
LLMs reveal emergent intelligence with elevated parameters, computes, and information, hinting at synthetic basic intelligence. Regardless of developments, deployed LLMs nonetheless exhibit errors like hallucinations, bias, and factual inaccuracies. Additionally, the fixed evolution of data challenges their pretraining. Addressing errors promptly throughout deployment is essential, as retraining or finetuning is commonly prohibitively pricey, posing sustainability points for accommodating lifelong information progress.
Whereas long-term reminiscence may be up to date by means of (re)pretraining, finetuning, and mannequin enhancing, working reminiscence aids inference, enhanced by strategies like GRACE. Nonetheless, debates persist on the efficacy of fine-tuning versus retrieval. Present information injection strategies face challenges like computational overhead and overfitting. Mannequin enhancing strategies, together with constrained finetuning and meta-learning, goal to effectively edit LLMs. Latest developments concentrate on lifelong enhancing however require in depth domain-specific coaching, posing challenges in predicting upcoming edits and accessing related information.
After finding out the above points and approaches completely, researchers from Zhejiang College and Alibaba Group suggest their methodology, WISE, a twin parametric reminiscence scheme, comprising a important reminiscence for pretrained information and a aspect reminiscence for edited information. Solely the aspect reminiscence undergoes edits, with a router figuring out which reminiscence to entry for queries. For continuous enhancing, WISE employs a knowledge-sharing mechanism, segregating edits into distinct parameter subspaces to stop conflicts earlier than merging them right into a shared reminiscence.
WISE includes two important elements: Aspect Reminiscence Design and Information Sharding and Merging. The previous entails a aspect reminiscence, initialized as a duplicate of a sure FFN layer of the LLM, storing edits, and a routing mechanism for reminiscence choice throughout inference. The latter employs information sharding to divide edits into random subspaces for enhancing and information merging strategies to mix these subspaces right into a unified aspect reminiscence. Additionally, WISE introduces WISE-Retrieve, permitting retrieval amongst a number of aspect recollections primarily based on activation scores, enhancing lifelong enhancing eventualities.
WISE demonstrates superior efficiency in comparison with present strategies in each QA and Hallucination settings. It outperforms rivals, significantly in lengthy enhancing sequences, reaching vital enhancements in stability and managing sequential edits successfully. Whereas strategies like MEND and ROME are aggressive initially, they falter as edit sequences lengthen. Immediately enhancing long-term reminiscence results in vital declines in locality, impairing generalization. GRACE excels in locality however sacrifices generalization in continuous enhancing. WISE achieves a steadiness between reliability, generalization, and locality, outperforming baselines throughout numerous duties. In out-of-distribution analysis, WISE displays glorious generalization efficiency, surpassing different strategies.
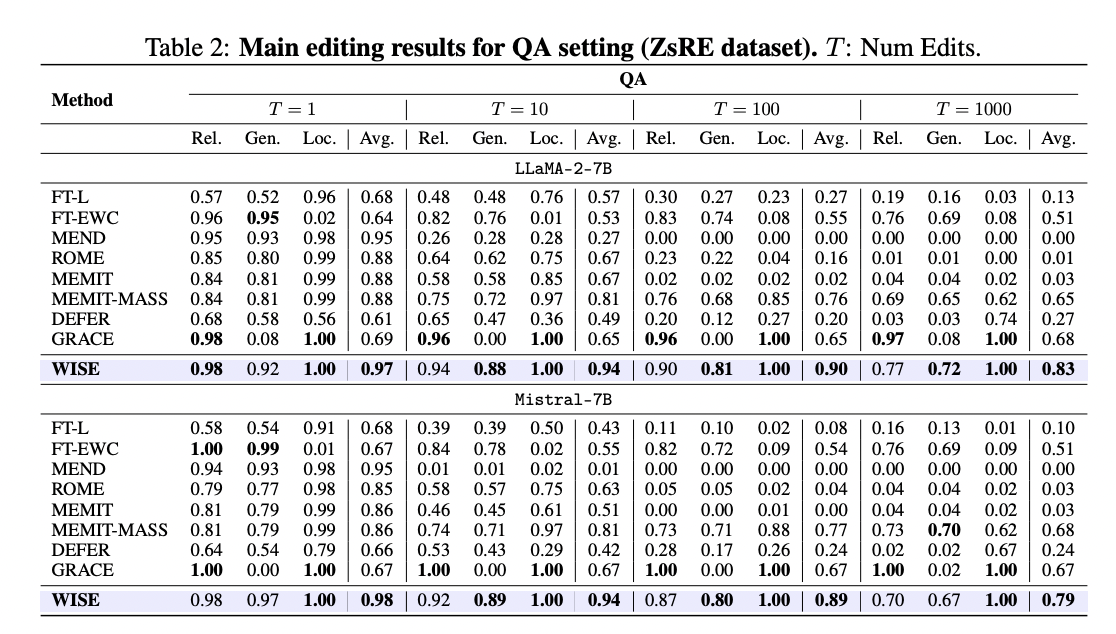
This analysis identifies the problem of reaching reliability, generalization, and locality concurrently in present lifelong modeling enhancing approaches, attributing it to the hole between working and long-term reminiscence. To beat this challenge, WISE is proposed, comprising aspect reminiscence and mannequin merging strategies. Outcomes point out that WISE reveals promise in concurrently reaching excessive metrics throughout numerous datasets and LLM fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


