
Giant Language Fashions (LLMs) have revolutionized software program growth by enabling code completion, purposeful code technology from directions, and complicated code modifications for bug fixes and have implementations. Whereas these fashions excel at producing code from pure language directions, important challenges persist in evaluating the standard of LLM-generated code. The crucial facets requiring evaluation embody code correctness, effectivity, safety vulnerabilities, adherence to greatest practices, and alignment with developer preferences. The analysis course of turns into significantly complicated when balancing these a number of high quality dimensions concurrently. The systematic research of code preferences and the event of efficient desire fashions nonetheless must be explored regardless of its essential function in optimizing LLM efficiency and making certain that generated code meets real-world growth requirements.
Choice optimization has emerged as a vital step in aligning LLMs with desired outcomes, using each offline and on-line algorithms to boost mannequin efficiency. Earlier approaches have primarily relied on accumulating desire information by means of paired comparisons of most popular and rejected responses. These strategies usually collect information by means of human annotations, LLM suggestions, code execution outcomes, or current desire fashions. Whereas some methods have explored coaching LLM-as-a-Choose methods, these approaches have largely centered on pure language technology somewhat than specialised code technology. The present strategies face explicit challenges within the code area, the place desire ideas are extra specialised and complicated, involving technical facets like effectivity and safety which can be considerably harder to judge than common language preferences. The labeling course of for code preferences presents distinctive challenges that current approaches haven’t adequately addressed.
The researchers from the College of Illinois Urbana-Champaign and AWS AI Labs have developed CODEFAVOR, a sturdy framework for coaching code desire fashions, alongside CODEPREFBENCH, a complete analysis benchmark. CODEFAVOR implements a pairwise modeling strategy to foretell preferences between code pairs based mostly on user-specified standards. The framework introduces two modern artificial information technology strategies: Commit-Instruct, which transforms pre- and post-commit code snippets into desire pairs, and Critic-Evol, which generates desire information by bettering defective code samples utilizing a critic LLM. The analysis framework, CODEPREFBENCH, contains 1,364 fastidiously curated desire duties that assess varied facets, together with code correctness, effectivity, safety, and common developer preferences. This twin strategy addresses each the technical problem of constructing efficient desire fashions and the empirical query of understanding how human annotators and LLMs align of their code preferences.
The CODEFAVOR framework implements a complicated pairwise modeling strategy utilizing decoder-based transformers for studying code preferences. The mannequin processes enter comprising an instruction, two code candidates, and a selected criterion formatted in a structured immediate. The framework gives two distinct output designs: a classification strategy that makes binary predictions by means of a single next-token likelihood comparability and a generative strategy that gives pure language explanations for desire choices. The structure incorporates two modern artificial information technology strategies: Commit-Instruct, which processes uncooked code commits by means of a three-step pipeline of reasoning, filtering, and rephrasing, and Critic-Evol, which generates desire information by means of a three-stage means of fault sampling, critique filtering, and code revision. Within the Commit-Instruct pipeline, a critic LLM analyzes commits to remodel them into coaching samples, whereas Critic-Evol makes use of the interplay between a weaker draft mannequin and a stronger critic mannequin to generate artificial desire pairs.
The researchers have carried out a complete analysis of code desire fashions, together with insights from human developer annotations in addition to comparisons between current LLMs and the proposed CODEFAVOR framework.
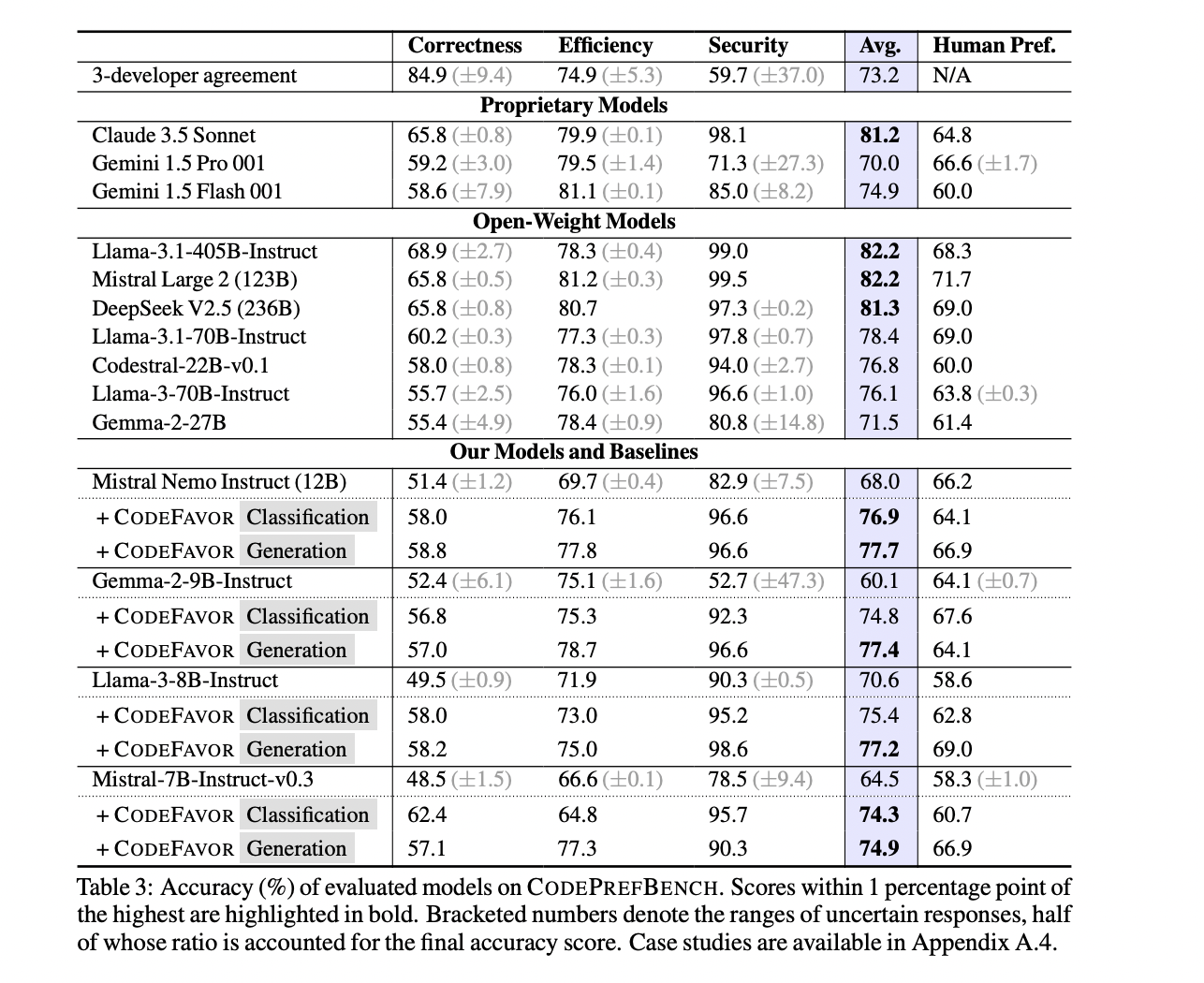
The human annotation efforts reveal a number of key insights. The developer crew consists of skilled programmers, with two-thirds holding pc science levels and 95% having over 2 years of coding expertise. The builders exhibit excessive confidence of their annotations, significantly for code correctness, although they battle extra with evaluating effectivity and safety facets. The annotation course of is time-consuming, with every activity taking a mean of seven.8 minutes per developer.
By way of accuracy, human builders excel at figuring out right code, attaining an 84.9% clear up price. Nonetheless, their efficiency drops for effectivity (74.9%) and is weakest for safety (59.7%), as they battle to precisely assess non-functional code properties which will require specialised experience.
The researchers then consider a spread of current LLMs, together with large-scale fashions like Llama-3.1-405B-Instruct and smaller fashions like Gemma-2-9B-Instruct. Whereas the bigger fashions typically outperform the smaller ones, the CODEFAVOR framework is ready to considerably enhance the efficiency of the smaller fashions, in some instances even surpassing the bigger critic fashions.
Particularly, CODEFAVOR improves the general efficiency of the smaller 7-12B fashions by 9.3-28.8% relative to their baseline efficiency. For code correctness, CODEFAVOR boosts the smaller fashions by 8.8-28.7%, permitting them to surpass the efficiency of the critic mannequin (Llama-3-70B-Instruct) by as much as 12%. Related enhancements are noticed for effectivity and safety preferences.
Importantly, the CODEFAVOR fashions not solely show robust efficiency but additionally provide important value benefits. Whereas human annotation prices an estimated $6.1 per activity, the CODEFAVOR classification mannequin fine-tuned on Mistral Nemo Instruct is 5 orders of magnitude cheaper, at 34 occasions inexpensive than the Llama-3-70B-Instruct critic mannequin, whereas attaining comparable or higher desire outcomes.


The researchers have launched CODEFAVOR, a sturdy framework for coaching pairwise code desire fashions utilizing artificial information generated from code commits and LLM critiques. They curated CODEPREFBENCH, a benchmark of 1,364 code desire duties, to analyze the alignment between human and LLM preferences throughout correctness, effectivity, and safety. CODEFAVOR considerably boosts the power of smaller instruction-following fashions to be taught code preferences, attaining on-par efficiency with bigger fashions at a fraction of the price. The research gives insights into the challenges of aligning code technology preferences throughout a number of dimensions.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Mannequin Depot: An Intensive Assortment of Small Language Fashions (SLMs) for Intel PCs
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the functions of machine studying in healthcare.


