
Giant language fashions (LLMs) are a big development in NLP. They’re designed to grasp, interpret, and generate human language. These fashions are skilled on enormous datasets and may carry out translation, summarization, and conversational responses. Regardless of their capabilities, a persistent problem is enhancing their capability to observe complicated directions precisely and reliably. This problem is essential as a result of exact instruction-following is key for sensible functions, from customer support bots to superior AI assistants.
A vital downside in enhancing LLMs’ instruction-following capabilities is the issue in robotically producing high-quality coaching knowledge with out handbook annotation. Conventional strategies contain human annotators designing directions and corresponding responses, which is time-consuming and tough to scale. Moreover, even superior fashions from which conduct is imitated could make errors, resulting in unreliable coaching knowledge. This limitation hampers the event of fashions that may execute complicated duties accurately, particularly in vital situations the place errors can have important penalties.
Present strategies to boost instruction-following talents embrace handbook annotation and conduct imitation. Handbook annotation requires in depth human effort to create various and sophisticated directions, which is difficult because of the limitations of human cognition. Habits imitation, however, entails coaching fashions to imitate the responses of extra superior LLMs. Nevertheless, this method restricts the brand new fashions to the capabilities of the supply fashions and doesn’t assure accuracy. Whereas highly effective, superior fashions like GPT-4 usually are not infallible, errors of their responses can propagate to new fashions, lowering their reliability.
Researchers from Alibaba Inc. have launched AUTOIF, a novel methodology designed to deal with these challenges by robotically producing instruction-following coaching knowledge. AUTOIF transforms the validation course of into code verification, requiring LLMs to create directions, corresponding code to verify response correctness, and unit check samples to confirm the code. This method leverages execution feedback-based rejection sampling to generate knowledge appropriate for Supervised Wonderful-Tuning (SFT) and Reinforcement Studying from Human Suggestions (RLHF). By automating these steps, AUTOIF eliminates the necessity for handbook annotation, making the method scalable and dependable.
The core concept of AUTOIF entails three essential elements: producing verifiable directions, creating verification codes, and guaranteeing reliability. The tactic begins with a small set of hand-written seed directions, augmented by LLMs to supply various directions. Verification codes and unit check circumstances are then generated for every instruction. If an instruction can’t be verified by code, it’s discarded. The method consists of producing responses that go or fail the verification code, that are then used to create coaching knowledge. This methodology ensures that solely high-quality knowledge is used for coaching, considerably enhancing the instruction-following capabilities of LLMs.
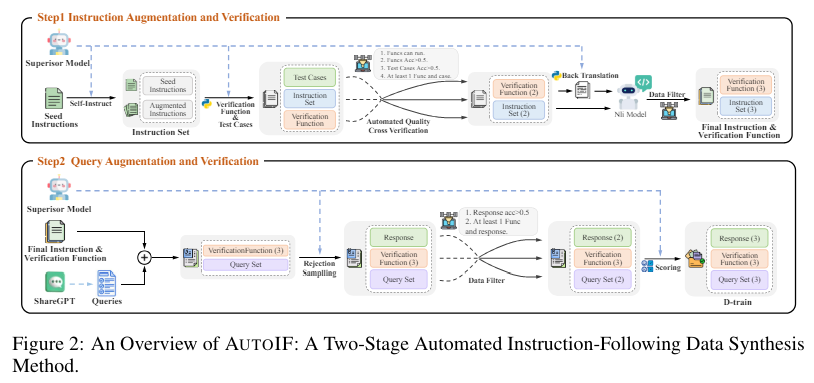
The efficiency of AUTOIF has been rigorously examined, exhibiting substantial enhancements throughout a number of benchmarks. Utilized to open-source LLMs like Qwen2-72B and LLaMA3-70B, AUTOIF achieved Unfastened Instruction accuracy charges of as much as 90.4% on the IFEval benchmark, marking the primary occasion of surpassing 90% accuracy. Within the FollowBench benchmark, the fashions confirmed important enhancements, with common will increase of over 5% within the SSR metric. Moreover, AUTOIF enabled Qwen2-7B and LLaMA3-8B to realize common efficiency features of over 4% in each benchmarks. Changing Qwen2-72B and LLaMA3-70B with GPT-4 resulted in additional enhancements. The researchers have additionally open-sourced the SFT and DPO datasets constructed utilizing AUTOIF on Qwen2-72B, representing the primary open-source complicated instruction-following dataset at a scale of tens of hundreds.

In conclusion, AUTOIF represents a big breakthrough in enhancing the instruction-following capabilities of huge language fashions. Automating the technology and verification of instruction-following knowledge addresses earlier strategies’ scalability and reliability points. This modern method ensures that fashions can precisely execute complicated duties, making them more practical and dependable in numerous functions. The in depth testing and notable enhancements in benchmarks spotlight AUTOIF’s potential to remodel the event of LLMs. Researchers have demonstrated that AUTOIF can obtain high-quality, scalable, and dependable instruction-following capabilities, paving the way in which for extra superior and sensible AI functions.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
Should you like our work, you’ll love our publication..
Don’t Overlook to hitch our 45k+ ML SubReddit
🚀 Create, edit, and increase tabular knowledge with the primary compound AI system, Gretel Navigator, now typically accessible! [Advertisement]
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.


