
Massive language fashions (LLMs), together with GPT-4, LLaMA, and PaLM are pushing the boundaries of synthetic intelligence. The inference latency of LLMs performs an vital function due to LLMs integration in numerous functions, guaranteeing a optimistic person expertise and excessive service high quality. Nonetheless, the LLM service operates inside an AR paradigm, producing one token at a time as a result of the eye mechanism depends on earlier token states to generate the following token. To supply an extended response, a ahead cross is executed utilizing LLMs equal to the variety of tokens generated, resulting in excessive latency.
The environment friendly LLM Inference methodology is split into two streams, a way that wants extra coaching and one other that doesn’t want it. Researchers explored this methodology as a result of excessive AR inference price for LLMs, principally targeted on growing the AR decoding course of. One other present methodology is LLM Distillation, the place the Information distillation (KD) method is used to create small fashions and change the performance of bigger ones. Nonetheless, conventional KD strategies usually are not efficient for LLMs. So, KD is used for autoregressive LLMs to attenuate the reverse KL divergence between scholar and instructor fashions by way of student-driven decoding.
Researchers from Shanghai Jiao College and the College of California proposed Consistency Massive Language Fashions (CLLMs), a brand new household of LLMs specialised for the Jacobi decoding methodology for latency discount. CLLM was in contrast with conventional strategies reminiscent of speculative decoding and Medusa for adjusting auxiliary mannequin parts and didn’t use further reminiscence for this process, not like others. When CLLMs are educated on ∼ 1M tokens for LLaMA-7B, it turns into 3.4 occasions quicker on the Spider dataset exhibiting that the price of fine-tuning is average for this methodology. Two essential elements for this speed-up are quick forwarding and stationary tokens.
In quick forwarding, right predictions are accomplished in a single ahead cross for a number of consecutive tokens whereas, stationary tokens present right prediction with no change by way of subsequent iterations regardless of being preceded by inaccurate tokens. In goal LLMs and CLLMs, when fast-forwarded and stationary counts are in contrast throughout all 4 datasets (in Desk 3), there’s an enchancment of two.0x to six.8x in each token counts. Additionally, for each the token counts, such enchancment in domain-specific datasets is best than in open-domain datasets profiled on MT-bench. This helps distinctive collocations and simple syntactical constructions like clean house, newline tokens, and repetitive particular characters in specialised domains like coding.
Researchers carried out experiments to judge the efficiency and inference speedup of CLLMs throughout a number of duties reminiscent of evaluating the stat-of-the-art (SOTA) baselines on the three domain-specific duties and the open-domain profiled on MT-bench. CLLMs present excellent efficiency on numerous benchmarks, e.g. they’ll obtain 2.4× to three.4× speedup utilizing Jacobi decoding with practically no loss in accuracy on domain-specific benchmarks like GSM8K, CodeSearchNet Python, and Spider. CLLMs can obtain 2.4× speedup on ShareGPT with SOTA efficiency, with a 6.4 rating on the open-domain benchmark MT-bench.
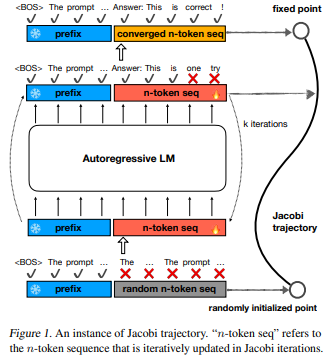
In conclusion, researchers launched CLLMs, a brand new household of LLMs that excel in environment friendly parallel decoding and are designed in a method that they’ll enhance the effectivity of Jacobi decoding. Further structure designs or managing two totally different fashions in a single system are complicated and complexity is diminished with the assistance of CLLMs as a result of this methodology is straight tailored from a goal pre-trained LLM. Moreover, fast-forwarded and stationary token counts are in contrast throughout 4 datasets, exhibiting an enhancement of two.0x to six.8x In goal LLMs and CLLMs.
Take a look at the Paper and Mission. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 42k+ ML SubReddit

Sajjad Ansari is a closing 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the impression of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


