
Finish-to-end (E2E) neural networks have emerged as versatile and correct fashions for multilingual computerized speech recognition (ASR). Nevertheless, because the variety of supported languages will increase, notably these with giant character units like Chinese language, Japanese, and Korean (CJK), the output layer dimension grows considerably. This enlargement negatively impacts compute assets, reminiscence utilization, and asset dimension. The problem turns into extra pronounced in multilingual methods, the place the output typically consists of unions of characters or subwords from varied languages. Researchers are thus grappling with the necessity to preserve mannequin effectivity and efficiency whereas accommodating a various vary of languages and their related character units in E2E ASR methods.
Earlier makes an attempt to handle these challenges in multilingual ASR have targeted on byte-level representations, notably utilizing UTF-8 codewords as base tokens. This method permits for a set output vocabulary dimension of 256, offering compactness and universality throughout languages. Nevertheless, byte-level representations typically lead to longer sequences, particularly for CJK languages, probably rising error charges as a number of predictions are required for single characters. Researchers proposed byte-level subwords utilizing byte pair encoding (BPE) on UTF-8 codeword sequences to mitigate this. Whereas this lowered the variety of decoding steps, it didn’t assure legitimate UTF-8 outputs. A dynamic programming algorithm was later launched to get better legitimate characters from probably invalid byte sequences, although this methodology optimized for character validity slightly than ASR high quality.
The state-of-the-art methodology reviewed by Apple researchers proposes a strong illustration studying method utilizing a vector quantized auto-encoder. This methodology goals to optimize byte-level illustration particularly for E2E ASR duties, addressing the constraints of earlier approaches. The framework is designed to be data-driven, incorporating info from each textual content and audio to boost accuracy. It affords flexibility to incorporate further aspect info, similar to lexicons or phonemes, making it adaptable to numerous ASR situations. Importantly, the tactic contains an error correction mechanism to deal with invalid sequences, with restoration optimized for accuracy slightly than different metrics. This method aligns with the researchers’ standards for an excellent byte-level illustration: task-specific optimization, complete info utilization, and efficient error correction.
The proposed methodology formulates the illustration drawback as an optimization process with latent variables, utilizing a vector quantized auto-encoder (VQ-AE) structure. This auto-encoder consists of 4 key parts: a label encoder, an acoustic encoder, a label decoder, and a vector quantizer. The system makes use of vector quantization as its bottleneck, with the indices of quantized embeddings serving as latent variables.
The auto-encoder is optimized utilizing a loss perform comprising 4 phrases: cross-entropy losses for label and acoustic encoders, a CTC loss for the acoustic encoder, and a quantization loss. The strategy employs a Residual VQ-VAE (RVQ-VAE) with two or three codebooks, every containing 256 embeddings, permitting every label token to be represented by 2-3 bytes.
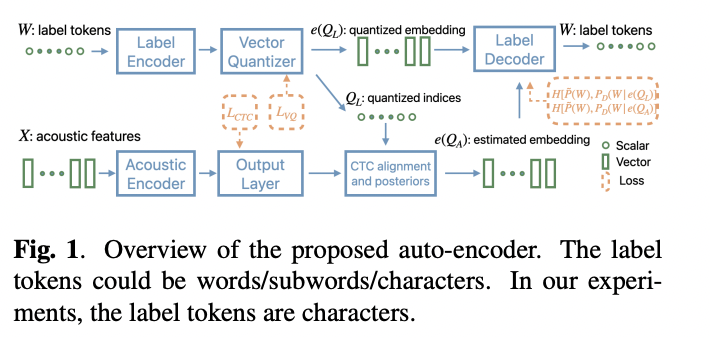
To deal with potential errors in byte sequences, the system incorporates an error correction mechanism by way of the label decoder. This decoder estimates the almost certainly label sequence, optimizing for accuracy even when confronted with invalid byte sequences. The proposed VQ-based illustration affords benefits over UTF-8, together with fixed-length coding, task-specific optimization, and improved error restoration.
The researchers evaluated their proposed VQ-based illustration method on bilingual English and Mandarin dictation duties, evaluating it with character-based and UTF-8 subword outputs. Utilizing a CTC-AED mannequin with roughly 120M parameters, they examined varied output representations on datasets comprising 10k hours of English and 14k hours of Mandarin coaching knowledge.
Outcomes confirmed that the VQ-based illustration constantly outperformed UTF-8 subword outputs throughout completely different subword sizes. With 8000 subwords, the VQ-based method achieved a 5.8% relative discount in Phrase Error Price (WER) for English and a 3.7% relative discount in Character Error Price (CER) for Mandarin in comparison with UTF-8. When in comparison with character-based output, each VQ and UTF-8 representations carried out higher on English, whereas sustaining comparable accuracy for Mandarin. Notably, the VQ-based methodology with 8000 subwords demonstrated a 14.8% relative error price discount for English and a 2.3% discount for Mandarin in comparison with character-based output, highlighting its effectiveness and suppleness in multilingual ASR methods.
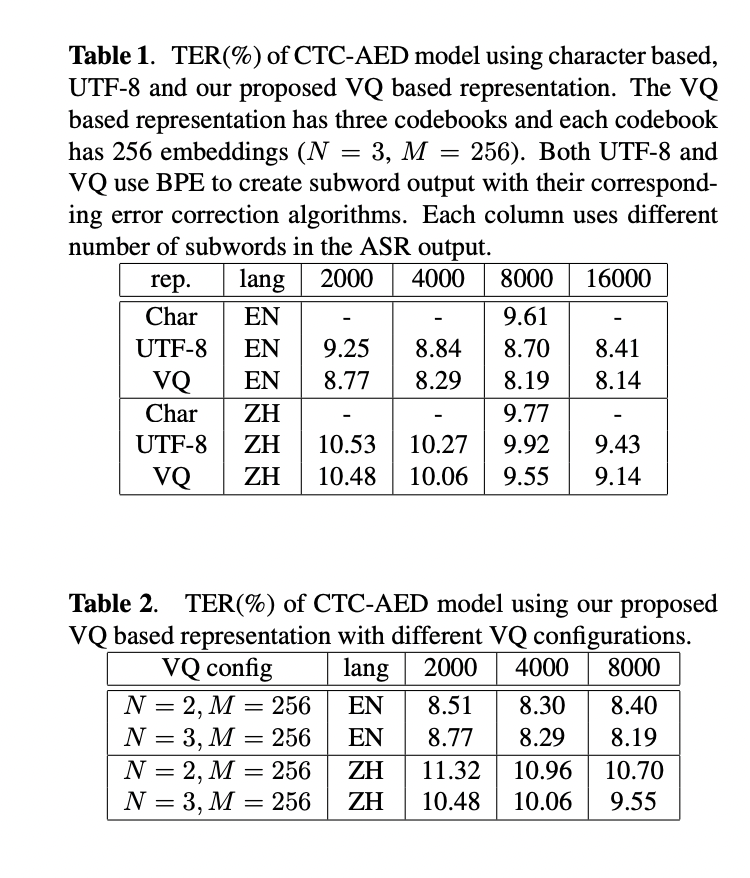
This examine presents a strong algorithm for optimizing byte-level illustration in ASR, providing a substitute for UTF-8 illustration. This method could be optimized utilizing audio and textual content knowledge, with an error correction mechanism designed to boost accuracy. Testing on English and Mandarin dictation datasets demonstrated a 5% relative discount in Token Error Price (TER) in comparison with UTF-8-based strategies. Whereas the present examine targeted on bilingual ASR, the researchers acknowledge challenges in growing a common illustration for all languages, such because the index collapse subject.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Asjad is an intern marketing consultant at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Expertise, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


