
Giant Language Fashions (LLMs), initially restricted to text-based processing, confronted important challenges in comprehending visible knowledge. This limitation led to the event of Visible Language Fashions (VLMs), which combine visible understanding with language processing. Early fashions like VisualGLM, constructed on architectures similar to BLIP-2 and ChatGLM-6B, represented preliminary efforts in multi-modal integration. Nevertheless, these fashions typically relied on shallow alignment strategies, limiting the depth of visible and linguistic integration, thereby highlighting the necessity for extra superior approaches.
Subsequent developments in VLM structure, exemplified by fashions like CogVLM, centered on attaining a deeper fusion of imaginative and prescient and language options, thereby enhancing pure language efficiency. The event of specialised datasets, such because the Artificial OCR Dataset, performed an important function in bettering fashions’ OCR capabilities, enabling broader purposes in doc evaluation, GUI comprehension, and video understanding. These improvements have considerably expanded the potential of LLMs, driving the evolution of visible language fashions.
This analysis paper from Zhipu AI and Tsinghua College introduces the CogVLM2 household, a brand new era of visible language fashions designed for enhanced picture and video understanding, together with fashions similar to CogVLM2, CogVLM2-Video, and GLM-4V. Developments embrace a higher-resolution structure for fine-grained picture recognition, exploration of broader modalities like visible grounding and GUI brokers, and modern strategies like post-downsample for environment friendly picture processing. The paper additionally emphasizes the dedication to open-sourcing these fashions, offering worthwhile assets for additional analysis and growth in visible language fashions.
The CogVLM2 household integrates architectural improvements, together with the Visible Knowledgeable and high-resolution cross-modules, to reinforce the fusion of visible and linguistic options. The coaching course of for CogVLM2-Video includes two levels: Instruction Tuning, utilizing detailed caption knowledge and question-answering datasets with a studying fee of 4e-6, and Temporal Grounding Tuning on the TQA Dataset with a studying fee of 1e-6. Video enter processing employs 24 sequential frames, with a convolution layer added to the Imaginative and prescient Transformer mannequin for environment friendly video characteristic compression.
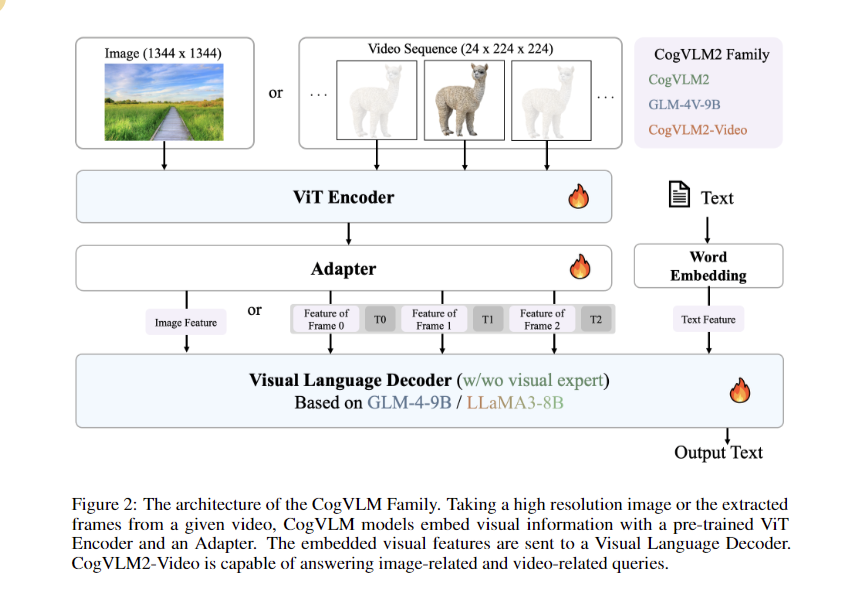
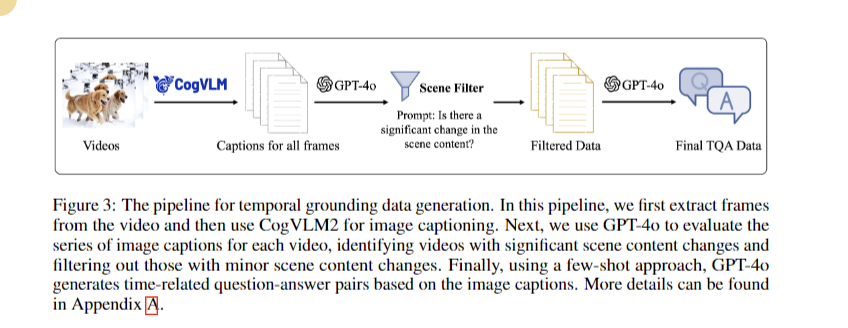
CogVLM2’s methodology makes use of substantial datasets, together with 330,000 video samples and an in-house video QA dataset, to reinforce temporal understanding. The analysis pipeline includes producing and evaluating video captions utilizing GPT-4o to filter movies based mostly on scene content material modifications. Two mannequin variants, cogvlm2-video-llama3-base, and cogvlm2-video-llama3-chat, serve completely different software situations, with the latter fine-tuned for enhanced temporal grounding. The coaching course of happens on an 8-node NVIDIA A100 cluster, accomplished in roughly 8 hours.
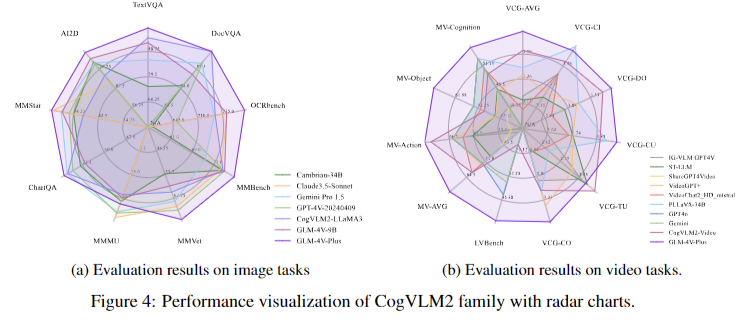
CogVLM2, notably the CogVLM2-Video mannequin, achieves state-of-the-art efficiency throughout a number of video question-answering duties, excelling in benchmarks like MVBench and VideoChatGPT-Bench. The fashions additionally outperform present fashions, together with bigger ones, in image-related duties, with notable success in OCR comprehension, chart and diagram understanding, and basic question-answering. Complete analysis reveals the fashions’ versatility in duties similar to video era and summarization, establishing CogVLM2 as a brand new customary for visible language fashions in each picture and video understanding.
In conclusion, the CogVLM2 household marks a big development in integrating visible and language modalities, addressing the restrictions of conventional text-only fashions. The event of fashions able to deciphering and producing content material from pictures and movies broadens their software in fields similar to doc evaluation, GUI comprehension, and video grounding. Architectural improvements, together with the Visible Knowledgeable and high-resolution cross-modules, improve efficiency in complicated visual-language duties. The CogVLM2 collection units a brand new benchmark for open-source visible language fashions, with detailed methodologies for dataset era supporting its strong capabilities and future analysis alternatives.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and LinkedIn. Be a part of our Telegram Channel.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Know-how (IIT), Kharagpur. With a powerful ardour for Knowledge Science, he’s notably within the numerous purposes of synthetic intelligence throughout varied domains. Shoaib is pushed by a need to discover the most recent technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sector of AI


