Welcome to our second AI in 5 submit, the place we educate you how one can create superb issues in simply 5 minutes! Should you missed the earlier one on coaching a classifier on high of an LLM, test it out right here. On this version, we’ll even be utilizing switch studying (a part of the 5 minute thought!) but additionally present how one can “deep practice” your individual fashions. Deep coaching is a slower course of than switch studying, so we’re primarily together with it right here for comparability.
You may obtain the dataset the tutorial is predicated on right here (supply: https://www.kaggle.com/datasets/alessiocorrado99/animals10)
We’ll stroll by way of a step-by-step tutorial on create and use datasets to coach numerous fashions, leverage bulk labeling, and use the analysis module to check fashions and select the one with the best take a look at efficiency. Our dataset will include photographs of 5 sorts of animals: horses, canines, elephants, sheep, and butterflies, and we will probably be utilizing Clarifai Portal.
Step 1: Create an utility
First, we create a brand new utility referred to as “Datasets Demo,” giving a quick description and navigating to the applying’s interface. We will see that we’re ranging from scratch, because it’s empty.
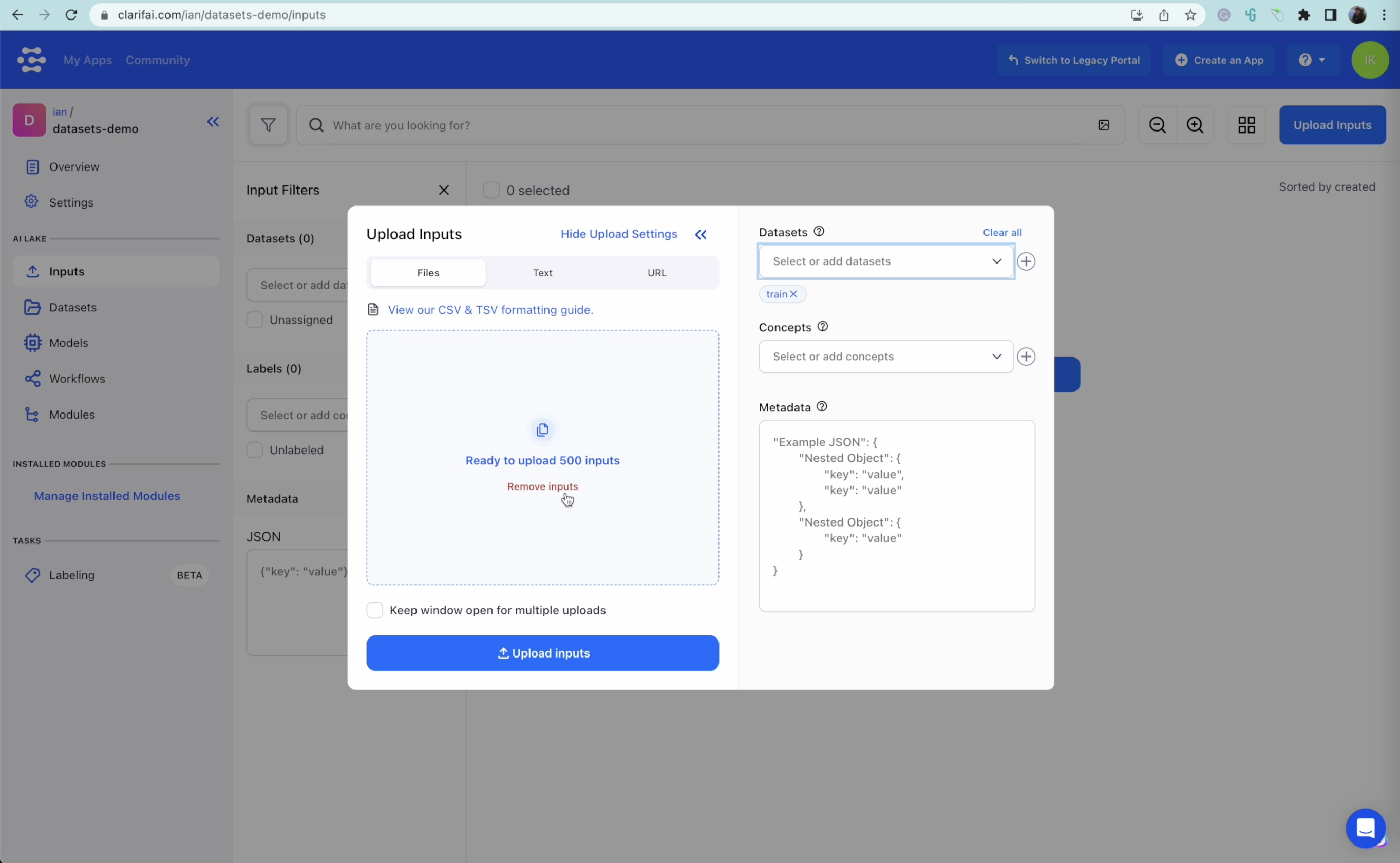
Step 2: Add photographs
We’ll add 700 footage of various animals – 500 for the coaching dataset, 100 for the validation dataset, and 100 for the take a look at dataset. Importing photographs can take a while, however as soon as executed, be sure that to test that every one the photographs have been uploaded efficiently.
Step 3: Perceive the aim of every dataset
When working with machine studying, it’s common to divide your dataset into three components: coaching, validation, and take a look at datasets. Every dataset serves a definite goal, and utilizing these three datasets helps stop overfitting and provides you a greater understanding of your mannequin’s efficiency.
Coaching dataset
The coaching dataset makes up essentially the most good portion of the information and is used to coach your mannequin. It’s fed into the machine studying algorithm, permitting the mannequin to be taught patterns, options, and relationships throughout the knowledge. Throughout this studying course of, the mannequin adjusts its inner parameters to reduce the prediction error or loss.
Validation dataset
The validation dataset is utilized through the mannequin choice and hyperparameter tuning course of. This dataset just isn’t used for studying, however to guage totally different variations of the mannequin (totally different hyperparameters, architectures, or coaching strategies) and assist select one of the best one. By evaluating the efficiency of fashions on the validation dataset, you keep away from overfitting the mannequin to the coaching knowledge, making certain a greater generalization to unseen knowledge.
It is very important observe that the validation dataset ought to be an unbiased pattern that is still separate from the coaching knowledge. Constantly fine-tuning a mannequin based mostly on the validation dataset may cause the mannequin to overfit the validation set, which reduces its generalizability to new knowledge.
Check dataset
The take a look at dataset is saved separate and is used to supply an unbiased evaluation of the chosen mannequin’s efficiency, simulating its real-world efficiency on new, unseen knowledge. This dataset ought to solely be used after you have finalized your mannequin, its hyperparameters, and coaching method. Evaluating the mannequin on the take a look at dataset gives an estimate of how properly the mannequin will really generalize when deployed in a real-world utility.
Dividing your knowledge into coaching, validation, and take a look at datasets helps you construct, fine-tune, and choose essentially the most applicable mannequin in your drawback with out inflicting overfitting or underfitting. The coaching dataset is used to be taught, the validation dataset is leveraged for evaluating totally different fashions to keep away from overfitting, and the take a look at dataset offers a last, unbiased estimate of the mannequin’s efficiency.
Step 4: Label the photographs utilizing the cross-modal perform
With the cross-modal perform out there on Clarifai Portal, we are able to sort in a selected time period and mechanically choose footage of the topic we’re on the lookout for. On this case, it will likely be animals equivalent to horses, canines, sheep, butterflies, and elephants. Rigorously scroll by way of the photographs and unselect any photographs that don’t belong to the class you might be looking. As soon as the photographs are chosen and sorted, label them accordingly. Make sure you double-check the underside photographs listed as a result of they’re often the least possible matches.
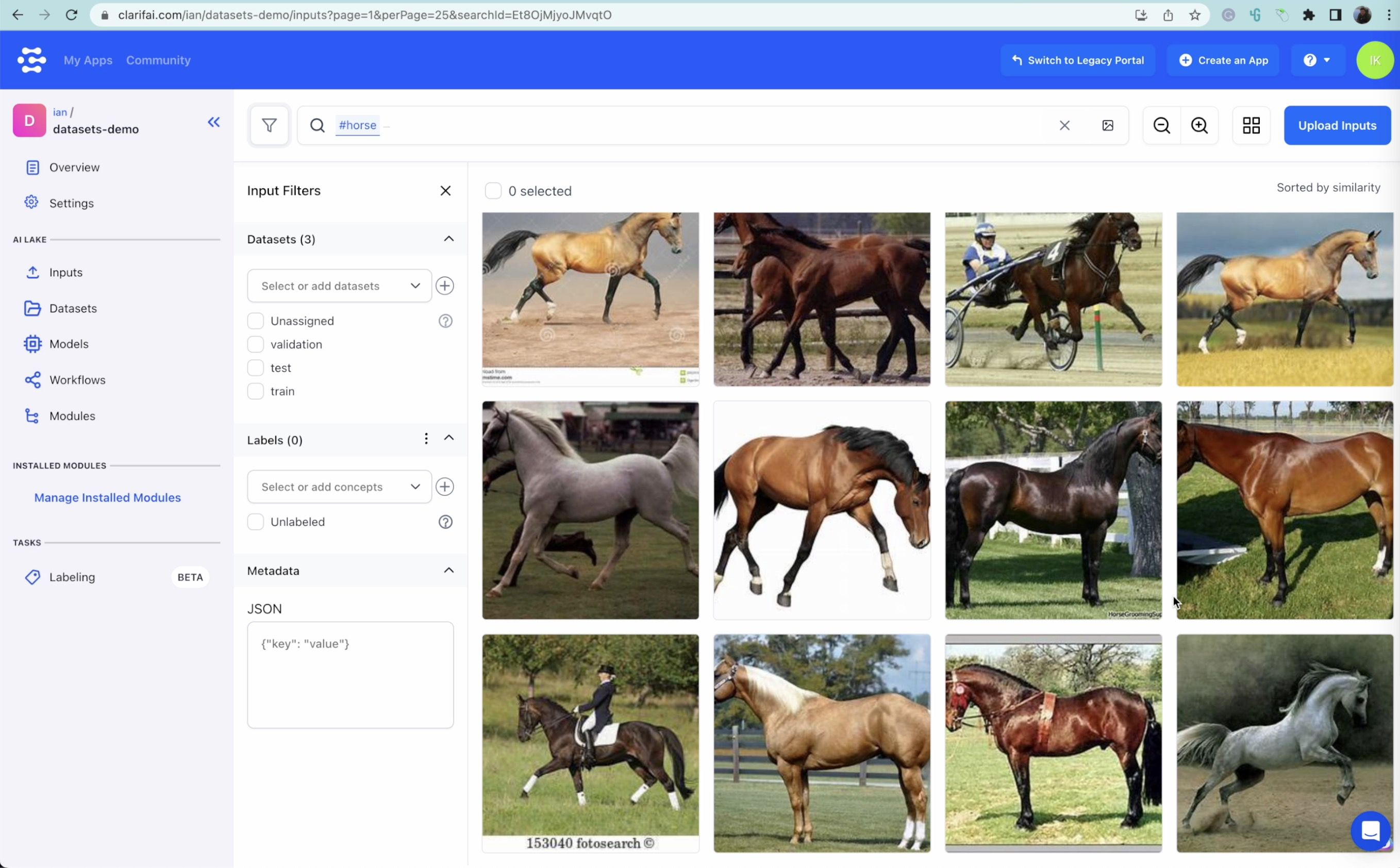
Outcomes of a cross-modal seek for the phrase “horse”
Step 5: Create ideas and label photographs in every class
Repeat the labeling course of for every animal class, together with fixing any labeling errors or eradicating pointless photographs from the dataset. As soon as all photographs have been sorted and labeled, you’ll have a categorized dataset that’s partitioned into coaching, validation, and take a look at datasets, prepared for modeling.
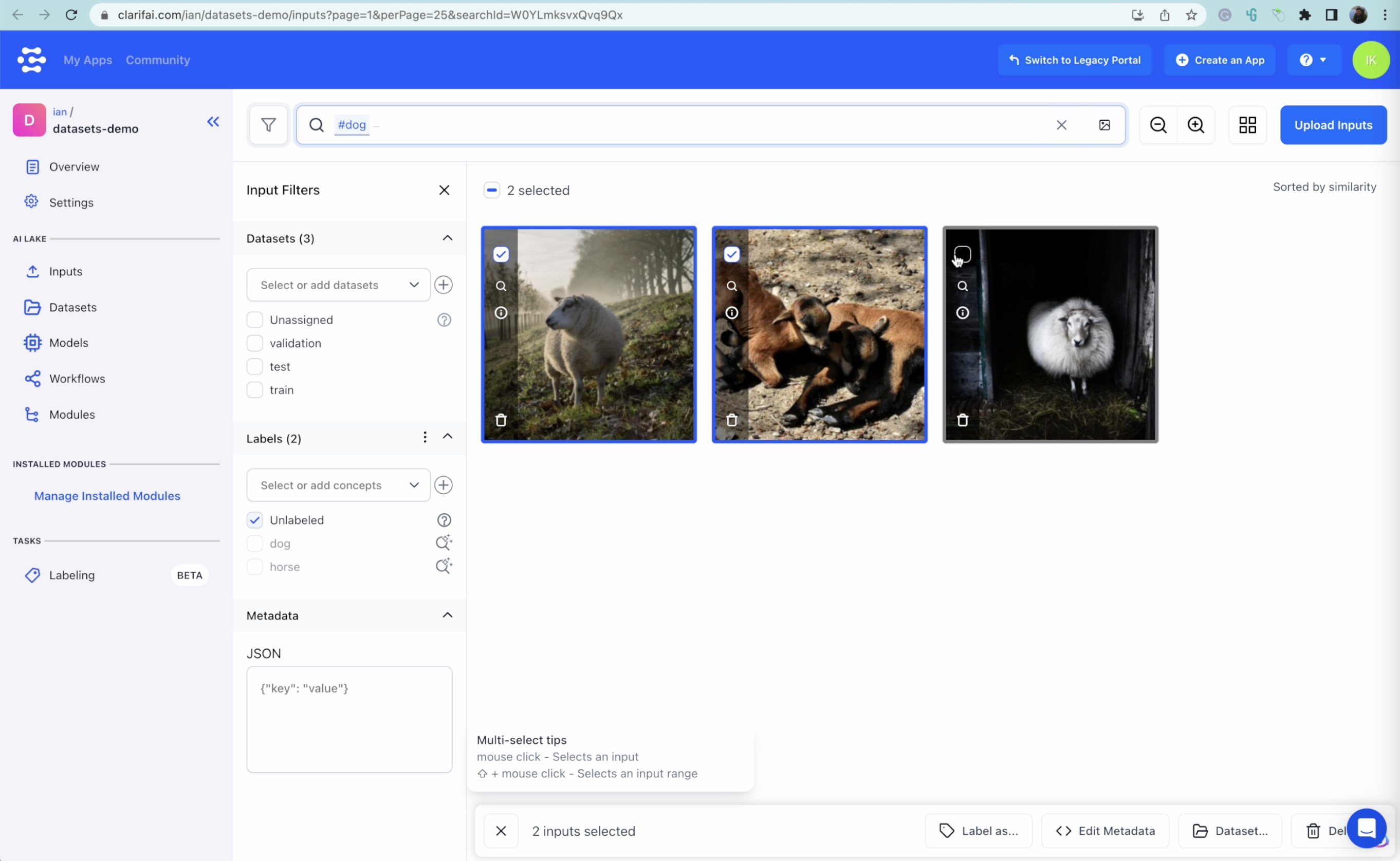
We will clearly see these are sheep by accident detected as canines by the visible search, so we are able to repair them manually.
Step 6: Prepare the fashions
For this tutorial, we’ll practice three totally different fashions:
1. Switch Studying – Custom-made InceptionV2
On this tutorial, switch studying is carried out utilizing a personalized InceptionV2 structure. InceptionV2 is a refined model of the traditional Inception mannequin, which primarily focuses on the scalability of deep studying architectures and environment friendly parameter utilization. This mannequin offers a powerful basis for transferring the information of recognizing widespread objects and numerous ideas in photographs to our animal classification drawback.
Switch studying is a method that leverages the information gained from a pre-trained mannequin to facilitate the training strategy of a brand new mannequin for a associated drawback. This method accelerates the coaching course of and sometimes improves efficiency as a result of the pre-trained mannequin has already discovered invaluable options and patterns from giant datasets, enabling the brand new mannequin to begin with a powerful characteristic set.
In our case, when utilizing Switch studying, we take a mannequin that was educated on the same job (e.g., object recognition in photographs) and fine-tune it to acknowledge our particular lessons of animals. The perfect a part of switch studying is that it occurs in seconds, not minutes or hours.
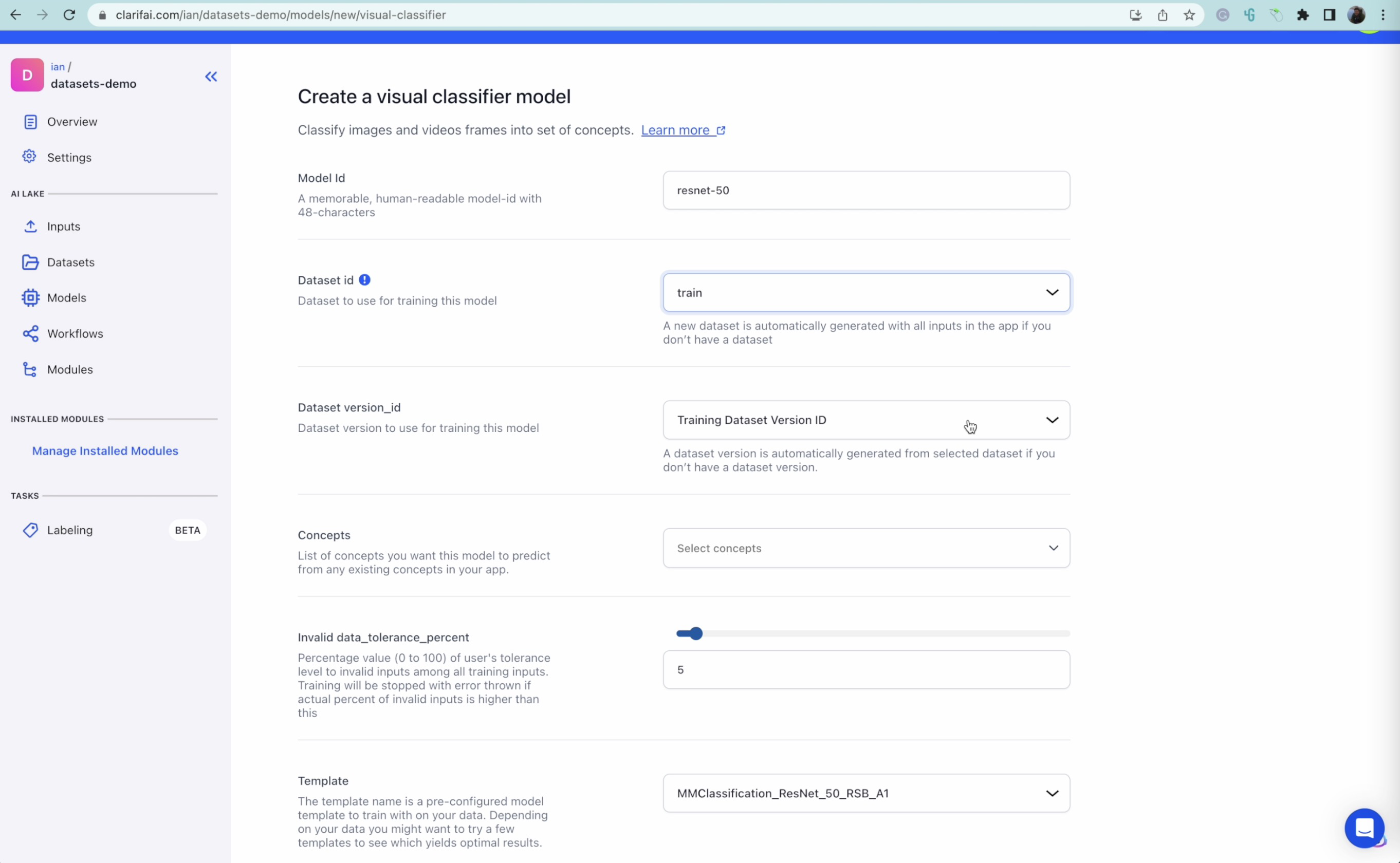
2. Deep studying – ResNet 50
ResNet 50, brief for Residual Community with 50 layers, is a well-liked and extensively used Deep Studying mannequin for pc imaginative and prescient duties. It’s a sort of Convolutional Neural Community (CNN) recognized for its residual connections, which assist overcome the degradation drawback in deep networks, enabling coaching of deeper fashions and bettering accuracy.
ResNet 50 is able to dealing with large-scale picture classification duties, however it usually requires extra coaching time in comparison with switch studying as a result of it must be taught the options and patterns from scratch. In our tutorial, we practice a ResNet 50 mannequin from scratch utilizing our labeled dataset of animal photographs.
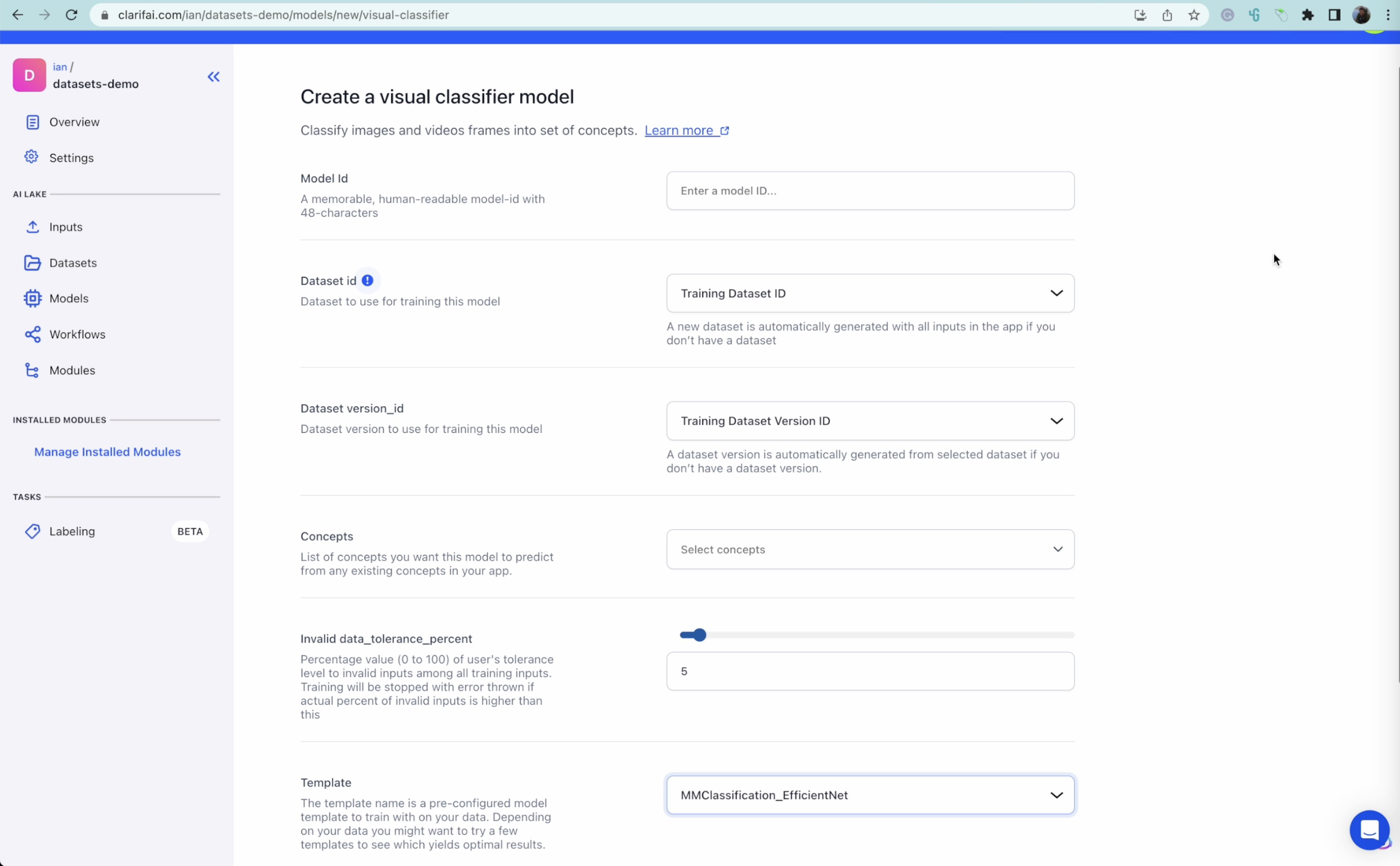
3. Deep studying – EfficientNet
EfficientNet is one other Deep Studying mannequin designed particularly for pc imaginative and prescient duties. It focuses on bettering the effectivity of Convolutional Neural Networks through the use of a brand new scaling methodology referred to as “compound scaling.” This method scales the width, depth, and backbone of the neural community concurrently whereas optimizing for each efficiency and computational value.
EfficientNet has a number of variants, with every model offering a trade-off between mannequin measurement, pace, and efficiency. Like ResNet 50, when utilizing EfficientNet in our tutorial, we practice the mannequin from scratch on our dataset of labeled animal photographs.
Every of the three fashions serves totally different functions and might present distinctive insights into the dataset. By coaching and evaluating the efficiency of those fashions in our tutorial, we are able to finally choose essentially the most correct and environment friendly mannequin for our animal recognition job.
Step 7: Check mannequin efficiency on coaching knowledge
Consider every mannequin’s efficiency on the coaching dataset to see how properly they’ve been educated. The analysis metrics will assist to find out every mannequin’s accuracy.
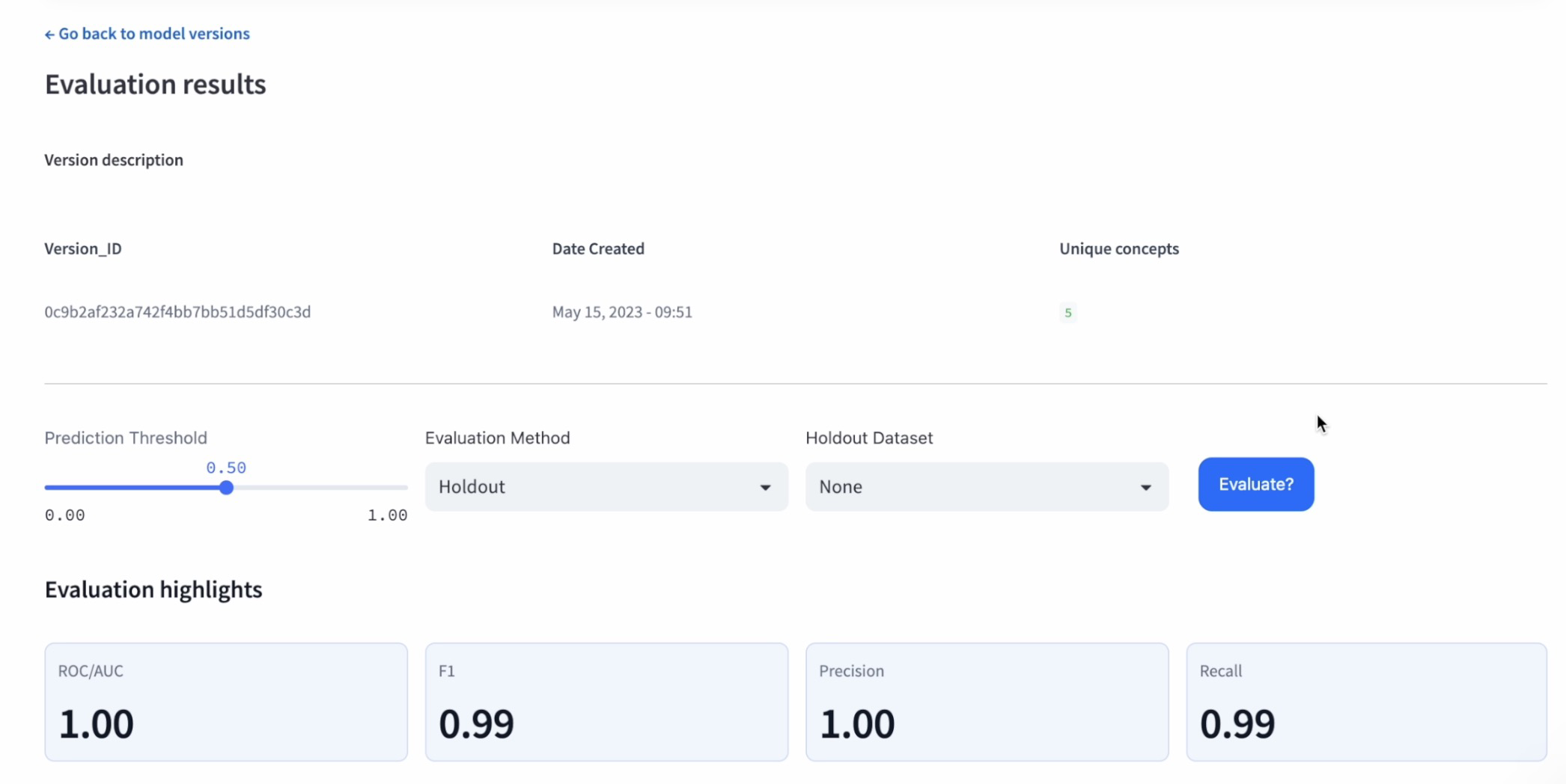
Step 8: Consider mannequin efficiency on validation knowledge
Consider the fashions on the validation dataset to find out their real-world efficiency. The efficiency on the validation dataset will enable you to select the best-suited mannequin in your use case.
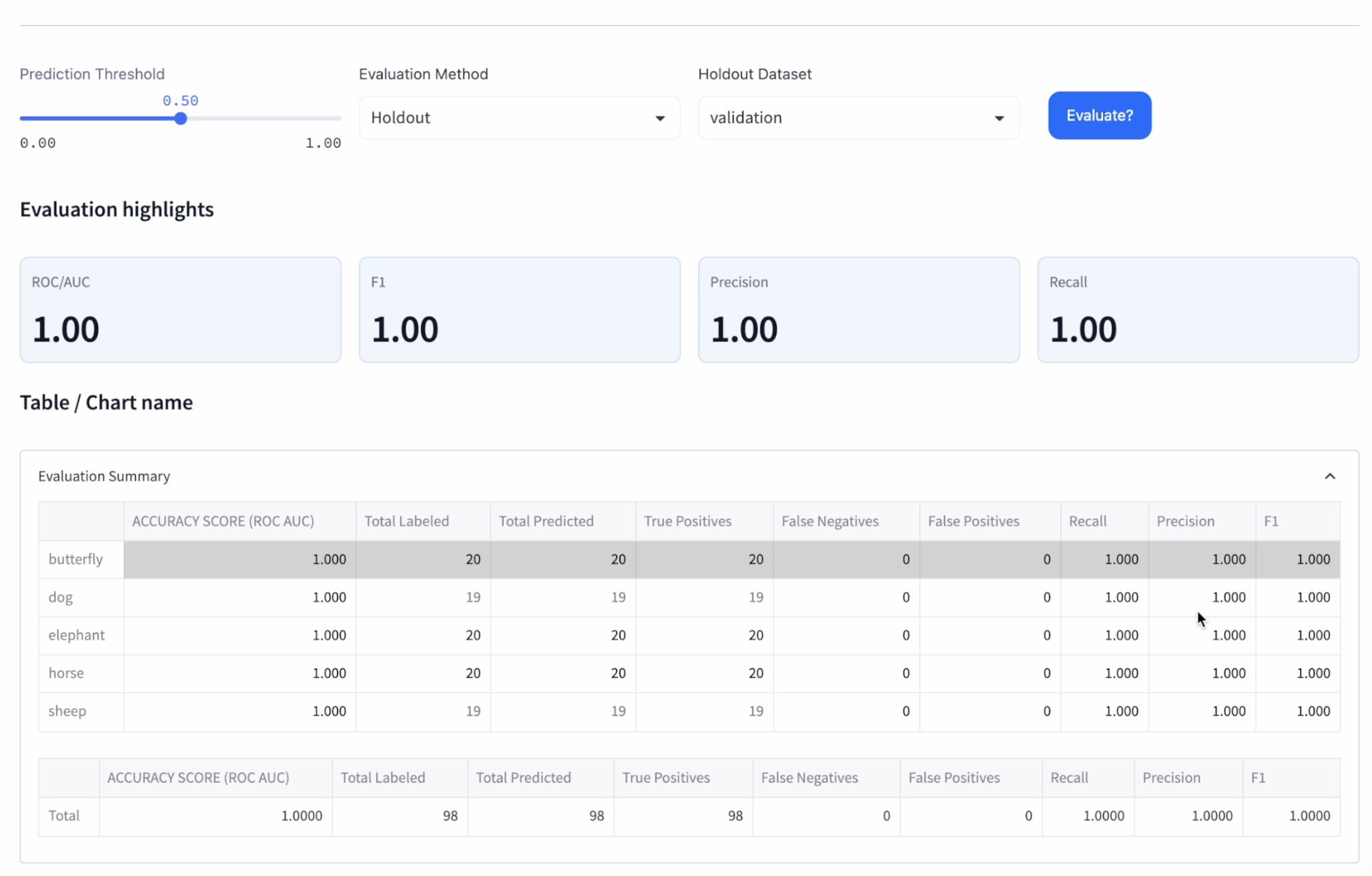
Step 9: Examine mannequin efficiency utilizing confusion matrices
A confusion matrix is a extensively used instrument for visualizing and evaluating the efficiency of a classification mannequin. It helps quantitatively outline the successes and failures of the mannequin and offers invaluable insights into mannequin conduct. By analyzing confusion matrices, we are able to assess the standard and confidence ranges of every mannequin associated to their predictions and examine their efficiency.
In a confusion matrix, every row represents the precise class (floor reality), whereas every column represents the expected class (mannequin output). The diagonals of the matrix comprise the right predictions made by the mannequin, whereas the off-diagonal cells comprise the inaccurate predictions. Listed here are a pair causes to take a look at your fashions’ confusion matrices:
1. Quantitative analysis of mannequin efficiency: The confusion matrix offers an in depth comparability of the mannequin’s predictions versus the precise labels of the dataset. It helps establish the variety of appropriate and incorrect predictions for every class, in addition to potential sources of error or confusion between lessons.
2. Confidence ranges: The numbers within the matrix’s diagonal cells symbolize the mannequin’s appropriate predictions. By evaluating these values with the entire variety of predictions for every class, we are able to gauge the mannequin’s confidence ranges. Ideally, we wish the values within the diagonal to be as shut to at least one as doable and the opposite cells to be as near zero as doable, indicating excessive confidence within the mannequin’s predictions.
3. Identification of mannequin weaknesses: We will establish patterns of misclassification, which highlights areas the place the mannequin is likely to be struggling or requires enchancment. As an example, suppose the mannequin constantly confuses two lessons, leading to excessive off-diagonal values. In that case, we might have to deal with the problem by fine-tuning the mannequin, augmenting the coaching knowledge, or selecting a unique structure appropriate for the issue at hand.
4. Mannequin comparability: When evaluating a number of fashions, we are able to decide which mannequin has one of the best efficiency and highest confidence ranges and choose it for our particular job.
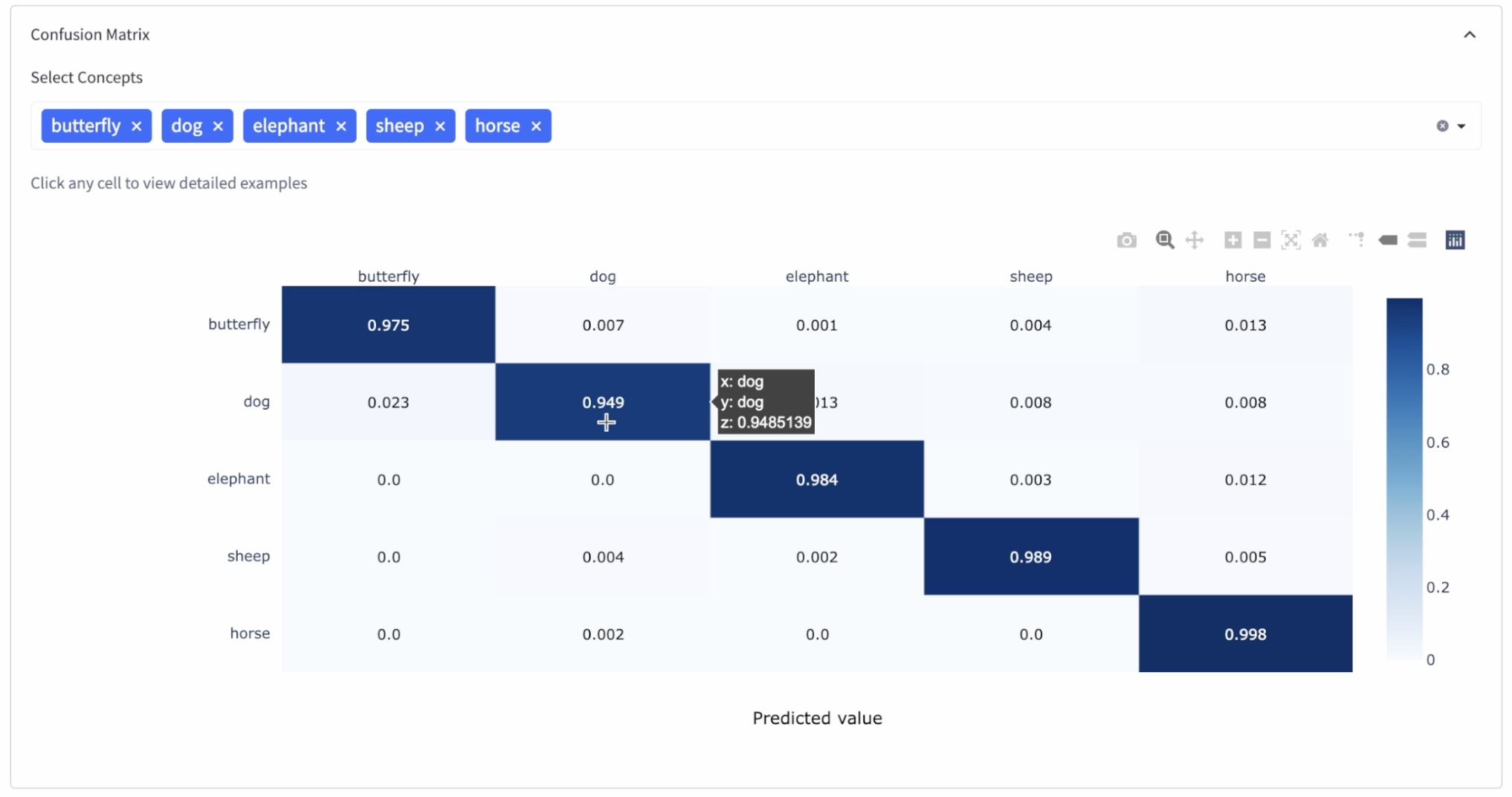
Step 10: Choose the best-performing mannequin
Based mostly on their efficiency on the validation dataset and the confusion matrix, select the mannequin with the best accuracy and confidence ranges. In our case, the Switch Be taught mannequin proved to be one of the best.
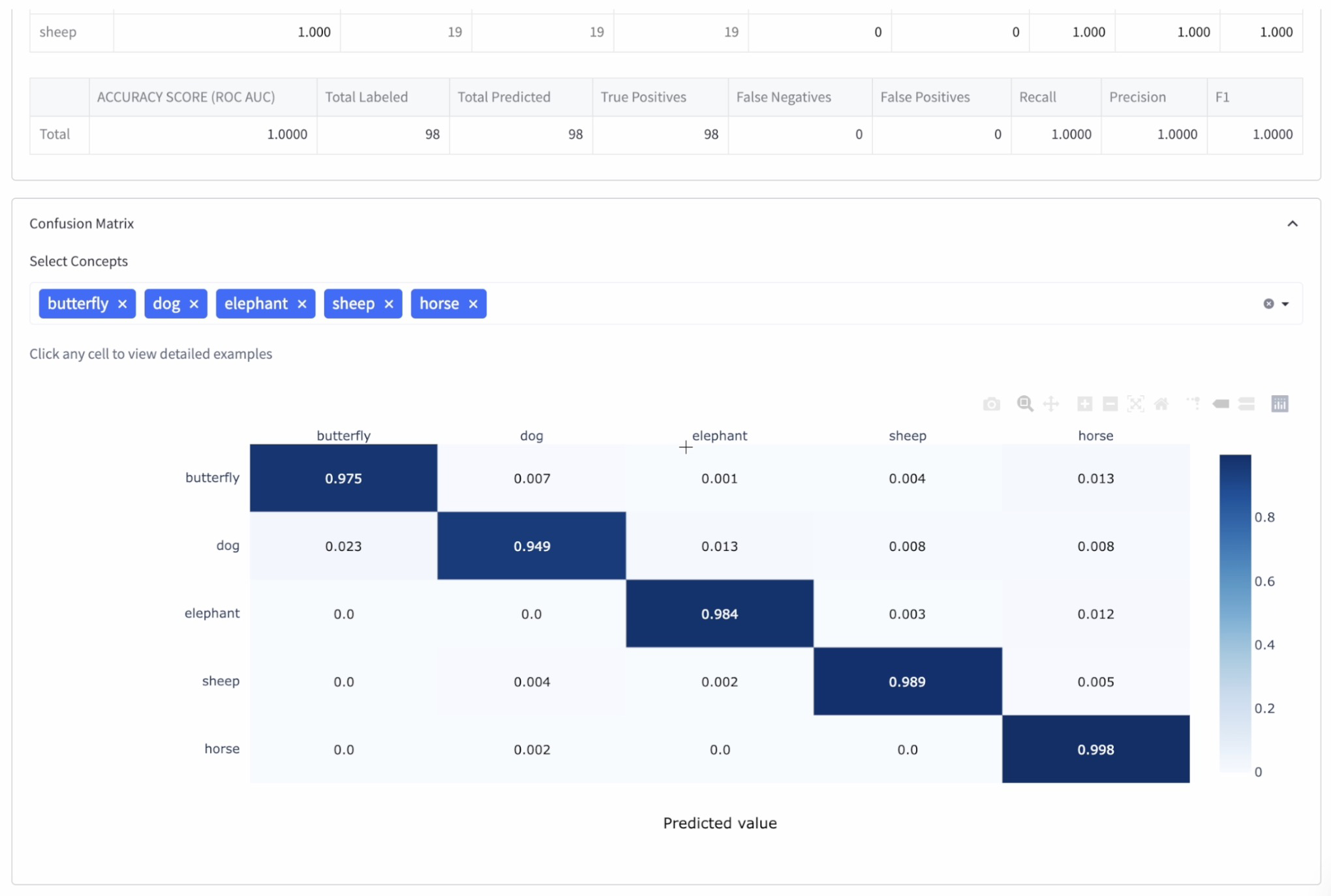
Step 11: Consider the chosen mannequin on the take a look at dataset
Upon getting chosen one of the best mannequin, carry out a last analysis on the take a look at dataset to get a way of its real-world efficiency. This analysis offers you an thought of how properly the mannequin will carry out in sensible use.
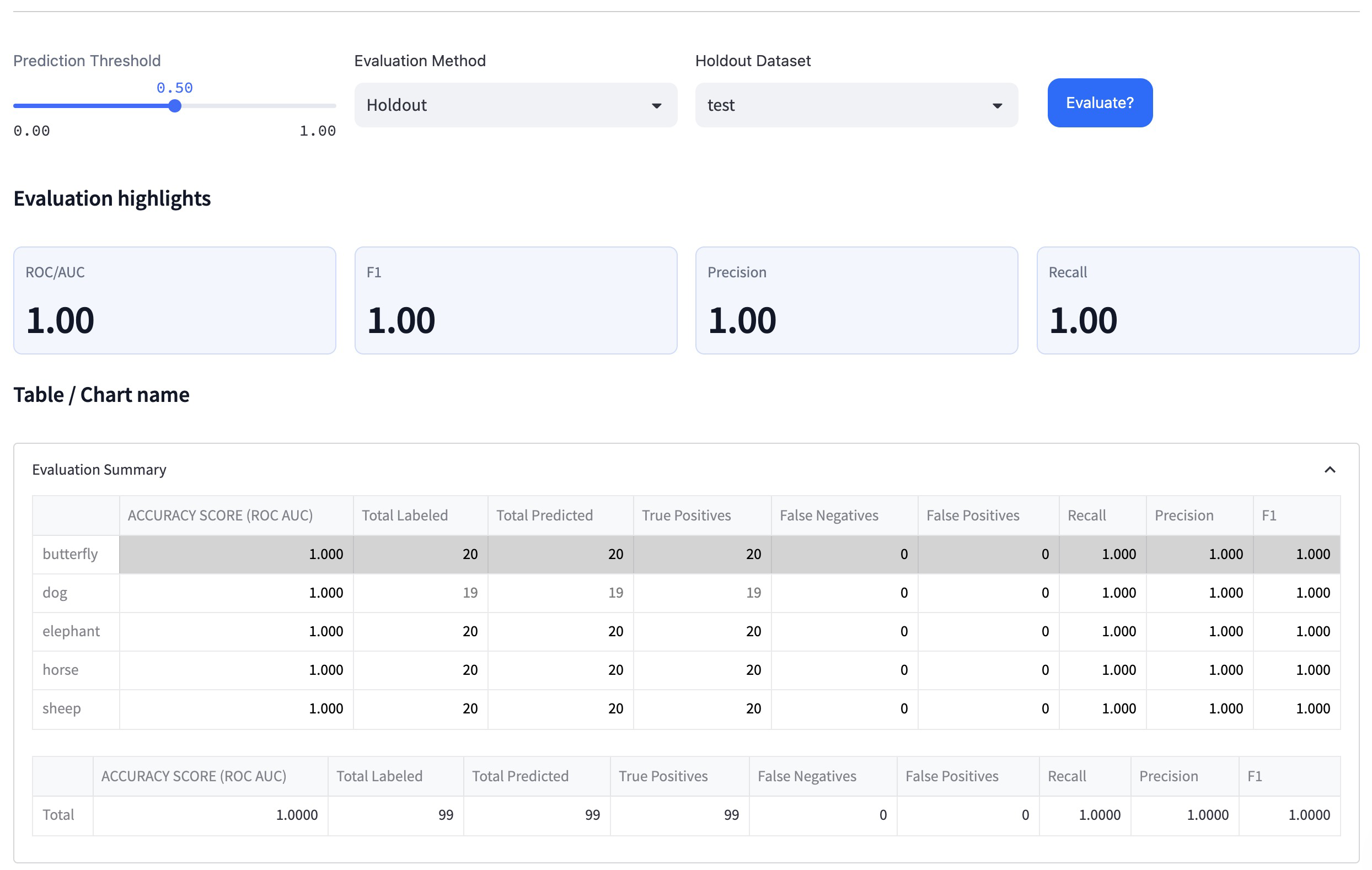
Step 12: Analyze the ultimate outcomes
Look at the efficiency metrics, accuracy, and confusion matrix of the best-performing mannequin on the take a look at dataset. In our case, the Switch Be taught mannequin achieved 100% accuracy and excessive confidence ranges on the take a look at dataset.
By following this tutorial, you must now have efficiently educated a number of fashions utilizing a dataset of animal photographs, bulk-labeled the photographs, and used the analysis module to check the fashions and choose the one with the best take a look at efficiency.
Do not forget that every use case may go higher with totally different fashions, so it’s all the time a good suggestion to check numerous fashions and examine their efficiency as demonstrated on this tutorial. This course of will assist guarantee that you’re utilizing essentially the most correct and environment friendly mannequin in your particular wants.


