Massive Language Fashions (LLMs) have made a major leap in recent times, however their inference course of faces challenges, notably within the prefilling stage. The first problem lies within the time-to-first-token (TTFT), which will be gradual for lengthy prompts as a result of deep and vast structure of state-of-the-art transformer-based LLMs. This slowdown happens as a result of the price of computing consideration will increase quadratically with the variety of tokens within the prompts. For instance, Llama 2 with 7 billion parameters requires 21 occasions extra time for TTFT in comparison with every subsequent decoding step, accounting for about 23% of the overall technology time on the LongBench benchmark. Optimizing TTFT has change into a important path towards environment friendly LLM inference.
Prior research have explored varied approaches to handle the challenges of environment friendly long-context inference and TTFT optimization in LLMs. Some strategies concentrate on modifying transformer architectures, akin to changing customary self-attention with native windowed consideration or utilizing locality-sensitive hashing. Nonetheless, these require important mannequin modifications and retraining. Different methods optimize the KV cache to speed up decoding steps however don’t deal with TTFT. Token pruning approaches, which selectively take away much less necessary tokens throughout inference, have proven promise in sentence classification duties. Examples embody Realized Token Pruning and width-wise computation discount. Nonetheless, these strategies have been designed for single-iteration processing duties and wish adaptation for generative LLMs. Every strategy has limitations, prompting the necessity for extra versatile options that may enhance TTFT with out intensive mannequin modifications.
Researchers from Apple and Meta AI suggest LazyLLM, a singular method to speed up LLM prefilling by selectively computing the KV cache for necessary tokens and deferring much less essential ones. It makes use of consideration scores from earlier layers to evaluate token significance and prune progressively. In contrast to everlasting immediate compression, LazyLLM can revive pruned tokens to keep up accuracy. An Aux Cache mechanism shops pruned tokens’ hidden states, making certain environment friendly revival and stopping efficiency degradation. LazyLLM presents three key benefits: universality (appropriate with any transformer-based LLM), training-free implementation, and effectiveness throughout varied language duties. This technique improves inference velocity in each prefilling and decoding levels with out requiring mannequin modifications or fine-tuning.
The LazyLLM framework is designed to optimize LLM inference by progressive token pruning. The strategy begins with the total context and progressively reduces computations in the direction of the top of the mannequin by pruning much less necessary tokens. In contrast to static pruning, LazyLLM permits the dynamic collection of token subsets in numerous technology steps, essential for sustaining efficiency.
This framework employs layer-wise token pruning in every technology step, utilizing consideration maps to find out token significance. It calculates a confidence rating for every token and prunes these under a sure percentile. This strategy is utilized progressively, holding extra tokens in earlier layers and lowering them in the direction of the top of the transformer.
To beat the challenges in extending pruning to decoding steps, LazyLLM introduces an Aux Cache mechanism. This cache shops hidden states of pruned tokens, permitting environment friendly retrieval with out recomputation. Throughout decoding, the mannequin first accesses the KV cache for present tokens and retrieves hidden states from the Aux Cache for pruned tokens. Additionally, this implementation ensures every token is computed at most as soon as per transformer layer, guaranteeing that LazyLLM’s worst-case runtime isn’t slower than the baseline. The strategy’s dynamic nature and environment friendly caching mechanism contribute to its effectiveness in optimizing each the prefilling and decoding levels of LLM inference.
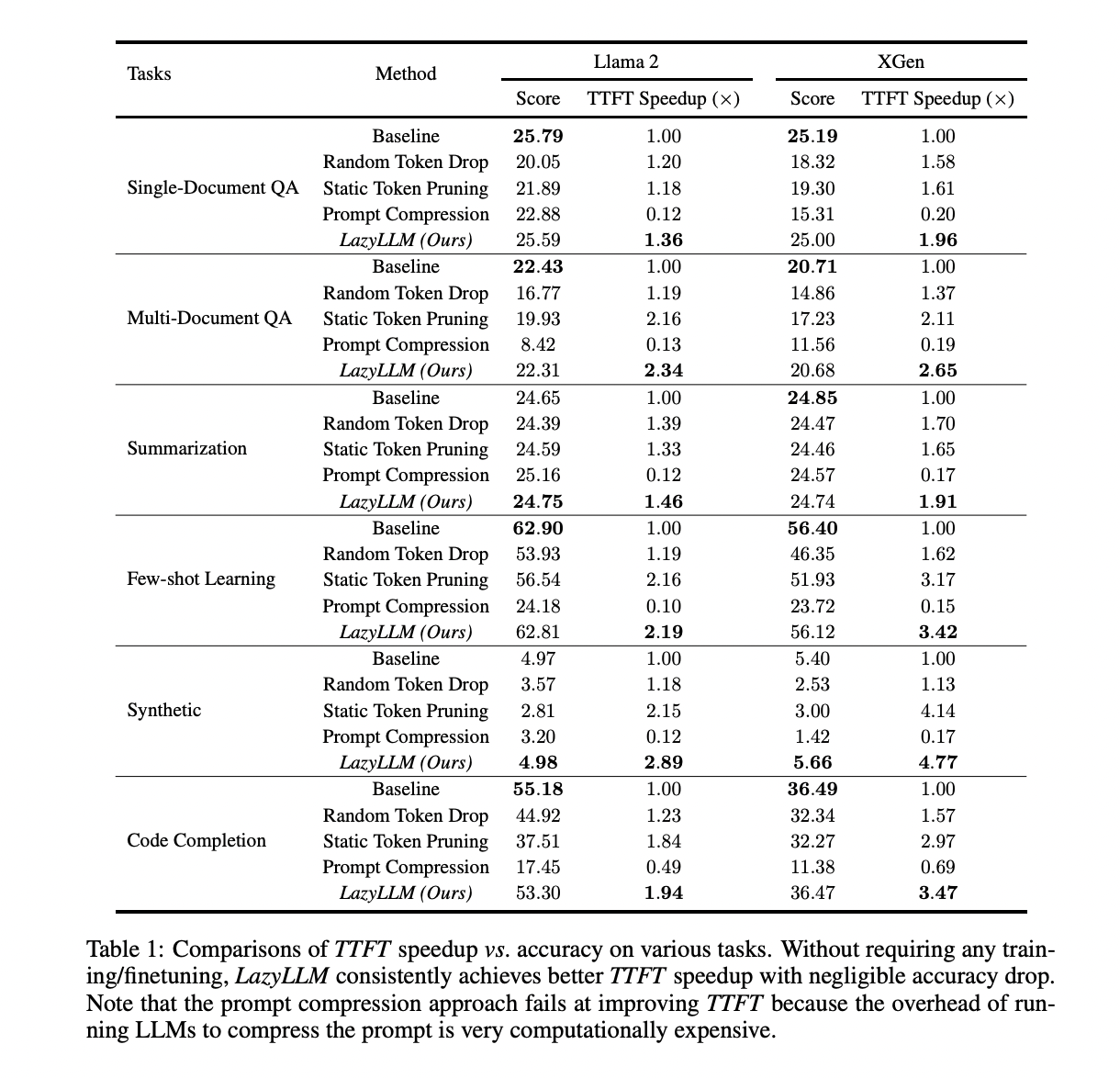
LazyLLM demonstrates important enhancements in LLM inference effectivity throughout varied language duties. It achieves substantial TTFT speedups (as much as 2.89x for Llama 2 and 4.77x for XGen) whereas sustaining accuracy near baseline ranges. The strategy outperforms different approaches like random token drop, static pruning, and immediate compression in speed-accuracy trade-offs. LazyLLM’s effectiveness spans a number of duties, together with QA, summarization, and code completion. It typically computes lower than 100% of immediate tokens, resulting in decreased total computation and improved technology speeds. The progressive pruning technique, knowledgeable by layer-wise evaluation, contributes to its superior efficiency. These outcomes spotlight LazyLLM’s capability to optimize LLM inference with out compromising accuracy.
LazyLLM, an modern method for environment friendly LLM inference, notably in lengthy context eventualities, selectively computes KV for necessary tokens and defers computation of much less related ones. In depth analysis throughout varied duties demonstrates that LazyLLM considerably reduces TTFT whereas sustaining efficiency. A key benefit is its seamless integration with present transformer-based LLMs, bettering inference velocity with out fine-tuning. By dynamically prioritizing token computation based mostly on relevance, LazyLLM presents a sensible answer to boost LLM effectivity, addressing the rising demand for sooner and extra resource-efficient language fashions in various purposes.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the purposes of machine studying in healthcare.