Massive Language Fashions (LLMs), the most recent innovation of Synthetic Intelligence (AI), use deep studying methods to provide human-like textual content and carry out numerous Pure Language Processing (NLP) and Pure Language Technology (NLG) duties. Skilled on massive quantities of textual information, these fashions carry out numerous duties, together with producing significant responses to questions, textual content summarization, translations, text-to-text transformation, and code completion.
In latest analysis, a group of researchers has studied hallucination detection in grounded era duties with a particular emphasis on language fashions, particularly the decoder-only transformer fashions. Hallucination detection goals to establish whether or not the generated textual content is true to the enter immediate or accommodates false data.
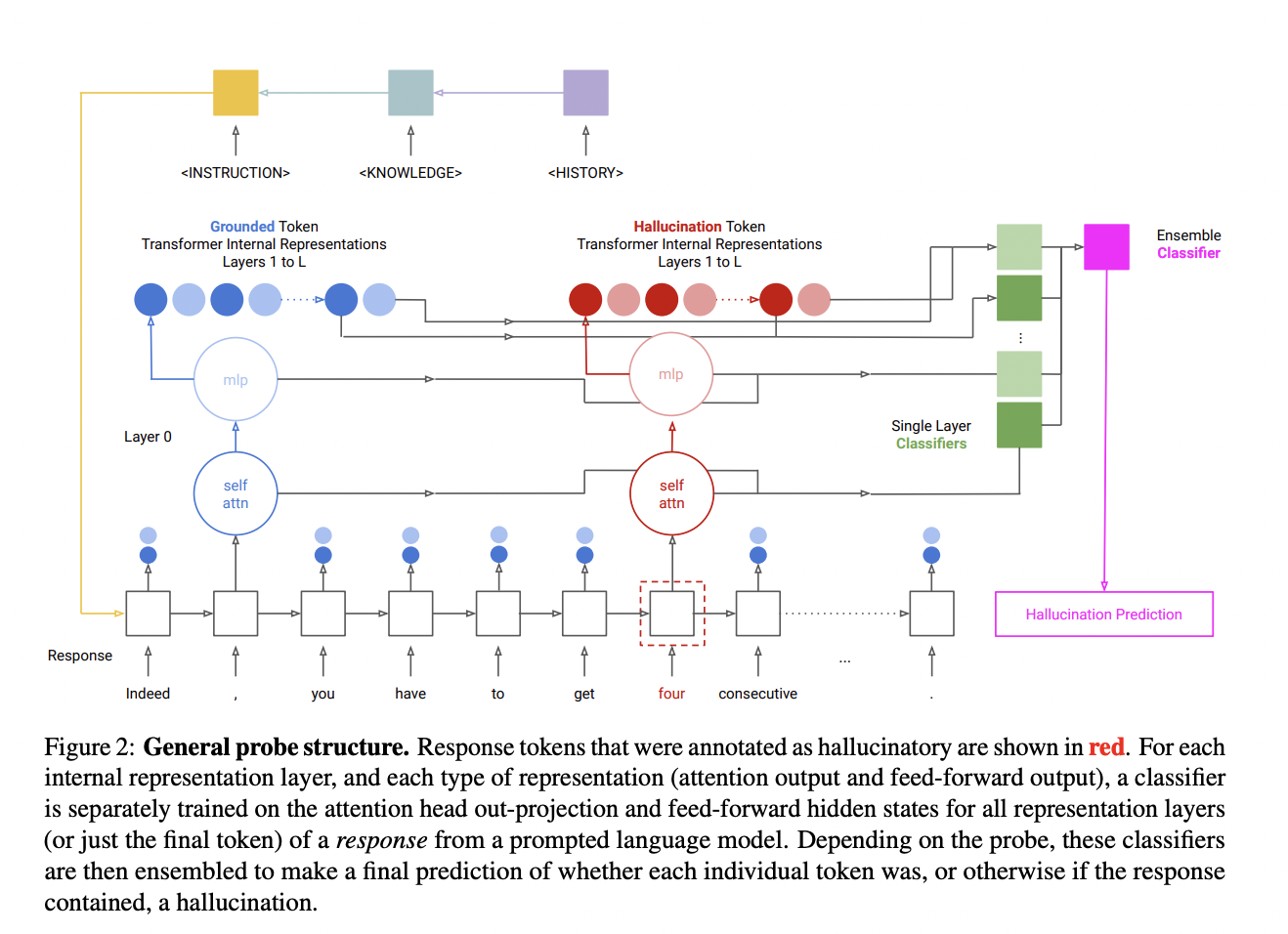
In latest analysis, a group of researchers from Microsoft and Columbia College has addressed the development of probes for the mannequin to anticipate a transformer language mannequin’s hallucinatory conduct throughout in-context creation duties. The principle focus has been on utilizing the mannequin’s inner representations for the detection and a dataset with annotations for each artificial and organic hallucinations.
Probes are principally the devices or programs educated on the language mannequin’s inner operations. Their job is to foretell when the mannequin may present delusional materials when doing duties involving the event of contextually acceptable content material. For coaching and assessing these probes, it’s crucial to offer a span-annotated dataset containing examples of artificial hallucinations, purposely induced disparities in reference inputs, and natural hallucinations derived from the mannequin’s personal outputs.
The analysis has proven that probes designed to determine force-decoded states of synthetic hallucinations usually are not very efficient at figuring out organic hallucinations. This exhibits that when educated on modified or artificial situations, the probes could not generalize nicely to real-world, naturally occurring hallucinations. The group has shared that the distribution properties and task-specific data impression the hallucination information within the mannequin’s hidden states.
The group has analyzed the intricacy of intrinsic and extrinsic hallucination saliency throughout numerous duties, hidden state varieties, and layers. The transformer’s inner representations emphasize extrinsic hallucinations- i.e., these linked to the surface world extra. Two strategies have been used to assemble hallucinations which embrace utilizing sampling replies produced by an LLM conditioned on inputs and introducing inconsistencies into reference inputs or outputs by modifying.
The outputs of the second method have been reported to elicit a better fee of hallucination annotations by human annotators; nevertheless, artificial examples are thought-about much less beneficial as a result of they don’t match the check distribution.
The group has summarized their main contributions as follows.
- A dataset with greater than 15,000 utterances has been produced which were tagged for hallucinations in each pure and synthetic output texts. The dataset covers three grounded era duties.
- Three probe architectures have been offered for the environment friendly detection of hallucinations, which reveal enhancements in effectivity and accuracy for detecting hallucinations over a number of present baselines.
- The examine has explored the weather that have an effect on the accuracy of the probe, equivalent to the character of the hallucinations, i.e., intrinsic vs. extrinsic, the dimensions of the mannequin, and the actual encoding elements which might be being probed.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to affix our 35k+ ML SubReddit, 41k+ Fb Group, Discord Channel, LinkedIn Group, and Electronic mail Publication, the place we share the most recent AI analysis information, cool AI tasks, and extra.
In case you like our work, you’ll love our e-newsletter..
Tanya Malhotra is a closing yr undergrad from the College of Petroleum & Vitality Research, Dehradun, pursuing BTech in Pc Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Knowledge Science fanatic with good analytical and important pondering, together with an ardent curiosity in buying new expertise, main teams, and managing work in an organized method.


