
One of many central challenges in Retrieval-Augmented Technology (RAG) fashions is effectively managing lengthy contextual inputs. Whereas RAG fashions improve giant language fashions (LLMs) by incorporating exterior info, this extension considerably will increase enter size, resulting in longer decoding occasions. This situation is essential because it immediately impacts person expertise by prolonging response occasions, significantly in real-time purposes resembling advanced question-answering methods and large-scale info retrieval duties. Addressing this problem is essential for advancing AI analysis, because it makes LLMs extra sensible and environment friendly for real-world purposes.
Present strategies to deal with this problem primarily contain context compression strategies, which might be divided into lexical-based and embedding-based approaches. Lexical-based strategies filter out unimportant tokens or phrases to scale back enter measurement however typically miss nuanced contextual info. Embedding-based strategies remodel the context into fewer embedding tokens, but they endure from limitations resembling giant mannequin sizes, low effectiveness as a result of untuned decoder elements, fastened compression charges, and inefficiencies in dealing with a number of context paperwork. These limitations limit their efficiency and applicability, significantly in real-time processing eventualities.
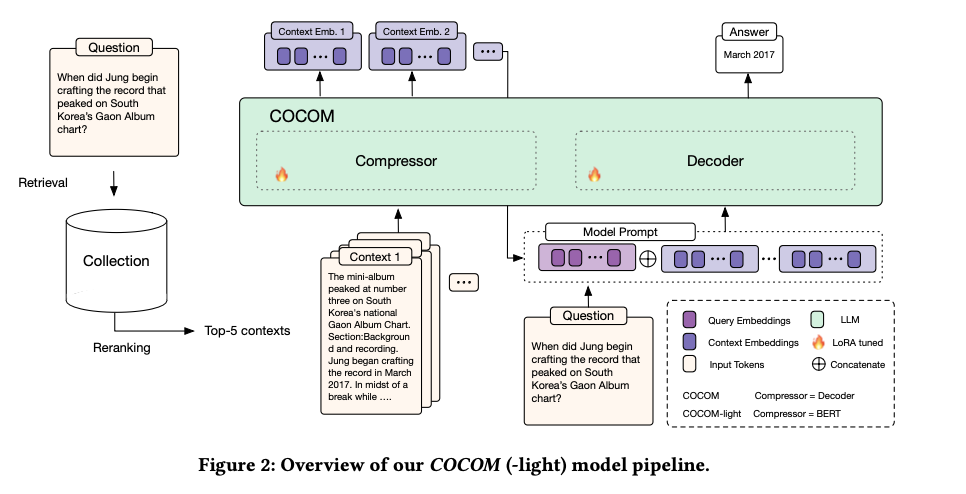
A crew of researchers from the College of Amsterdam, The College of Queensland, and Naver Labs Europe introduce COCOM (COntext COmpression Mannequin), a novel and efficient context compression methodology that overcomes the restrictions of current strategies. COCOM compresses lengthy contexts right into a small variety of context embeddings, considerably dashing up the era time whereas sustaining excessive efficiency. This methodology gives numerous compression charges, enabling a stability between decoding time and reply high quality. The innovation lies in its capability to effectively deal with a number of contexts, not like earlier strategies that struggled with multi-document contexts. Through the use of a single mannequin for each context compression and reply era, COCOM demonstrates substantial enhancements in pace and efficiency, offering a extra environment friendly and correct resolution in comparison with current strategies.
COCOM entails compressing contexts right into a set of context embeddings, considerably lowering the enter measurement for the LLM. The strategy consists of pre-training duties resembling auto-encoding and language modeling from context embeddings. The strategy makes use of the identical mannequin for each compression and reply era, making certain efficient utilization of the compressed context embeddings by the LLM. The dataset used for coaching consists of numerous QA datasets like Pure Questions, MS MARCO, HotpotQA, WikiQA, and others. Analysis metrics deal with Actual Match (EM) and Match (M) scores to evaluate the effectiveness of the generated solutions. Key technical points embody parameter-efficient LoRA tuning and the usage of SPLADE-v3 for retrieval.
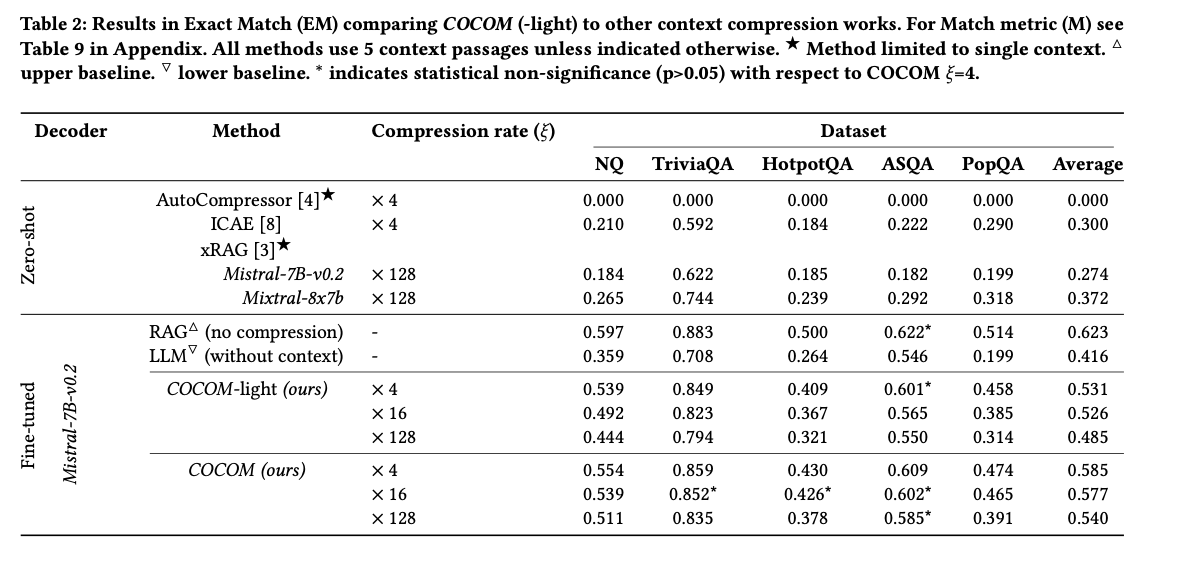
COCOM achieves vital enhancements in decoding effectivity and efficiency metrics. It demonstrates a speed-up of as much as 5.69 occasions in decoding time whereas sustaining excessive efficiency in comparison with current context compression strategies. For instance, COCOM achieved an Actual Match (EM) rating of 0.554 on the Pure Questions dataset with a compression fee of 4, and 0.859 on TriviaQA, considerably outperforming different strategies like AutoCompressor, ICAE, and xRAG. These enhancements spotlight COCOM’s superior capability to deal with longer contexts extra successfully whereas sustaining excessive reply high quality, showcasing the tactic’s effectivity and robustness throughout numerous datasets.
In conclusion, COCOM represents a major development in context compression for RAG fashions by lowering decoding time and sustaining excessive efficiency. Its capability to deal with a number of contexts and provide adaptable compression charges makes it a essential improvement for enhancing the scalability and effectivity of RAG methods. This innovation has the potential to drastically enhance the sensible software of LLMs in real-world eventualities, overcoming essential challenges and paving the way in which for extra environment friendly and responsive AI purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
If you happen to like our work, you’ll love our e-newsletter..
Don’t Overlook to hitch our 46k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.


