
Giant Language Fashions (LLMs) have gained important consideration resulting from their exceptional efficiency throughout numerous duties, revolutionizing analysis paradigms. Nonetheless, the coaching course of for these fashions faces a number of challenges. LLMs rely on static datasets and endure lengthy coaching durations, which require a whole lot of computational sources. For instance, coaching the LLaMA 65B mannequin took 21 days utilizing 2048 A100 GPUs with 80GB of RAM. This methodology poses limitations in adapting to modifications in knowledge composition or containing new info. So, it is very important develop extra environment friendly and versatile coaching methodologies for LLMs to enhance their adaptability and cut back computational calls for.
Researchers from the Language Basis Mannequin & Software program Workforce at BAAI have proposed the Aquila2 sequence, a variety of AI fashions with parameter sizes from 7 to 70 billion. These fashions are skilled utilizing the HeuriMentor (HM) Framework, which accommodates three important parts, (a) the Adaptive Coaching Engine (ATE), (b) the Coaching State Monitor (TSM), and (c) the Information Administration Unit (DMU). This method enhances the monitoring of the mannequin’s coaching progress and permits for environment friendly changes to the info distribution, making coaching more practical. The HM Framework is designed to deal with the challenges of adapting to modifications in knowledge and incorporating new info, offering a extra versatile and environment friendly approach to prepare LLMs.
The Aquila2 structure consists of a number of vital options to reinforce its efficiency and effectivity. The tokenizer makes use of a 100,000-word vocabulary, chosen via preliminary experiments, and applies Byte Pair Encoding (BPE) to extract this vocabulary. The coaching knowledge is evenly break up between English and Chinese language, utilizing the Pile and WudaoCorpus datasets. Aquila2 makes use of the Grouped Question Consideration (GQA) mechanism, which improves effectivity throughout inference in comparison with conventional multi-head consideration whereas sustaining related high quality. The mannequin makes use of a preferred methodology of LLMs, referred to as Rotary Place Embedding (RoPE), for place embedding. RoPE combines the advantages of relative and absolute place encoding, to seize patterns effectively in sequence knowledge.
The efficiency of the Aquila2 mannequin has been completely evaluated and in contrast with different main bilingual (Chinese language-English) fashions launched earlier than December 2023. The fashions included for comparisons are Baichuan2, Qwen, LLaMA2, and InternLM, every having distinctive traits and parameter sizes. Baichuan2 affords 7B and 13B variations skilled on 2.6 trillion tokens. Qwen presents an entire sequence of fashions, with chat-optimized variations. LLaMA2 ranges from 7B to 70B parameters, with fine-tuned chat variations. InternLM exhibits an enormous 104B parameter mannequin skilled on 1.6 trillion tokens, with 7B and 20B variations. These comparisons throughout numerous datasets present an in depth evaluation of Aquila2’s capabilities.
The Aquila2-34B mannequin exhibits sturdy efficiency throughout numerous NLP duties, attaining the very best imply rating of 68.09 in comparative evaluations. It performs properly in English (68.63 common) and Chinese language (76.56 common) language duties. Aquila2-34B outperforms LLaMA2-70B in bilingual understanding, attaining its high rating of 81.18 within the BUSTM job. Furthermore, Aquila2-34B leads within the difficult HumanEval job with a rating of 39.02, indicating sturdy human-like understanding. The analysis reveals a aggressive panorama throughout numerous fashions, with shut contests in duties like TNEWS and C-Eval. These outcomes present the necessity for thorough evaluations in various duties to grasp mannequin capabilities and drive NLP progress.
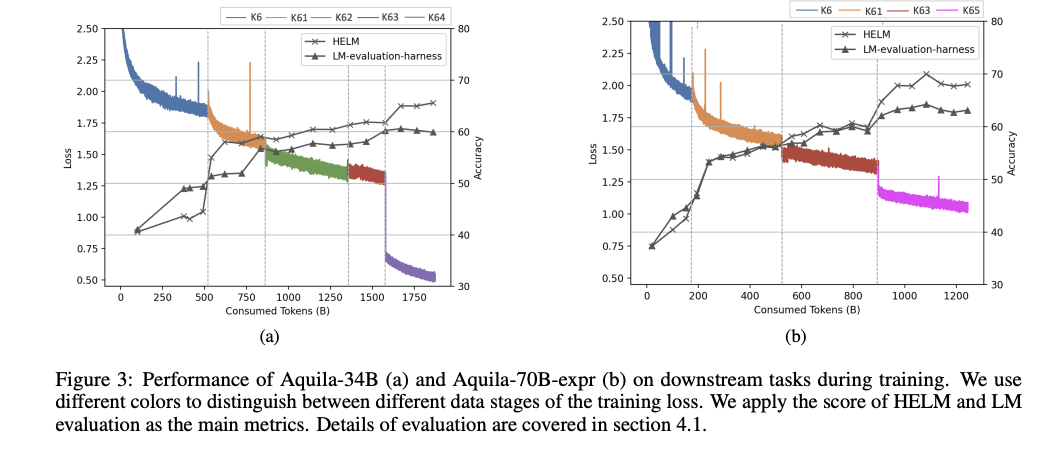
In conclusion, Researchers from the Language Basis Mannequin & Software program Workforce at BAAI have proposed the Aquila2 sequence, a variety of bilingual fashions with parameter sizes from 7 to 70 billion. Aquila2-34B exhibits superior efficiency throughout 21 various datasets, outperforming LLaMA-2-70B-expr and different benchmarks, even below 4-bit quantization. Furthermore, the HM framework developed by researchers, allows dynamic changes to knowledge distribution throughout coaching, leading to sooner convergence and enhanced mannequin high quality. Future analysis consists of exploring Combination-of-Specialists and bettering knowledge high quality. Nonetheless, incorporating GSM8K check knowledge in pre-training might have an effect on the validity of Aquila2’s outcomes, requiring warning in future comparisons.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 48k+ ML SubReddit
Discover Upcoming AI Webinars right here

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.


