes. This contains reinforcement studying from human suggestions (RLHF), red-teaming methods, reasoning duties, and implementing particular response properties. Present methodologies face challenges in successfully guiding mannequin outputs whereas sustaining coherence and high quality. The complexity lies in balancing the mannequin’s realized information with the necessity to generate responses that align with focused attributes or constraints, necessitating modern approaches to language mannequin steering.
Prior makes an attempt to unravel language mannequin steering challenges embrace numerous decoding strategies, managed era methods, and reinforcement learning-based approaches. Various decoding strategies like best-of-Ok sampling purpose to generate assorted outputs, whereas managed era methods comparable to PPLM and GeDi give attention to guiding the mannequin’s output in direction of particular attributes. Reinforcement studying strategies, significantly these utilizing Proximal Coverage Optimization (PPO), have been employed to coach fashions that steadiness between coverage and worth networks. Some researchers have explored Monte Carlo Tree Search (MCTS) methods, both primarily based on PPO worth estimates or pushed by discriminators, to enhance decoding processes. Nonetheless, these strategies typically lack a unified probabilistic framework and will not align completely with the specified goal distribution, leaving room for extra principled approaches to language mannequin steering.
Researchers from the College of Toronto and Vector Institute make the most of Twisted Sequential Monte Carlo (SMC), a strong framework for probabilistic inference in language fashions. This method addresses the problem of sampling from non-causal goal distributions by studying twist capabilities that modulate the bottom mannequin to match goal marginals. The tactic focuses language mannequin era on promising partial sequences, enhancing the standard and relevance of outputs. Twisted SMC not solely allows efficient sampling but in addition supplies instruments for evaluating inference methods via log partition perform estimates. This probabilistic perspective provides a unified method to language mannequin steering, bridging the hole between sampling, analysis, and fine-tuning strategies. By using ideas from energy-based modeling and density ratio estimation, the framework introduces distinctive methods like contrastive twist studying (CTL) and adapts current twisted SMC strategies to the language modeling context.
Twisted SMC in language fashions focuses on defining intermediate targets that align with the true marginals of the goal distribution. In contrast to conventional SMC strategies that depend on per-token or few-step-ahead statistics, twisted SMC considers the complete goal data as much as the terminal time T. This method is especially helpful for goal distributions decided by a terminal potential solely. The important thing innovation lies within the introduction of twist capabilities ψt that modulate the bottom language mannequin to approximate the goal marginals at every intermediate step. These twist capabilities successfully summarize future data related to sampling at time t, enabling the strategy to generate partial sequences which can be distributed based on the specified intermediate marginals. This method permits for extra correct and environment friendly sampling from complicated goal distributions, enhancing the general high quality of language mannequin outputs in duties requiring particular terminal traits.
Twisted SMC introduces the idea of twist capabilities to characterize intermediate goal distributions in language mannequin sampling. These twist capabilities ψt modulate the bottom mannequin p0 to approximate the goal marginals σ(s1:t) at every step. The tactic permits for flexibility in selecting proposal distributions, with choices together with the bottom mannequin, a twist-induced proposal, or variational proposals.
A key innovation is the twist-induced proposal, which minimizes the variance of significance weights. This proposal is tractable to pattern in transformer architectures for all however the remaining timestep, the place an approximation is used. The ensuing incremental weights are unbiased of the sampled token for all however the remaining step, enhancing effectivity.
The framework extends to conditional goal distributions, accommodating eventualities the place the era is conditioned on an remark. This generalization permits for actual goal sampling on simulated knowledge utilizing a way referred to as the Bidirectional Monte Carlo trick.
Twisted SMC shares connections with reinforcement studying, significantly delicate RL with KL regularization. On this context, twist capabilities correspond to state-action Q-values, and the proposal performs a task analogous to an actor in actor-critic strategies. This probabilistic perspective provides benefits over conventional RL approaches, together with extra principled resampling and distinctive analysis methods for language fashions.
The examine evaluated the effectiveness of Twisted SMC and varied inference strategies throughout totally different language modelling duties, together with poisonous story era, sentiment-controlled evaluation era, and textual content infilling. Key findings embrace:
1. Log partition perform estimation: Twisted SMC considerably improved sampling effectivity in comparison with easy significance sampling, particularly when utilizing the twist-induced proposal distribution.
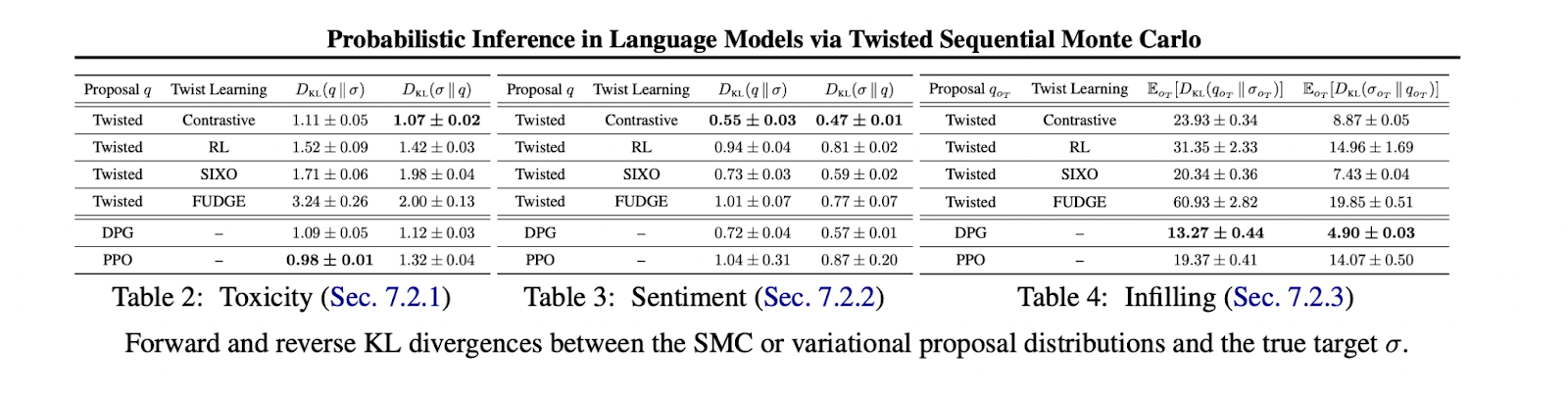
2. Toxicity job: CTL carried out greatest in minimizing the reverse KL divergence, whereas PPO excelled in minimizing the ahead KL divergence.
3. Sentiment management: CTL achieved the bottom KL divergences in each instructions, outperforming different strategies in producing opinions with assorted sentiments.
4. Infilling job: Distributional Coverage Gradient (DPG) confirmed the very best efficiency, probably attributable to its potential to make the most of actual optimistic samples. CTL and SIXO carried out comparably, whereas PPO lagged.
5. Total, the outcomes demonstrated that the selection of inference technique will depend on the precise job and obtainable sampling methods. CTL proved efficient with approximate optimistic sampling, whereas DPG excelled when actual goal samples had been obtainable.
These findings spotlight the flexibility of the Twisted SMC framework in each enhancing sampling effectivity and evaluating varied inference strategies throughout totally different language modelling duties.
This examine introduces Twisted Sequential Monte Carlo, a strong probabilistic inference framework for language fashions, addressing varied functionality and security duties. This method introduces strong design selections and a contrastive technique for twist studying, enhancing sampling effectivity and accuracy. The proposed bidirectional SMC bounds provide a sturdy analysis software for language mannequin inference strategies. Experimental outcomes throughout numerous settings reveal the effectiveness of Twisted SMC in each sampling and analysis duties. This framework represents a big development in probabilistic inference for language fashions, providing improved efficiency and flexibility in dealing with complicated language duties.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.


