
Latest analysis has targeted on crafting superior Multimodal Massive Language Fashions (MLLMs) that seamlessly combine visible and textual information complexities. By delving into the trivialities of architectural design, information choice, and methodological transparency, analysis has pushed the boundaries of what MLLMs can obtain and assist future explorations. Their work is especially notable for its complete method to dissecting the varied parts that contribute to the success of those fashions, shedding mild on the pivotal roles performed by picture encoders, vision-language connectors, and the strategic amalgamation of numerous information sorts.
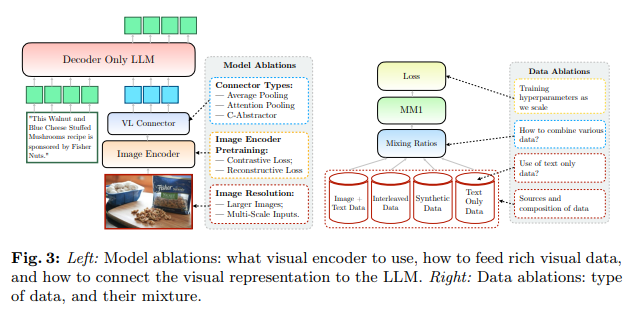
The researchers at Apple construct MM1, a household of cutting-edge multimodal fashions with as much as 30 billion parameters. They’ve taken a unique path of openness and detailed documentation, offering useful insights into setting up MLLMs. Their meticulous documentation covers every part from the selection of picture encoders to the intricacies of connecting visible information with linguistic components, providing a transparent roadmap for constructing more practical and clear fashions.
One of many examine’s key revelations is the numerous affect of fastidiously chosen pre-training information on the mannequin’s efficiency. The researchers found {that a} considered mixture of image-caption pairs, interleaved image-text paperwork, and text-only information is important for reaching superior outcomes, notably in few-shot studying eventualities. It highlights the significance of range in coaching information, which allows fashions to higher generalize throughout completely different duties and settings.
The suite of MM1 fashions represents a major leap ahead, able to reaching aggressive efficiency throughout a big selection of benchmarks. What units MM1 aside is its sheer scale and its architectural improvements, together with dense fashions and mixture-of-experts variants. These fashions display the effectiveness of the researchers’ method, combining large-scale pre-training with strategic information choice to reinforce the mannequin’s studying capabilities.
Key Takeaways from the analysis embody:
- Researchers from Apple led a complete examine on MLLMs, specializing in architectural and information choice methods.
- Transparency and detailed documentation have been prioritized to facilitate future analysis.
- A balanced mixture of numerous pre-training information was essential for mannequin efficiency.
- MM1, a brand new household of fashions with as much as 30 billion parameters, was launched, showcasing superior efficiency throughout benchmarks.
- The examine’s findings emphasize the importance of methodological selections in advancing MLLM improvement.
In conclusion, this analysis represents a major development within the area of MLLMs, providing new insights into the optimum building of those advanced fashions. By highlighting the significance of transparency, detailed documentation, and strategic information choice, the examine paves the best way for future improvements. The introduction of MM1 underscores the potential of well-designed MLLMs to set new requirements in multimodal understanding. The ideas and findings outlined on this examine will unlock the complete potential of multimodal language fashions.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
For those who like our work, you’ll love our publication..
Don’t Overlook to hitch our 38k+ ML SubReddit
Hey, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m at the moment pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m captivated with expertise and wish to create new merchandise that make a distinction.


