
Reinforcement studying (RL) is a site inside synthetic intelligence that trains brokers to make sequential choices via trial and error in an surroundings. This strategy permits the agent to be taught by interacting with its environment, receiving rewards or penalties based mostly on its actions. Nonetheless, coaching brokers to carry out optimally in complicated duties requires entry to in depth, high-quality information, which can not all the time be possible. Restricted information typically hinders studying, resulting in poor generalization and sub-optimal decision-making. Due to this fact, discovering methods to enhance studying effectivity with small or low-quality datasets has grow to be an important space of analysis in RL.
One of many foremost challenges RL researchers face is growing strategies that may work successfully with restricted datasets. Typical RL approaches typically rely upon extremely various datasets collected via in depth exploration by brokers. This dependency on massive datasets makes conventional strategies unsuitable for real-world purposes, the place information assortment is time-consuming, costly, and probably harmful. Consequently, most RL algorithms carry out poorly when skilled on small or homogeneous datasets, as they endure from overestimating the values of out-of-distribution (OOD) state-action pairs, resulting in ineffective coverage technology.
Present zero-shot RL strategies intention to coach brokers to carry out a number of duties with out direct publicity to the features throughout coaching. These strategies leverage ideas like successor measures, and successor options to generalize throughout duties. Nonetheless, current zero-shot RL strategies are restricted by their reliance on massive, heterogeneous datasets for pre-training. This reliance poses vital challenges when utilized to real-world eventualities the place solely small or homogeneous datasets can be found. The degradation in efficiency when utilizing smaller datasets is primarily because of the strategies’ inherent tendency to overestimate OOD state-action values, a well-observed phenomenon in single-task offline RL.
A analysis staff from the College of Cambridge and the College of Bristol has proposed a brand new conservative zero-shot RL framework. This strategy introduces modifications to current zero-shot RL strategies by incorporating rules from conservative RL, a method well-suited for offline RL settings. The researchers’ modifications embrace a simple regularizer for OOD state-action values, which might be built-in into any zero-shot RL algorithm. This new framework considerably mitigates the overestimation of OOD actions and improves efficiency when skilled on small or low-quality datasets.
The conservative zero-shot RL framework employs two main modifications: value-conservative forward-backward (VC-FB) representations and measure-conservative forward-backward (MC-FB) representations. The VC-FB methodology suppresses OOD motion values throughout all process vectors drawn from a specified distribution, making certain that the agent’s coverage stays inside the bounds of noticed actions. In distinction, the MC-FB methodology suppresses the anticipated visitation counts for all process vectors, decreasing the probability of the agent taking OOD actions throughout check eventualities. These modifications are straightforward to combine into the usual RL coaching course of, requiring solely a slight enhance in computational complexity.
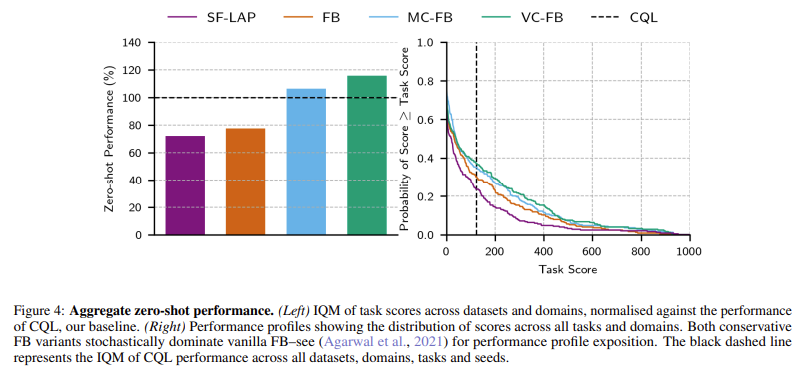
The efficiency of the conservative zero-shot RL algorithms was evaluated on three datasets: Random Community Distillation (RND), Variety is All You Want (DIAYN), and Random (RANDOM) insurance policies, every with various ranges of knowledge high quality and dimension. The conservative strategies confirmed as much as 1.5x in mixture efficiency enchancment in comparison with non-conservative baselines. For instance, VC-FB achieved an interquartile imply (IQM) rating of 148, whereas the non-conservative baseline scored solely 99 on the identical dataset. Additionally, the outcomes confirmed that the conservative approaches didn’t compromise efficiency when skilled on massive, various datasets, additional validating the robustness of the proposed framework.
Key Takeaways from the analysis:
- The proposed conservative zero-shot RL strategies enhance efficiency on low-quality datasets by as much as 1.5x in comparison with non-conservative strategies.
- Two main modifications have been launched: VC-FB and MC-FB, which give attention to worth and measure conservatism.
- The brand new strategies confirmed an interquartile imply (IQM) rating of 148, surpassing the baseline rating of 99.
- The conservative algorithms maintained excessive efficiency even on massive, various datasets, making certain adaptability and robustness.
- The framework considerably reduces the overestimation of OOD state-action values, addressing a significant problem in RL coaching with restricted information.

In conclusion, the conservative zero-shot RL framework presents a promising resolution to coaching RL brokers utilizing small or low-quality datasets. The proposed modifications supply a big efficiency enchancment, decreasing the influence of OOD worth overestimation and enhancing the robustness of brokers throughout diverse eventualities. This analysis is a step in direction of the sensible deployment of RL programs in real-world purposes, demonstrating that efficient RL coaching is achievable even with out massive, various datasets.
Try the Paper and Mission. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 50k+ ML SubReddit.
We’re inviting startups, corporations, and analysis establishments who’re engaged on small language fashions to take part on this upcoming ‘Small Language Fashions’ Journal/Report by Marketchpost.com. This Journal/Report might be launched in late October/early November 2024. Click on right here to arrange a name!
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is obsessed with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.


