
Parameter-efficient fine-tuning (PEFT) strategies adapt massive language fashions (LLMs) to particular duties by modifying a small subset of parameters, not like Full Tremendous-Tuning (FFT), which updates all parameters. PEFT, exemplified by Low-Rank Adaptation (LoRA), considerably reduces reminiscence necessities by updating lower than 1% of parameters whereas attaining comparable efficiency to FFT. LoRA makes use of low-rank matrices to reinforce efficiency with out further computational prices throughout inference. Merging these matrices into authentic mannequin parameters avoids further inference prices. Quite a few strategies goal to enhance LoRA for LLMs, primarily validating effectivity through GLUE by attaining higher efficiency or requiring fewer trainable parameters.
Enhancements in LoRA embody DoRA’s decomposition method, LoRA+’s differential studying charges, and ReLoRA’s integration throughout coaching. Tremendous-tuning LLMs entails instruction tuning, advanced reasoning duties, and continuous pretraining. Most LoRA variants use instruction tuning or GLUE duties, which can not totally replicate effectiveness. Current works take a look at reasoning duties however typically want extra coaching information, limiting correct analysis.
Researchers from Beihang College and Microsoft Company launched MoRA. This strong methodology makes use of a sq. matrix as a substitute of low-rank matrices in LoRA to realize high-rank updating with the identical variety of trainable parameters. MoRA employs 4 non-parameter operators to regulate enter and output dimensions, guaranteeing the load could be merged again into LLMs. Complete analysis throughout 5 duties—instruction tuning, mathematical reasoning, continuous pretraining, reminiscence, and pretraining—demonstrates MoRA’s effectiveness.
MoRA goals to realize higher-rank updates with the identical variety of trainable parameters as LoRA by utilizing a sq. matrix. It introduces non-parameter operators to scale back the enter dimension and enhance the output dimension, guaranteeing the load can merge again into LLMs. A number of strategies implement these capabilities, similar to truncating dimensions, sharing rows and columns, and reshaping inputs. Incorporating rotation operators enhances the expressiveness of MoRA, distinguishing completely different enter segments and enhancing efficiency.
Researchers evaluated MoRA and introduced fine-tuning outcomes for MMLU in zero-shot and 5-shot settings for instruction tuning, GSM8K, and MATH for mathematical reasoning, and common efficiency on biomedical and monetary duties for continuous pretraining. MoRA performs equally to LoRA in instruction tuning and mathematical reasoning however outperforms LoRA in biomedical and monetary domains because of high-rank updating. LoRA variants usually exhibit comparable performances to LoRA, with AsyLoRA excelling in instruction tuning however struggling in mathematical reasoning. ReLoRA’s efficiency suffers at greater ranks, like 256, because of merging low-rank matrices throughout coaching. Every job demonstrates completely different fine-tuning necessities, the place rank 8 suffices for instruction tuning however fails for mathematical reasoning, necessitating a rank enhance to 256 for parity with FFT. In continuous pretraining, LoRA, with rank 256, nonetheless lags behind FFT.
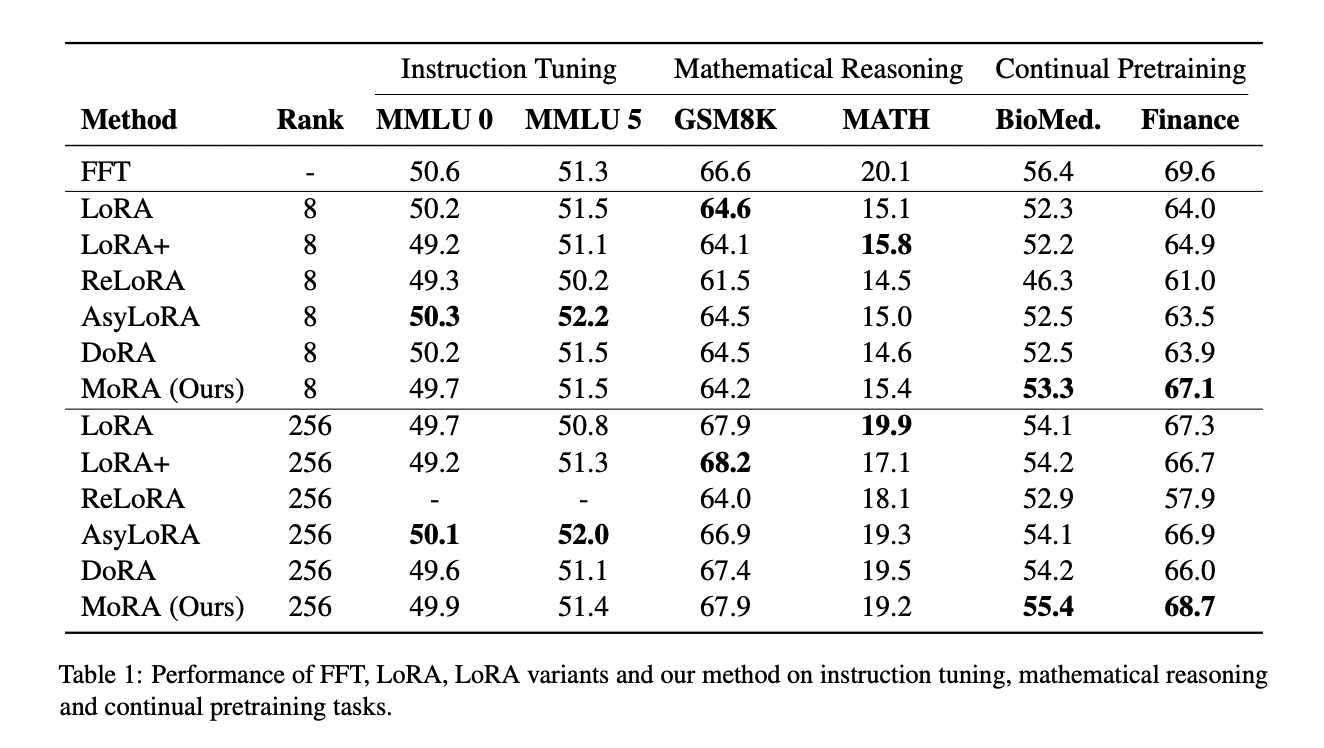
On this research, researchers analyze the restrictions of low-rank updating in LoRA for memory-intensive duties and suggest MoRA as an answer. MoRA makes use of non-parameterized operators for high-rank updating and explores completely different decompression and compression strategies. Efficiency comparisons present MoRA matching LoRA in instruction tuning and mathematical reasoning whereas outperforming it in continuous pretraining and reminiscence duties. Pretraining experiments additional validate the effectiveness of high-rank updating, demonstrating superior outcomes in comparison with ReLoRA.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s all the time researching the functions of machine studying in healthcare.


