
Giant Language Fashions (LLMs) have gained vital consideration in recent times, with researchers specializing in bettering their efficiency throughout varied duties. A vital problem in creating these fashions lies in understanding the affect of pre-training knowledge on their total capabilities. Whereas the significance of various knowledge sources and computational assets has been established, a vital query stays: what properties of information contribute most successfully to normal efficiency? Surprisingly, code knowledge has change into a standard element in pre-training mixtures, even for fashions not explicitly designed for code technology. This inclusion raises questions in regards to the exact affect of code knowledge on non-code duties. This subject has but to be systematically investigated regardless of its potential significance in advancing LLM capabilities.
Researchers have made quite a few makes an attempt to grasp and enhance LLM efficiency by knowledge manipulation. These efforts embody learning the consequences of information age, high quality, toxicity, and area, in addition to exploring strategies like filtering, de-duplication, and knowledge pruning. Some research have investigated the function of artificial knowledge in enhancing efficiency and bridging gaps between open-source and proprietary fashions. Whereas these approaches supply helpful insights into normal knowledge traits, they don’t particularly handle the affect of code knowledge on non-code duties.
The inclusion of code in pre-training mixtures has change into a standard apply, even for fashions not primarily designed for code-related duties. Earlier research recommend that code knowledge improves LLM efficiency on varied pure language processing duties, together with entity linking, commonsense reasoning, and mathematical reasoning. Some researchers have demonstrated the advantages of utilizing Python code knowledge in low-resource pre-training settings. Nevertheless, these research typically targeted on particular points or restricted analysis setups, missing a complete examination of code knowledge’s affect throughout varied duties and mannequin scales.
Researchers from Cohere For AI and Cohere carried out an in depth set of large-scale managed pre-training experiments to research the affect of code knowledge on LLM efficiency. Their examine targeted on varied points, together with the timing of code introduction within the coaching course of, code proportions, scaling results, and the standard and properties of the code knowledge used. Regardless of the numerous computational price of those ablations, the outcomes persistently demonstrated that code knowledge offers vital enhancements to non-code efficiency.
The examine’s key findings reveal that in comparison with text-only pre-training, the very best variant with code knowledge inclusion resulted in relative will increase of 8.2% in pure language reasoning, 4.2% in world data, 6.6% in generative win charges, and a 12-fold enhance in code efficiency. Additionally, performing cooldown with code led to further enhancements: 3.7% in pure language reasoning, 6.8% in world data, and 20% in code efficiency, relative to cooldown with out code.
A number of components proved essential, together with optimizing the proportion of code, enhancing code high quality by artificial code and code-adjacent knowledge, and using code throughout a number of coaching levels, together with calm down. The researchers carried out in depth evaluations on a variety of benchmarks, overlaying world data duties, pure language reasoning, code technology, and LLM-as-a-judge win charges. These experiments spanned fashions starting from 470 million to 2.8 billion parameters.
The analysis methodology concerned a complete experimental framework to guage the affect of code on LLM efficiency. The examine used SlimPajama, a high-quality textual content dataset, as the first supply for pure language knowledge, rigorously filtering out code-related content material. For code knowledge, researchers employed a number of sources to discover completely different properties:
1. Net-based Code Knowledge: Derived from the Stack dataset, specializing in the highest 25 programming languages.
2. Markdown Knowledge: Together with markup-style languages like Markdown, CSS, and HTML.
3. Artificial Code Knowledge: A proprietary dataset of formally verified Python programming issues.
4. Code-Adjoining Knowledge: Incorporating GitHub commits, Jupyter notebooks, and StackExchange threads.
The coaching course of consisted of two phases: continued pre-training and cooldown. Continued pre-training concerned coaching a mannequin initialized from a pre-trained mannequin for a hard and fast token price range. Cooldown, a method to spice up mannequin high quality, concerned up-weighting high-quality datasets and annealing the training charge through the closing coaching levels.
The analysis suite was designed to evaluate efficiency throughout varied domains: world data, pure language reasoning, and code technology. Additionally, the researchers employed LLM-as-a-judge win charges to guage generative efficiency. This complete strategy allowed for a scientific understanding of code’s affect on normal LLM efficiency past simply code-related duties.

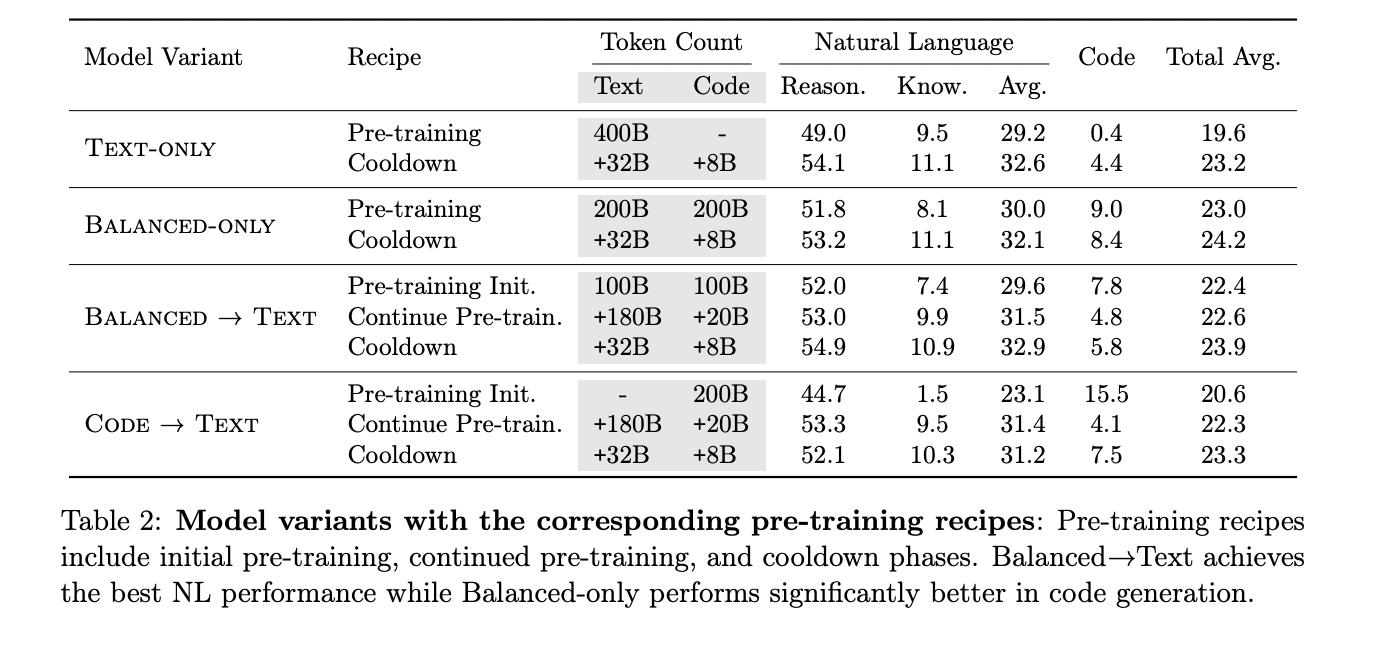
The examine revealed vital impacts of code knowledge on LLM efficiency throughout varied duties. For pure language reasoning, fashions initialized with code knowledge confirmed the very best efficiency. The code-initialized textual content mannequin (code→textual content) and the balanced-initialized textual content mannequin (balanced→textual content) outperformed the text-only baseline by 8.8% and eight.2% respectively. The balanced-only mannequin additionally confirmed a 3.2% enchancment over the baseline, indicating that initialization from a pre-trained mannequin with a mixture of code has a powerful optimistic impact on pure language reasoning duties.
In world data duties, the balanced→textual content mannequin carried out finest, surpassing the code→textual content mannequin by 21% and the text-only mannequin by 4.1%. This implies that world data duties profit from a extra balanced knowledge combination for initialization and a bigger proportion of textual content within the continuous pre-training stage.
For code technology duties, the balanced-only mannequin achieved the very best efficiency, exhibiting a 46.7% and 54.5% enchancment over balanced→textual content and code→textual content fashions respectively. Nevertheless, this got here at the price of decrease efficiency in pure language duties.
Generative high quality, as measured by win charges, additionally improved with the inclusion of code knowledge. Each code→textual content and balanced-only fashions outperformed the text-only variant by a 6.6% distinction in win-loss charges, even on non-code evaluations.
These outcomes display that together with code knowledge in pre-training not solely enhances reasoning capabilities but additionally improves the general high quality of generated content material throughout varied duties, highlighting the broad advantages of code knowledge in LLM coaching.
This examine offers new insights into the affect of code knowledge on LLM efficiency throughout a variety of duties. The researchers carried out a complete evaluation, focusing not solely on code-related duties but additionally on pure language efficiency and generative high quality. Their systematic strategy included varied ablations inspecting initialization methods, code proportions, code high quality and properties, and the function of code in pre-training cooldown.
Key findings from the examine embody:
- Code knowledge considerably improves non-code job efficiency. The perfect variant with code knowledge confirmed relative will increase of 8.2% in pure language reasoning, 4.2% in world data, and 6.6% in generative win charges in comparison with text-only pre-training.
- Code efficiency noticed a dramatic 12-fold enhance with the inclusion of code knowledge.
- Cooldown with code additional enhanced efficiency, bettering pure language reasoning by 3.6%, world data by 10.1%, and code efficiency by 20% relative to pre-cooldown fashions. This additionally led to a 52.3% improve in generative win charges.
- The addition of high-quality artificial code knowledge, even in small quantities, had a disproportionately optimistic affect, rising pure language reasoning by 9% and code efficiency by 44.9%.
These outcomes display that incorporating code knowledge in LLM pre-training results in substantial enhancements throughout varied duties, extending far past code-specific functions. The examine highlights the vital function of code knowledge in enhancing LLM capabilities, providing helpful insights for future mannequin improvement and coaching methods.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


