
Imaginative and prescient-language fashions (VLMs) are gaining prominence in synthetic intelligence for his or her means to combine visible and textual knowledge. These fashions play an important function in fields like video understanding, human-computer interplay, and multimedia purposes, providing instruments to reply questions, generate captions, and improve decision-making primarily based on video inputs. The demand for environment friendly video-processing techniques is rising as video-based duties proliferate throughout industries, from autonomous techniques to leisure and medical purposes. Regardless of advances, dealing with the huge quantity of visible data in movies stays a core problem in creating scalable and environment friendly VLMs.
A vital problem in video understanding is that current fashions typically depend on processing every video body individually, producing 1000’s of visible tokens. This course of consumes in depth computational sources and time, limiting the mannequin’s means to effectively deal with lengthy or advanced movies. The problem is decreasing the computational load whereas capturing related visible and temporal particulars. With out a resolution, duties requiring real-time or large-scale video processing change into impractical, creating a necessity for revolutionary approaches that stability effectivity and accuracy.
Present options try to scale back the variety of visible tokens by means of strategies reminiscent of pooling throughout frames. Fashions like Video-ChatGPT and Video-LLaVA give attention to spatial and temporal pooling mechanisms to condense frame-level data into smaller tokens. Nonetheless, these strategies nonetheless generate many tokens, with fashions like MiniGPT4-Video and LLaVA-OneVision producing 1000’s of tokens, resulting in inefficient dealing with of longer movies. These fashions typically need assistance to optimize token effectivity and video processing efficiency, necessitating simpler options to streamline token administration.
In response, researchers from Salesforce AI Analysis launched BLIP-3-Video, a sophisticated VLM particularly designed to deal with the inefficiencies in video processing. The mannequin incorporates a “temporal encoder” that dramatically reduces the visible tokens required to symbolize a video. By limiting the token depend to as few as 16 to 32 tokens, the mannequin considerably improves computational effectivity with out sacrificing efficiency. This breakthrough permits BLIP-3-Video to carry out video-based duties with a lot decrease computational prices, making it a groundbreaking step towards scalable video understanding options.

The temporal encoder in BLIP-3-Video is central to its means to course of movies extra effectively. It employs a learnable spatio-temporal attentional pooling mechanism that extracts solely essentially the most informative tokens throughout video frames. The system consolidates spatial and temporal knowledge from every body, remodeling them right into a compact set of video-level tokens. The mannequin features a imaginative and prescient encoder, a frame-level tokenizer, and an autoregressive language mannequin that generates textual content or solutions primarily based on video enter. The temporal encoder makes use of sequential fashions and a spotlight mechanisms to retain the video’s core data whereas decreasing redundant knowledge, making certain that BLIP-3-Video can deal with advanced video duties effectively.
Efficiency outcomes reveal BLIP-3-Video’s superior effectivity in comparison with bigger fashions. The mannequin achieves video question-answering (QA) accuracy much like state-of-the-art fashions, reminiscent of Tarsier-34B, whereas utilizing a mere fraction of the visible tokens. For example, Tarsier-34B makes use of 4608 tokens for 8 video frames, whereas BLIP-3-Video reduces this quantity to simply 32 tokens. Regardless of this discount, BLIP-3-Video nonetheless maintains sturdy efficiency, attaining a rating of 77.7% on the MSVD-QA benchmark and 60.0% on the MSRVTT-QA benchmark, each of that are broadly used datasets for evaluating video-based question-answering duties. These outcomes underscore the mannequin’s means to retain excessive ranges of accuracy whereas working with fewer sources.
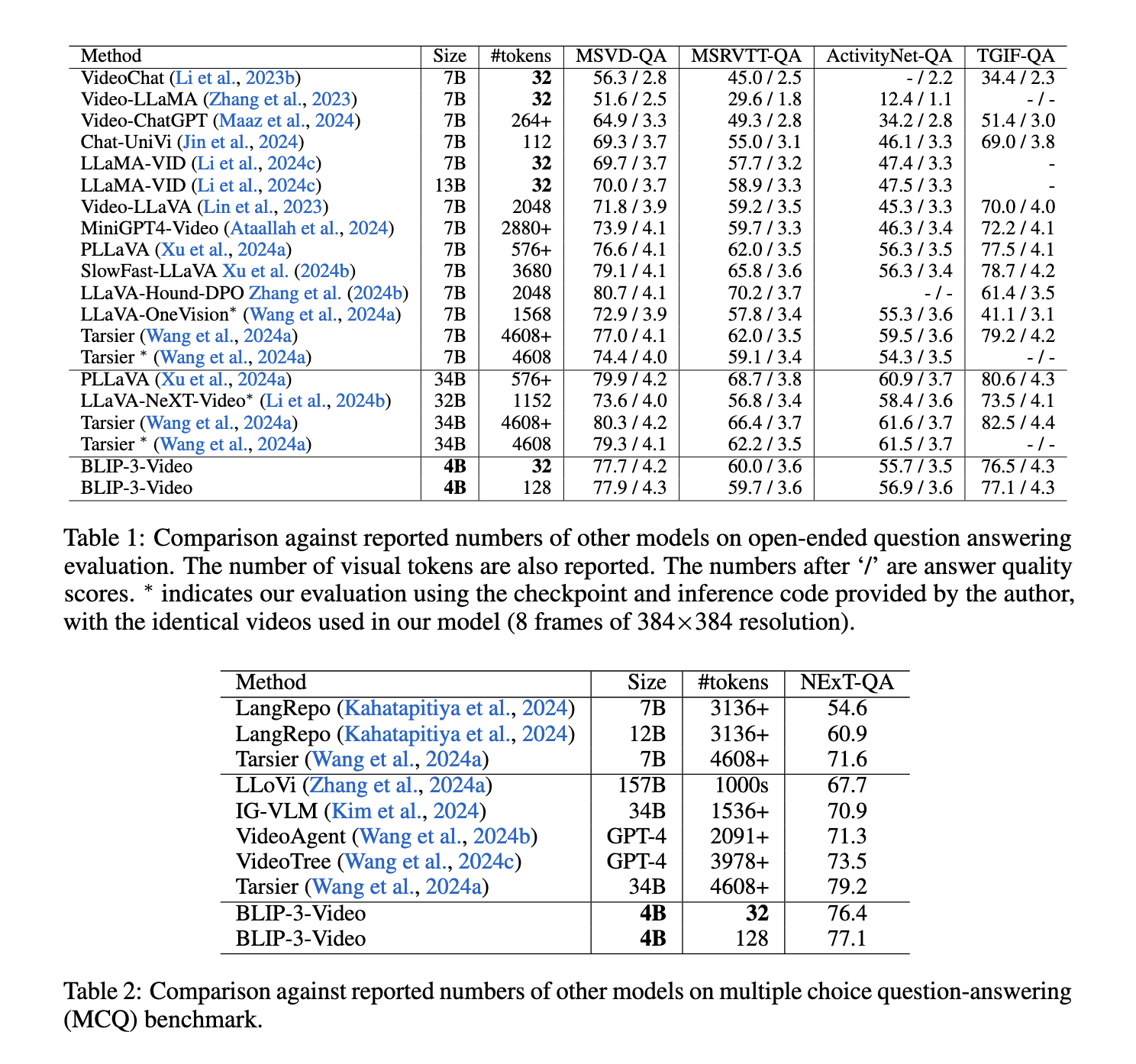
The mannequin carried out exceptionally properly on multiple-choice question-answering duties, such because the NExT-QA dataset, scoring 77.1%. That is significantly noteworthy on condition that it used solely 32 tokens per video, considerably fewer than many competing fashions. Moreover, on the TGIF-QA dataset, which requires understanding dynamic actions and transitions in movies, the mannequin achieved a formidable 77.1% accuracy, additional highlighting its effectivity in dealing with advanced video queries. These outcomes set up BLIP-3-Video as probably the most token-efficient fashions obtainable, offering comparable or superior accuracy to a lot bigger fashions whereas dramatically decreasing computational overhead.

In conclusion, BLIP-3-Video addresses the problem of token inefficiency in video processing by introducing an revolutionary temporal encoder that reduces the variety of visible tokens whereas sustaining excessive efficiency. Developed by Salesforce AI Analysis, the mannequin demonstrates that processing advanced video knowledge with far fewer tokens than beforehand thought mandatory is feasible, providing a extra scalable and environment friendly resolution for video understanding duties. This development represents a big step ahead in vision-language fashions, paving the best way for extra sensible purposes of AI in video-based techniques throughout numerous industries.
Try the Paper and Undertaking. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Greatest Platform for Serving Advantageous-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.


