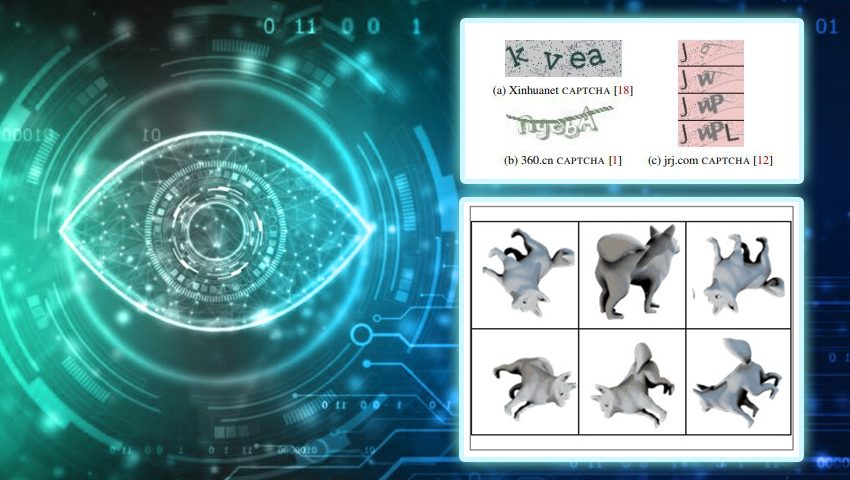
Developed 20 years in the past to forestall hackers from stealing content material, inserting malicious posts, partaking in fraudulent transactions, or slowing down web sites to the purpose of full inoperability, the acronym of this ubiquitous defensive position clearly defines its mission: Utterly Automated Public Turing check to inform Computer systems and People Aside – CAPTCHA.
For nearly twenty years, CAPTCHAs have been extensively used as a way of safety towards bots. Over time, as their utilization unfold, strategies for bypassing or deceiving CAPTCHAs continued to enhance. Nonetheless, CAPTCHAs have additionally developed by way of complexity and variety, changing into more and more difficult to resolve for each bots (machines) and people. Given this long-term and nonetheless related technological competitors, it’s critically vital to analyze how a lot time respectable customers require to resolve trendy CAPTCHAs and the way they’re perceived by these customers.
At the moment, CAPTCHAs nonetheless stay one of many major considerations for customers.
Nonetheless, researchers from the College of California, Irvine, have concluded that bots appear to resolve them higher than people.
Of their work, scientists research CAPTCHAs in pure situations, assessing customers’ efficiency in fixing them and their notion of the at the moment used CAPTCHAs. They gather these information by way of guide checks of well-liked web sites and consumer research by which 1 400 individuals collectively solved 14 000 CAPTCHAs. The outcomes present vital variations between the most well-liked varieties of CAPTCHAs: surprisingly, the time it takes to resolve and customers’ notion don’t at all times correlate. A comparative research was carried out to look at the affect of the experimental context – particularly, the distinction between fixing CAPTCHAs straight and fixing them as a part of a extra pure process, resembling creating an account. Regardless of a number of doubtlessly confounding components, the outcomes indicated that the experimental context can affect this process and must be thought of in future CAPTCHA analysis. The researchers additionally discover customers’ refusal to finish duties attributable to CAPTCHAs, analyzing individuals who begin a process and don’t end it.
They discovered that bots not solely resolve numerous types of CAPTCHAs, resembling picture recognition, slider puzzles, and distorted textual content, higher but in addition sooner.
As CAPTCHAs evolve by way of complexity and variety, they develop into more and more tough to resolve for each bots (machines) and people. Nonetheless, with the event of pc imaginative and prescient and machine studying, bots’ talents in recognizing distorted textual content have considerably elevated, reaching an accuracy of over 99%. Bots can efficiently overcome CAPTCHAs with distorted textual content in nearly 100% of instances. Human accuracy in fixing CAPTCHAs varies from 50% to 84%. Moreover, it takes people as much as 15 seconds to resolve these duties, whereas bots can do it in lower than a second.
Based mostly on this research, researchers have come to an apparent conclusion: there is no such thing as a longer a easy method, primarily based on small photos or different options, to definitively distinguish people from bots. As an alternative, they suggest utilizing synthetic intelligence developments to develop “clever algorithms” that may extra successfully differentiate bot actions from human actions.
You may learn the complete analysis paper on the following hyperlink.


