
As language fashions change into more and more superior, issues have arisen across the moral and authorized implications of coaching them on huge and numerous datasets. If the coaching knowledge will not be correctly understood, it might leak delicate data between the coaching and check datasets. This might expose personally identifiable data (PII), introduce unintended biases or behaviors, and in the end produce lower-quality fashions than anticipated. The shortage of complete data and documentation surrounding these fashions creates vital moral and authorized dangers that should be addressed.
A staff of researchers from varied establishments, together with MIT, Harvard Regulation Faculty, UC Irvine, MIT Heart for Constructive Communication, Inria, Univ. Lille Heart, Contextual AI, ML Commons, Olin School, Carnegie Mellon College, Tidelift, and Cohere For AI have demonstrated their dedication to selling transparency and accountable utilization of datasets by releasing a complete audit. The audit consists of Knowledge Provenance Explorer, an interactive person interface that permits practitioners to hint and filter knowledge provenance for broadly used open-source fine-tuning knowledge collections.
Copyright legal guidelines present authors unique possession of their work, whereas open-source licenses encourage collaboration in software program improvement. Nevertheless, supervised AI coaching knowledge presents distinctive challenges for open-source licenses in managing knowledge successfully. The interplay between copyright and permits inside collected datasets is but to be decided, with authorized challenges and uncertainties surrounding the applying of related legal guidelines to generative AI and supervised datasets. Earlier work has pressured the significance of information documentation and attribution, with Datasheets and different research highlighting the necessity for complete documentation and curation rationale for datasets.
The research carried out by researchers concerned handbook retrieval of pages and computerized extraction of licenses from HuggingFace configurations and GitHub pages. In addition they utilized the Semantic Scholar public API to retrieve tutorial publication launch dates and quotation counts. To make sure honest remedy throughout languages, the researchers used a sequence of information properties in characters, comparable to textual content metrics, dialog turns, and sequence size. As well as, they carried out a panorama evaluation to hint the lineage of over 1800 textual content datasets, analyzing their supply, creators, license circumstances, properties, and subsequent use. To facilitate the audit and tracing processes, they developed instruments and requirements to enhance dataset transparency and accountable use.
The panorama evaluation has revealed stark variations within the composition and focus of commercially obtainable open and closed datasets. The datasets which can be tough to entry dominate important classes comparable to decrease useful resource languages, extra artistic duties, wider matter selection, and newer and extra artificial coaching knowledge. The research has additionally highlighted the issue of misattribution and the inaccurate use of ceaselessly used datasets. On fashionable dataset internet hosting websites, licenses are ceaselessly miscategorized, and license omission charges exceed 70%, with error charges of over 50%. The research emphasizes the necessity for complete knowledge documentation and attribution. It additionally highlights the challenges of synthesizing documentation for fashions educated on a number of knowledge sources.
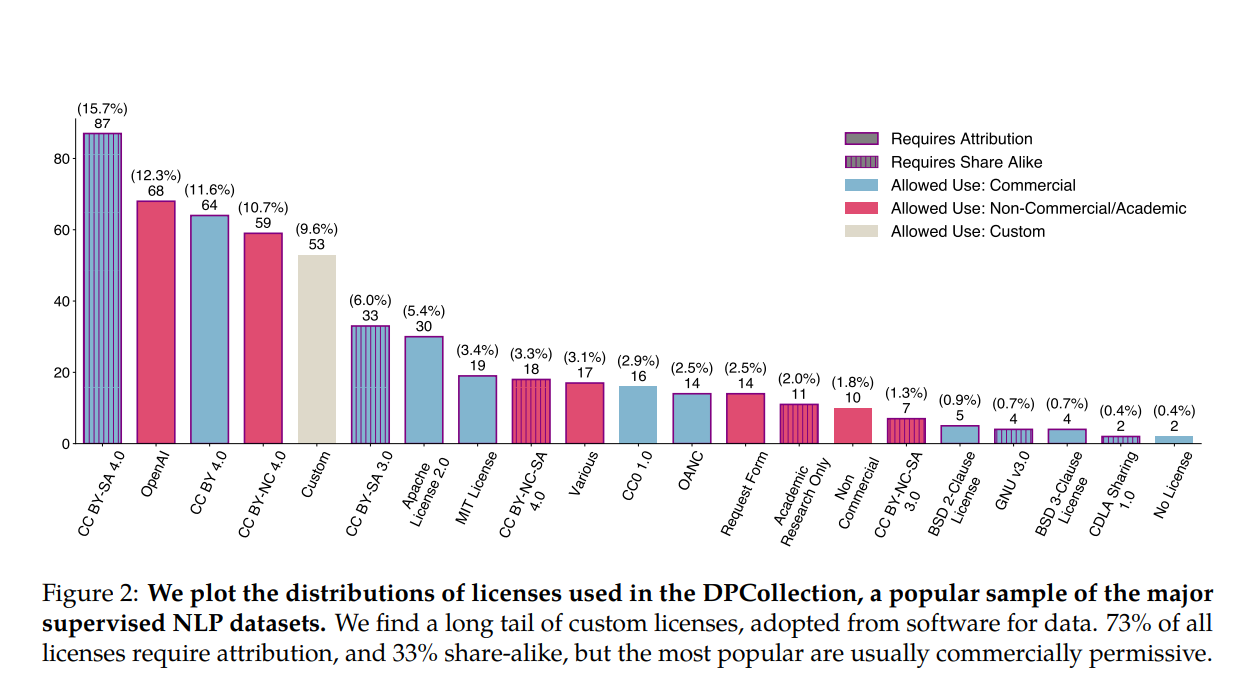
The research concludes that there are vital variations within the composition and focus of commercially open and closed datasets. Impenetrable datasets monopolize vital classes, indicating a deepening divide within the knowledge sorts obtainable below totally different license circumstances. The research discovered frequent miscategorization of licenses on dataset internet hosting websites and excessive charges of license omission. This factors to bother in misattribution and knowledgeable use of fashionable datasets, elevating issues about knowledge transparency and accountable use. The researchers launched their whole audit, together with the Knowledge Provenance Explorer, to contribute to ongoing enhancements in dataset transparency and dependable use. The panorama evaluation and instruments developed within the research purpose to enhance dataset transparency and understanding, addressing the authorized and moral dangers related to coaching language fashions on inconsistently documented datasets.
Take a look at the Paper and Venture. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to hitch our 35k+ ML SubReddit, 41k+ Fb Neighborhood, Discord Channel, and Electronic mail Publication, the place we share the newest AI analysis information, cool AI initiatives, and extra.
In the event you like our work, you’ll love our e-newsletter..
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.


